
入职第一天,老板竟然让我优化5亿数据量,要凉凉?
jsoncat:https://github.com/Snailclimb/jsoncat[1] (仿 Spring Boot 但不同于 Spring Boot 的一个轻量级的 HTTP 框架)
前段时间hellohello-tom离职了,因为个人原因,在修整一段时间后,重新入职了一家新公司。入职的第一天tom哥就经历了一次生产事故,运维同学告警说线上MYSQL负载压力大,直接就把主库MYSQL压崩了(第一天这可不是好兆头),运维同学紧急进行了主从切换,在事后寻找导致生产事故的原因时,排查到是慢查询导致mysql雪崩的主要原因,在导出慢查询的sql后,项目经理直接说吧这个mysql优化的功能交给新来的tom哥吧,tom哥赶紧打开跳板机进行查看,不看不知道一看吓一跳 单表的数据量已经达到了5亿级别!,这尼玛肯定是历史问题一直堆积到现在才导致的啊,项目经理直接就把这个坑甩给了tom哥,tom哥心中想,我难道试岗期都过不了么??🤣
单表的数据量已经达到了5亿级别!,这尼玛肯定是历史问题一直堆积到现在才导致的啊,项目经理直接就把这个坑甩给了tom哥,tom哥心中想,我难道试岗期都过不了么??🤣
好在tom哥身经百战,赶快与项目经理与老同事进行沟通,了解业务场景,才发现导致现在的情况是这样的,tom哥所在的公司是主要做IM社交系统的,这个5亿级别的数据表是关注表,也是俗称的粉丝表,在类似与某些大V、或者是网红,粉丝过百万是非常常见的。在A关注B后会产生一条记录,B关注A时也会产生一条记录,时间积累久了才达到今天这样的数据规模,项目经理慢悠悠的对tom哥说,这个优化不用着急,先出方案吧!tom哥心中一万个草泥马经过,这上来就给了一块不好坑的骨头,看来是要试试我能力的深浅啊。
按照tom哥之前经验,单表在达到500W左右的数据就应该考虑分表了,常见分表方案无非就是hash取模,或者range分区这两种方法,但是这次的数据分表与迁移过程难度在于两方面:
1、数据平滑过度,在不停机的情况把单表数据逐步迁移(老板说:敢宕机分分钟损失几千块,KPI直接给你扣成负的)
2、数据分区,采用hash还是range?(暂时不能使用一些分库分表中间件,无奈。)
首先说说hash
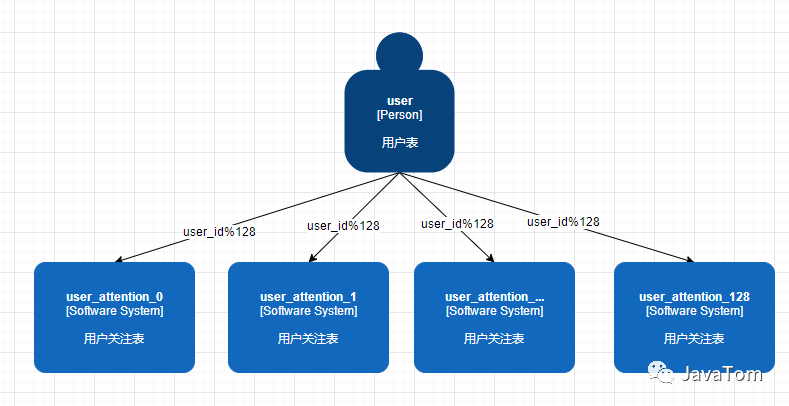
常规我们都是拿用户id进行取模,模到多少直接把数据塞进去就行了,简单粗暴,但是假如说user_id=128与user_id=257再模128后都是对应user_attention_1这个表,他俩也恰好是网红,旗下粉丝过百万,那轻轻松松两个人就能把数据表撑满,其他用户再进来数据的时候无疑user_attention_1这个表还会成为一张大表,这就是典型的数据热点问题,这个方案可以PASS,有的同学说可以user_id和fans_id组合进行取模进行分配,tom哥也考虑过这个问题,虽然这样子数据分配均匀了,但是会有一个致命的问题就是查询问题(因为目前没有做类似mongodb与db2这种高性能查询DB,也没做数据同步,考虑到工作量还是查询现有的分表内的数据),例如业务场景经常用到的查询就是我关注了那些人,那些人关注了我,所以我们的查询代码可能会是这样写的
