
老板要我做一个 IP 属地功能!
来源:juejin.cn/post/
7118954784853327903

HttpServletRequest 获取 IP Ip2region 99.9%准确率: 多查询客户端的支持 Ip2region V2.0 特性 ip2region xdb java 查询客户端实现 IDEA中做个测试 编译测试程序 查询测试 bench 测试
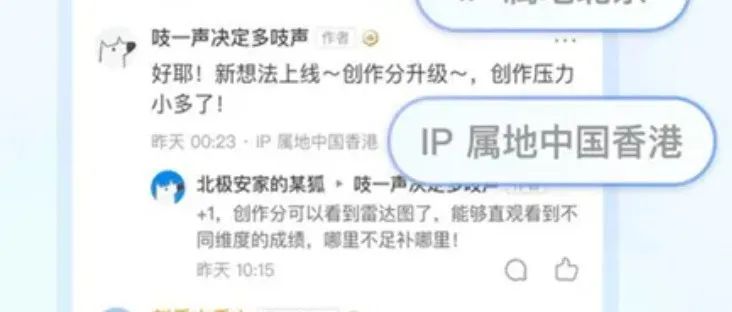
细心的朋友应该会发现,最近,继新浪微博之后,头条、腾讯、抖音、知乎、快手、小红书等各大平台陆陆续续都上线了“网络用户IP地址显示功能”,境外用户显示的是国家,国内的用户显示的省份,而且此项显示无法关闭,归属地强制显示。
作为技术人,那!这个功能要怎么实现呢?
HttpServletRequest 获取 IP
下面,我就来讲讲,Java中是如何获取IP属地的,主要分为以下几步:
通过 HttpServletRequest 对象,获取用户的 「IP」 地址 通过 IP 地址,获取对应的省份、城市
首先需要写一个 IP 获取的工具类,因为每一次用户的 Request 请求,都会携带上请求的 IP 地址放到请求头中
import javax.servlet.http.HttpServletRequest;
import java.net.InetAddress;
import java.net.NetworkInterface;
import java.net.UnknownHostException;
/**
* 常用获取客户端信息的工具
*/
public class NetworkUtil {
/**
* 获取ip地址
*/
public static String getIpAddress(HttpServletRequest request) {
String ip = request.getHeader("x-forwarded-for");
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("Proxy-Client-IP");
}
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("WL-Proxy-Client-IP");
}
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("HTTP_CLIENT_IP");
}
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("HTTP_X_FORWARDED_FOR");
}
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getRemoteAddr();
}
// 本机访问
if ("localhost".equalsIgnoreCase(ip) || "127.0.0.1".equalsIgnoreCase(ip) || "0:0:0:0:0:0:0:1".equalsIgnoreCase(ip)){
// 根据网卡取本机配置的IP
InetAddress inet;
try {
inet = InetAddress.getLocalHost();
ip = inet.getHostAddress();
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
// 对于通过多个代理的情况,第一个IP为客户端真实IP,多个IP按照','分割
if (null != ip && ip.length() > 15) {
if (ip.indexOf(",") > 15) {
ip = ip.substring(0, ip.indexOf(","));
}
}
return ip;
}
/**
* 获取mac地址
*/
public static String getMacAddress() throws Exception {
// 取mac地址
byte[] macAddressBytes = NetworkInterface.getByInetAddress(InetAddress.getLocalHost()).getHardwareAddress();
// 下面代码是把mac地址拼装成String
StringBuilder sb = new StringBuilder();
for (int i = 0; i < macAddressBytes.length; i++) {
if (i != 0) {
sb.append("-");
}
// mac[i] & 0xFF 是为了把byte转化为正整数
String s = Integer.toHexString(macAddressBytes[i] & 0xFF);
sb.append(s.length() == 1 ? 0 + s : s);
}
return sb.toString().trim().toUpperCase();
}
}
通过此方法,从请求Header中获取到用户的IP地址。
之前我在做的项目中,也有获取IP地址归属地省份、城市的需求,用的是:淘宝IP库。
地址:https://ip.taobao.com/。
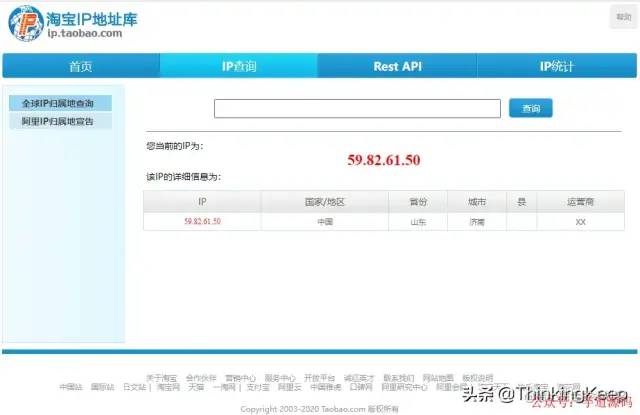
再见ip.taobao,全网显示 IP 归属地。
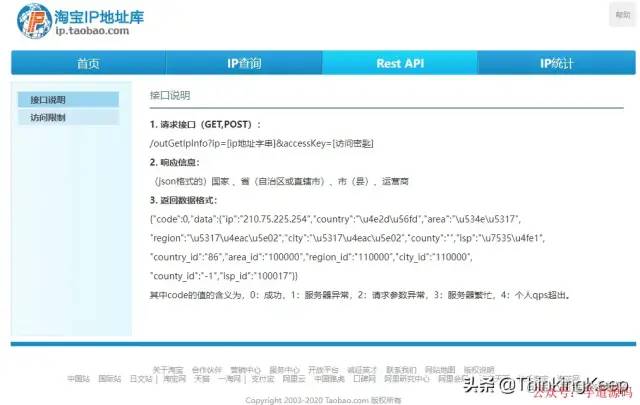
原来的请求源码如下:
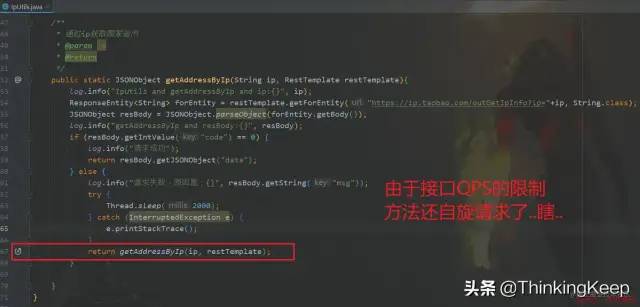

可以看到日志log文件中,大量的the request over max qps for user问题。

Ip2region
下面,给大家介绍下之前在Github冲浪时发现的今天的主角:
Ip2region开源项目,github地址:https://github.com/lionsoul2014/ip2region。
❝
目前最新已更新到了v2.0版本,ip2region v2.0是一个离线IP地址定位库和IP定位数据管理框架,10微秒级别的查询效率,准提供了众多主流编程语言的 xdb 数据生成和查询客户端实现。
❞
99.9%准确率:
❝
