
Android 系统中的文字渲染~
一种使用OpenGL渲染文字的常用方法,是计算出一个包含了显示文字的纹理图片,这通常是使用相当复杂的打包算法来最小化纹理中的冗余部分,在创建这样的图片之前必须清楚应用运行时使用的字体,包括了字体形状,尺寸和其他的一些属性。
在Android上,提前生成文字纹理图片是不太实际的,因为没有方法提前知道应用使用了哪些字体和字形,应用甚至可以在运行时加载自定义字体,这是许多限制因素中的主要一个,Android字体渲染必须实现下面的工作:
必须可以在运行时创建字体缓存 必须能够处理大量的字体 必须能够处理大量的字形 最小化纹理的浪费 速度必须快 在低端和高端设备上都运行的很快 在任何的驱动/GPU组合上正常运行
实现文字渲染
在我们查看低级别的OpenGL字体渲染是如何工作之前,我们先从应用直接使用的高级别API开始,这些API对于理解libhwui的工作是非常重要的。
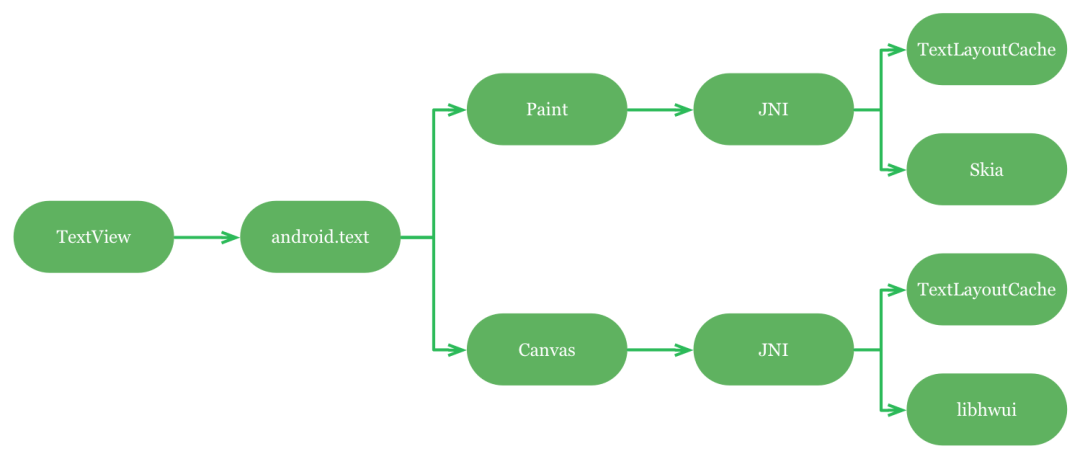
Text APIs 应用主要使用下面的四个API来布局和绘制文字:
android.widget.TextView 一个用来处理布局和渲染的view android.text.* 创建格式化的文字和布局的类集合 android.graphics.Paint 用来测量文字(to measure text) android.graphics.Canvas 用来渲染文字(to render text)
TextView和android.text是在Paint和Canvas上面的高级别实现。
直到Android 3.0,Paint和Canvas是直接在Skia上面实现的,Skia是一个软件渲染库,它提供了一个非常好的Freetype(非常流行的文字光栅化开源代码)抽象。

到了4.4过程变得更加复杂了,Paint和Canvas使用内部的JNI接口TextLayoutCache来处理复杂文字的layout,这个API依赖于Harfbuzz(一个开源的文字成型引擎),TextLayoutCache的输入是一个font和一个Java UTF-16的string,输出是包含x,y位置的字形标识符列表。
TextLayoutCache是正确支持许多非拉丁语言的关键,比如阿拉伯语、希伯来语、泰语等。绘制文字比简单的从左到右一个接一个的放置文字复杂的多,一些语言比如阿拉伯语,是从右到左的,泰语甚至需要文字被放置到前一个文字的上面或者下面。
这意味这当你调用Canvas.drawText()方法时,openGL渲染引擎不会直接或者间接的接收到你发送的参数,但是会收到字形标识符数组和x/y位置数组。
光栅化与缓存
字体渲染的每一次draw调用都是和一个单独的font关联的,font是用来缓存各个字形,字形反过来被存储在一个缓存结构中(cache texture),这个缓存结构可以用来包含多种字体的字形。
cache texture是一个非常重要的对象,它有多种缓存:空闲块列表,像素缓存,OpenGL纹理句柄,顶点缓存(the mesh,网格,构成图形的基本单位)。
用来存储这些对象的数据结构是相当简单的:
Fonts被存储在font渲染器的LRU缓存中 字形(Glyphs)被存储在每一个font的map中,key是字形标识符 Cache textures(缓存结构)跟踪链表块的空闲位置 像素缓存是uint8_t或者uint_32t的数组(alpha和RGBA的缓存) mesh是有两个属性的顶点缓存:x/y位置和u/v坐标 texture是一个GLuint类型的句柄
当字体渲染器初始化的时候,它创建了两种类型的cache textures:alpha和RGBA。Alpha textures用来存储正常的字形,因为字体不包含颜色信息,我们只需要存储抗锯齿信息。RGBA缓存被用来存储表情符号。