//我关注了谁
select * from user_attention where user_id = #{userId}
//谁关注了我
select * from user_attention where fans_id = #{userId}
在我们进行user_id与fans_id组合后hash后,如果我想查询我关注的人与谁关注我的时候,那我将检索128张表才能得到结果,这个也太恶心了,肯定不可取,并且考虑到以后扩容至少也要影响一半数据,实在不好用,这个方案PASS。
接下来说说range
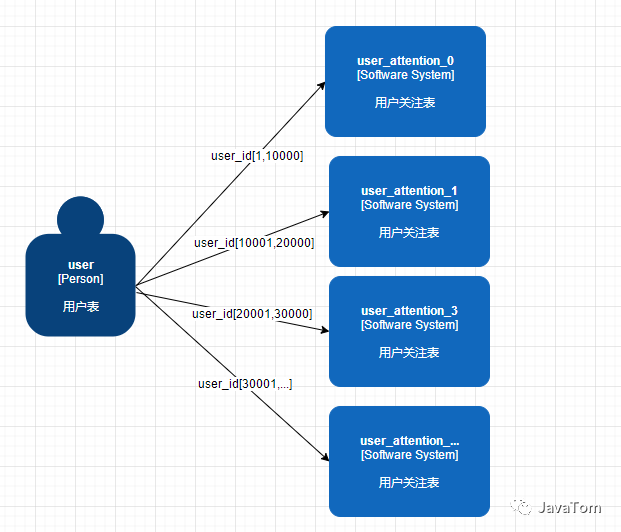
Range看起来也很简单,用户id在一定的范围时候就把他路由到一个表中,例如用户id=128,那就在[0,10000]这个区间中对应的是user_attention_0这个表,就直接把数据塞进去就可以了,但是这样同样也会产生热点数据问题,看来简单的水平分区已经不能满足,这个方案也可以pass了,还是要另寻他经啊。
经过tom哥日夜奋战,深思熟虑之后,给出了三个解决方案
先说说第一种方案range+一致性hash环组合(hash环节点10000)
什么是hash环看这里[2] 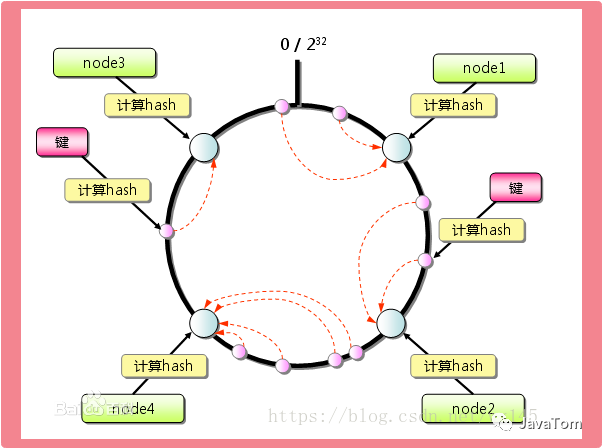
想采用这个方案主要是因为
1、扩容简单,影响范围小,只涉及hash环上单个节点影响
2、数据迁移简单,每次扩容只需把新增的节点与后置节点进行数据交互
3、查询范围小,按照range与hash关系检索部分表分区
大概思路我们还是先按照user_id进行大概范围划分,但是range之后我后面对应的可能就不是一个表了,而是一个hash环
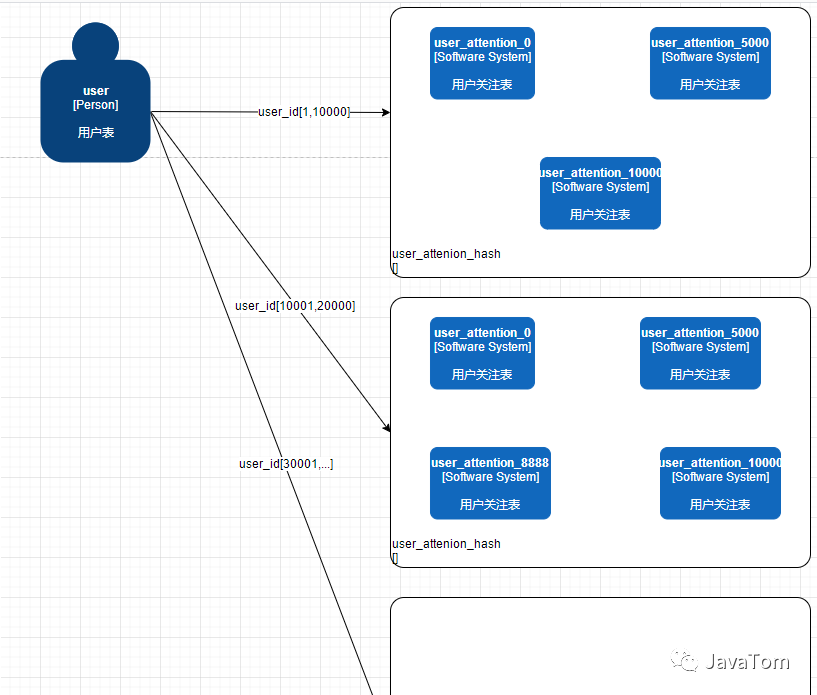
在每个range区域后都对应着自己一套的环,我们可以根据实际情况进行扩容,比如在[1,10000]这个范围内只有2个大V,那我们分三个表就够了,预留1500万的数据容量。[10001,20000]中有4个网红和大V,hash环上就给出实际4张表,我们的用户id可以顺时针顺序坐落到第一个物理表,数据进行入库。
凡事有利有弊,方案也要结合工时,实际可行性与技术评审之后才能决定,弊端咱也要列出来
1、设计复杂,需要增加range区域与hash环关系
2、系统内修改波及较多,查询关系复杂,多了一层路由表的概念,虽然尽量吧用户数据分配到一个区之内,但是想查询谁关注我,与我关注谁这样的逻辑时还是复杂。