数据聚合了一些知名ip到地名查询提供商的数据,这些是他们官方的的准确率,经测试着实比经典的纯真IP定位准确一些。ip2region的数据聚合自以下服务商的开放API或者数据(升级程序每秒请求次数2到4次):
01, >80%, 淘宝IP地址库,http://ip.taobao.com/%5C02, ≈10%, GeoIP,https://geoip.com/%5C03, ≈2%, 纯真IP库,http://www.cz88.net/%5C❞
备注:如果上述开放API或者数据都不给开放数据时ip2region将停止数据的更新服务。
多查询客户端的支持
已经集成的客户端有:java、C#、php、c、python、nodejs、php扩展(php5和php7)、golang、rust、lua、lua_c, nginx。
| binding | 描述 | 开发状态 | binary查询耗时 | b-tree查询耗时 | memory查询耗时 |
|---|---|---|---|---|---|
| c | ANSC c binding | 已完成 | 0.0x毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| c# | c# binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.1x毫秒 |
| golang | golang binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.1x毫秒 |
| java | java binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.1x毫秒 |
| lua | lua实现的binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.x毫秒 |
| lua_c | lua的c扩展 | 已完成 | 0.0x毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| nginx | nginx的c扩展 | 已完成 | 0.0x毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| nodejs | nodejs | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.1x毫秒 |
| php | php实现的binding | 已完成 | 0.x毫秒 | 0.1x毫秒 | 0.1x毫秒 |
| php5_ext | php5的c扩展 | 已完成 | 0.0x毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| php7_ext | php7的c扩展 | 已完成 | 0.0毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| python | python bindng | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.x毫秒 |
| rust | rust binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.x毫秒 |
Ip2region V2.0 特性
「1、标准化的数据格式」
每个 ip 数据段的 region 信息都固定了格式:国家|区域|省份|城市|ISP,只有中国的数据绝大部分精确到了城市,其他国家部分数据只能定位到国家,后前的选项全部是0。
「2、数据去重和压缩」
xdb 格式生成程序会自动去重和压缩部分数据,默认的全部 IP 数据,生成的 ip2region.xdb 数据库是 11MiB,随着数据的详细度增加数据库的大小也慢慢增大。
「3、极速查询响应」
即使是完全基于 xdb 文件的查询,单次查询响应时间在十微秒级别,可通过如下两种方式开启内存加速查询:
vIndex 索引缓存 :使用固定的 512KiB 的内存空间缓存 vector index 数据,减少一次 IO 磁盘操作,保持平均查询效率稳定在10-20微秒之间。 xdb 整个文件缓存:将整个 xdb 文件全部加载到内存,内存占用等同于 xdb 文件大小,无磁盘 IO 操作,保持微秒级别的查询效率。
「4、极速查询响应」
v2.0 格式的 xdb 支持亿级别的 IP 数据段行数,region 信息也可以完全自定义,例如:你可以在 region 中追加特定业务需求的数据,例如:GPS信息/国际统一地域信息编码/邮编等。也就是你完全可以使用 ip2region 来管理你自己的 IP 定位数据。
ip2region xdb java 查询客户端实现
「使用方式」
引入maven仓库:
<dependency>
<groupId>org.lionsoul</groupId>
<artifactId>ip2region</artifactId>
<version>2.6.4</version>
</dependency>
「完全基于文件的查询」
import org.lionsoul.ip2region.xdb.Searcher;
import java.io.*;
import java.util.concurrent.TimeUnit;
public class SearcherTest {
public static void main(String[] args) {
// 1、创建 searcher 对象
String dbPath = "ip2region.xdb file path";
Searcher searcher = null;
try {
searcher = Searcher.newWithFileOnly(dbPath);
} catch (IOException e) {
System.out.printf("failed to create searcher with `%s`: %s\n", dbPath, e);
return;
}
// 2、查询
try {
String ip = "1.2.3.4";
long sTime = System.nanoTime();
String region = searcher.search(ip);