对每一种类型的cache texture,字体渲染器创建一些不同尺寸大小的CacheTexture实例,根据设备的不同缓存的大小也不同,下面是一些默认的尺寸:
1024x512 alpha cache 2048x256 alpha cache 2048x256 alpha cache 2048x512 alpha cache 1024x512 RGBA cache 2048x256 RGBA cache
当一个CacheTexture被创建的时候,底层的缓存并没有被自动分配,字体渲染器在需要的时候才会进行分配,除了1024x512alpha缓存,它总是被分配的。
字形在textures以列的形式进行打包,当渲染器遇到一个没有缓存的字形,它会按照上面列出来的顺序寻找合适的CacheTexture缓存字形。
这就是块列表使用的地方,它包含了cache texture的当前分配列和可用的空闲位置。如果字形符合存在的列,它会被添加到该列所占空间的末尾。
如果所有的列都被占用了,一个新的列会在剩余空间的左侧划分出来。因为很少的字体是等宽的,渲染器分配每一个字形的宽度为4像素的倍数。这是对列的重用和texture打包的好的折衷方案。打包不是最佳的,但是它提供了快速实现。
所有的字形周围都有一个像素的空边界,它们都存储在textures中,对于采取双重线性采样的font textures来说,这么做可以避免人工处理。
知道text在渲染的时候是否进行尺寸变换是非常重要的,变换被提交给Skia/Freetype,这意味着cache textures里的字形存储了变换,这在性能消耗方面提高了渲染质量。幸运的是,text是很少动态缩放的,即使有,也只有很少的字形被影响到。还有其他的paint属性可以影响字形的光栅化和存储:仿粗体,文字偏斜,X缩放,风格和线宽。
预先缓存
由于libhwui是延迟渲染的,和Skia的直接模式相反,在一帧开始的时候,已经知道需要被绘制到屏幕上的字形了,在显示列表操作排序的时候,字体渲染器会尽可能多的预缓存字形。
这样做的好处是会完全避免或者最小化在帧中间上传texture的数量。
texture上传是非常耗资源的操作,会导致CPU或者GPU暂停,更糟糕的是,在帧中间修改texture会对一些GPU产生严重的内存压力。
ImaginationTech的PowerVR SGX GPU在帧中间修改的时候,会强制驱动复制每一个修改的texture,因为一些font的texture是非常大的,如果不小心texture上传的话,会更加容易导致oom。
Google paly上面有一个计算器应用出现过这种情况,它用数学符号和数字绘制按钮,在字体渲染的时候,可能会出现oom,因为按钮的绘制是一个接一个的, 每一次绘制都会触发texture上传,这导致了整个font缓存的复制,系统没有那么多的内存来放置这么多份缓存的拷贝。
刷新缓存
用来缓存字形的textures是相当大的,所以当其他应用需要更多内存的时候它们可能会被系统回收。
当用户隐藏当前应用的时候,系统会发消息通知应用释放尽可能多的内存,应用在大部分情况下会摧毁最大的textures缓存。在Andorid设备上,除了第一个被创建的(默认为1024x512)其他所有的textures缓存都被认为是大的textures。
当没有所有的缓存中都没有空间的时候,textures会被刷新,font渲染器会保持一个LRU(最近最少使用)的列表,但是没有使用它做任何事情,如果需要的话,通过刷新很少使用的内存来是缓存的刷新更加智能,目前位置还没有需要这样做,但是要记住它是潜在的优化方向。
批量处理与合并
Android 4.3介绍了绘制操作的批处理与合并,一个非常重要的优化是大幅减少了传递给OpenGL驱动的命令数。
为了实现合并,font渲染器缓存了多个绘制命令的文本几何数据。每一个缓存texture有一个客户端数组,里面包含了2048个四边形(1四边形 = 1 字形),他们都共享一个独立的索引缓冲(在GPU中以VBO存在)。