说说第二种方案range+hash取模(hash模300)
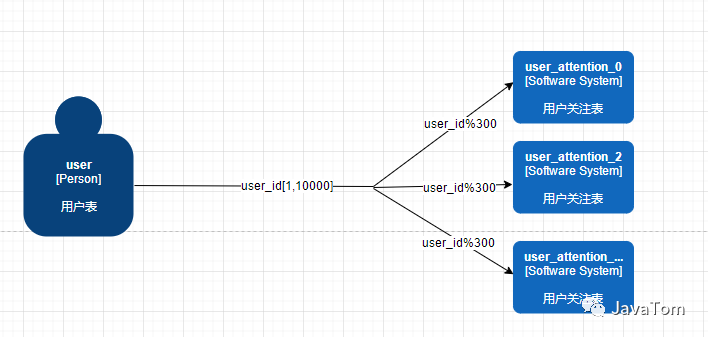
这个其实就比较好理解了,就是一个简单的range+hash取模组合的形式,先range到一定的范围后,在这个范围内进行hash取模找到对应的表进行存储,这个方案比方案一简单点,但是方案一存在的问题他也存在,并且他还有扩容数据影响范围广的问题。但是实现起来就简单不少,从查询方面看根据不同场景可以控制取模的大小范围,根据实际情况每个分区的hash模采用不同的值。
最后一种方案range userId分区
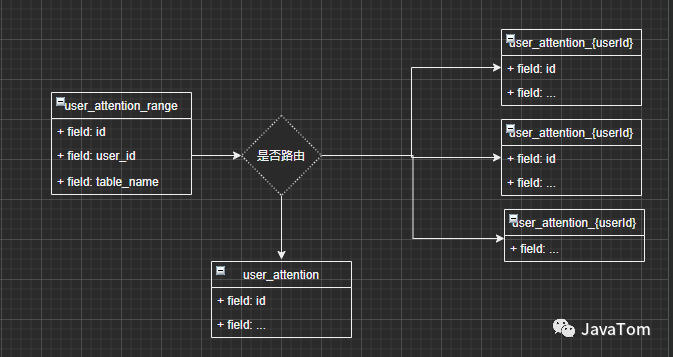
这个方案是tom哥觉得靠谱性与实施性可能最高的一种,看起来挺像第二种方案的,但是更具体了一点,首先会定义一个中间关系表user_attention_routing
| 字段名 | 备注 |
|---|---|
| id | 主键id |
| user_id_min | 用户id最小区间 |
| user_id_max | 用户id最大区间 |
| table_name | 路由到的表名称 |
我们会把用户范围与路由到哪个表做成关系,根据范围区间进行查找,结合现有数据当某个大V,或者网红数据量比较大,我们就给他路由自成一表数据大概是这样的
| user_id_min | user_id_max | tablename |
|---|---|---|
| 1 | 10000 | user_attention_0 |
| 256 | 256 | user_attention_256 |
例如user_id=256是个大V,就把他单独提出来让他自成一表,在查询范围的时候优先查是否有自己单独对应的路由表,而其他那些零碎用户还是路由到一个统一表内,这时候有的同学会说这样子数据不都又不均匀了么,tom哥也曾这样认为,但是分到绝对的均匀基本不太可能,只能做到相对,尽量把某些大V分出去,不占用公共资源,当某个人突然成为大V后,在吧这个人再单独分出去,不断演变这个过程,保证数据的平衡,并且这样子处理之后很多原来的关联查询其实改动不大了,只要在数据迁移后对原来的所有包含user_attention 进行动态的改造即可(使用个mybatis的拦截器就能搞定)PS:其实分析实际业务场景大部分的关注数据还是来源于那些零碎用户的。
分表方案首先就这样定了,接下来另一个问题就是查询问题,上文说过很多业务查询无非就是谁关注了我,我关注了谁这样的场景,如果继续使用之前的
//我关注了谁
select * from user_attention where user_id = #{userId}
//谁关注了我
select * from user_attention where fans_id = #{userId}
这样的方案,当我要查询我的粉丝有哪些时,这样就悲剧了,我还是要检索全表根据fansid找到我所有的粉丝,因为表内只记录了我关注了谁这样的数据,考虑到这样的问题,tom哥决定重新设计数据存储形式,使用空间换时间的思路,原来处理的方式是用户在关注对方的时候产生一条记录,现在处理方式是用户A在关注用户B时写入两条数据,通过字段区分关系,假如user_attention表是这样的
| user_id | fans_id | state |
|---|---|---|
| 1 | 2 | 1 |
| 2 | 1 | 0 |
在用户1关注2后产生两条数据,state(1代表我关注了,0代表我被关注了,2代表咱俩互关),采用这样的数据存储方式后,我所有的查询都可以从user_id进行出发了,不在逆向去推fans_id这样的方式,数据库索引设计上,考虑好user_id、fans_id、state与user_id、state这样的结构即可,是不是感觉很简单,虽然数据量存储变多了,但是查询方便了好多。
分表和查询问题解决了,最后就是要考虑数据迁移的过程了,这一步也非常重要。搞不好就要被扣掉自己的KPI了(步步为营啊)
数据迁移最需要考虑的问题就是个时效性,迁移程序必不可少,如何生产环境正常跑着,迁移脚本线下跑着数据互不影响呢?答案就是经典套路数据双写,因为老的数据不是一下子就迁移到新表内的,现在和user_attention产生的数据还是要保持的,在产生老表数据的同时,根据路由规则,直接存到新表内一份,线下的迁移程序多开几台服务慢慢跑呗,不过可要控制好数据量,别沾满io影响生产环境,线下的模拟和演练也是必不可少的,谁都不能保证会不会出啥问题呢。迁移脚本和线上做好user_id和fans_id的唯一索引就行,在某些极端情况下,数据会存在新表内写入数据,但是老表内数据还没更新的可能这个做好版本号控制和日志记录就可以了,这些都比较简单。
当新表数据和老表完全同步时我们就可以把所有系统内涉及老表查询的语句都改成新表查询,验证下有没有问题,如果没有问题最后就可以痛快的
truncate table user_attention;
干掉这个5亿数据量的定时炸弹了。好了今天分享就结束了,看来tom哥不仅能挺过试岗期也能挺过试用期了,不说了下班回家抱娃去了😚。
我是hellohello-tom,一个二线城市的程序员
参考资料
https://github.com/Snailclimb/jsoncat: https://github.com/Snailclimb/jsoncat
[2]https://www.cnblogs.com/lpfuture/p/5796398.html: https://www.cnblogs.com/lpfuture/p/5796398.html