当libhwui执行一个文字绘制命令时,文字渲染器会为每一个字形获取合适的mesh(网格,构成图形的基本单位)并会将位置和u/v坐标写进去。
Mesh会在一批结束或者quad缓存满了之后传送到GPU。渲染一个单独的string可能需要多个mesh,每个缓存texture有一个mesh。
这个优化是比较容易实现,并且会极大的提高性能。由于文字渲染器使用多个缓存texture,有可能会出现string中的大部分字形是一个texture的一部分,而一些字形是另一个texture的一部分。如果没有批处理和合并操作,在每一次文字渲染器需要切换到不同的缓存texture时,都会给GPU提交一个绘制命令。
我曾经在一个test的app中碰到过这种问题,这个应用只是渲染不同风格和尺寸的“hello world”,在“o”字母和其他的字形被存在不同的texture中的特定情况下。这会导致文字渲染器会先渲染“hell”,然后“o”,然后“w”,然后“o”,然后“rld”,总共执行了5个绘制命令和5个texture绑定,而实际上两个都之需要2次,现在的渲染器先绘制“hell w rld”然后一块绘制两个“o”。
优化texture上传
前面曾经提过文字渲染器会在更新缓存texture时尝试尽可能少的上传数据,通过跟踪每一个texture的被变动的部分(dirty rect),可惜的时这种方法有两个限制。
首先,OpenGL ES2.0不允许上传一个随意的子矩形。glTexSubImage2D允许你指定矩形的x/y和width/height来更新texture的一部分,但是它是假设存在于主内存数据的stride(步幅)是矩形的宽度。
这个可以通过创建合适尺寸的CPU缓存来实现,但前提是必须知道变动矩形的大小。一个比较好的折中方法是上传一个最小的包含dirty rect的像素带,因为这个像素带的宽度是和texture一样的,所以我们可能会浪费一些带宽,但还是比上传整个texture好。
第二个问题是,texture上传是同步的操作,这可能会导致cpu长时间的等待,对于已经预先缓存的其实影响不大。但是对于使用了很多文字的应用或者有很多字形的语言环境,比如中文,这个问题可能会被用户感觉到。
幸运的是,OpenGL ES3.0对这两个问题提供了解决方法,现在可以使用新的像素存储属性GL_UNPACK_ROW_LENGTH上传字矩形了。这个属性指定了stride或者内存中的源数据,但是要小心的是:这个属性影响当前OpenGL context的全局状态。
在texture上传期间的CPU等待可以通过使用像素缓存对象(PBO)来避免,就想OpengGL中所有的buffer对象,PBO存在与GPU,但可以被映射进内存。PBO有很多有趣的属性但是我们关心的是在从内存中取消映射后,它可以异步上传texture,这样操作的顺序就变成了:
glMapBufferRange → write glyphs to buffer → glUnmapBuffer → glPixelStorei(GL_UNPACK_ROW_LENGTH) → glTexSubImage2D
现在调用glTexSubImage2D会直接返回,而不是阻塞渲染器。文字渲染器现在将整个buffer映射进内存,尽管它看起来没有引起性能问题,但是将需要更新的cache texture的范围映射进来而不是全部会更好。
阴影
文字通常是和阴影一起渲染的,一个相当耗费资源的操作。由于相邻的字形会模糊进彼此,文字渲染器不能独立的预先模糊字形。
有许多方法来实现模糊,但是要在一帧中最小化混合操作和纹理采样,阴影被以textures存储并且会在多个帧中存在。
来源:https://blog.csdn.net/fanfanxiaozu/article/details/45849511
技术交流,欢迎加我微信:ezglumes ,拉你入技术交流群。
私信领取相关资料
推荐阅读:
觉得不错,点个在看呗~