long cost = TimeUnit.NANOSECONDS.toMicros((long) (System.nanoTime() - sTime));
System.out.printf("{region: %s, ioCount: %d, took: %d μs}\n", region, searcher.getIOCount(), cost);
} catch (Exception e) {
System.out.printf("failed to search(%s): %s\n", ip, e);
}
// 3、备注:并发使用,每个线程需要创建一个独立的 searcher 对象单独使用。
}
}
「缓存VectorIndex索引」
我们可以提前从 xdb 文件中加载出来 VectorIndex 数据,然后全局缓存,每次创建 Searcher 对象的时候使用全局的 VectorIndex 缓存可以减少一次固定的 IO 操作,从而加速查询,减少 IO 压力。
import org.lionsoul.ip2region.xdb.Searcher;
import java.io.*;
import java.util.concurrent.TimeUnit;
public class SearcherTest {
public static void main(String[] args) {
String dbPath = "ip2region.xdb file path";
// 1、从 dbPath 中预先加载 VectorIndex 缓存,并且把这个得到的数据作为全局变量,后续反复使用。
byte[] vIndex;
try {
vIndex = Searcher.loadVectorIndexFromFile(dbPath);
} catch (Exception e) {
System.out.printf("failed to load vector index from `%s`: %s\n", dbPath, e);
return;
}
// 2、使用全局的 vIndex 创建带 VectorIndex 缓存的查询对象。
Searcher searcher;
try {
searcher = Searcher.newWithVectorIndex(dbPath, vIndex);
} catch (Exception e) {
System.out.printf("failed to create vectorIndex cached searcher with `%s`: %s\n", dbPath, e);
return;
}
// 3、查询
try {
String ip = "1.2.3.4";
long sTime = System.nanoTime();
String region = searcher.search(ip);
long cost = TimeUnit.NANOSECONDS.toMicros((long) (System.nanoTime() - sTime));
System.out.printf("{region: %s, ioCount: %d, took: %d μs}\n", region, searcher.getIOCount(), cost);
} catch (Exception e) {
System.out.printf("failed to search(%s): %s\n", ip, e);
}
// 备注:每个线程需要单独创建一个独立的 Searcher 对象,但是都共享全局的制度 vIndex 缓存。
}
}
「缓存整个xdb数据」
我们也可以预先加载整个 ip2region.xdb 的数据到内存,然后基于这个数据创建查询对象来实现完全基于文件的查询,类似之前的 memory search。
import org.lionsoul.ip2region.xdb.Searcher;
import java.io.*;
import java.util.concurrent.TimeUnit;
public class SearcherTest {
public static void main(String[] args) {
String dbPath = "ip2region.xdb file path";
// 1、从 dbPath 加载整个 xdb 到内存。
byte[] cBuff;
try {
cBuff = Searcher.loadContentFromFile(dbPath);
} catch (Exception e) {
System.out.printf("failed to load content from `%s`: %s\n", dbPath, e);
return;
}
// 2、使用上述的 cBuff 创建一个完全基于内存的查询对象。
Searcher searcher;
try {
searcher = Searcher.newWithBuffer(cBuff);
} catch (Exception e) {
System.out.printf("failed to create content cached searcher: %s\n", e);
return;
}
// 3、查询
try {
String ip = "1.2.3.4";
long sTime = System.nanoTime();
String region = searcher.search(ip);
long cost = TimeUnit.NANOSECONDS.toMicros((long) (System.nanoTime() - sTime));
System.out.printf("{region: %s, ioCount: %d, took: %d μs}\n", region, searcher.getIOCount(), cost);
} catch (Exception e) {
System.out.printf("failed to search(%s): %s\n", ip, e);
}
// 备注:并发使用,用整个 xdb 数据缓存创建的查询对象可以安全的用于并发,也就是你可以把这个 searcher 对象做成全局对象去跨线程访问。
}
}
IDEA中做个测试
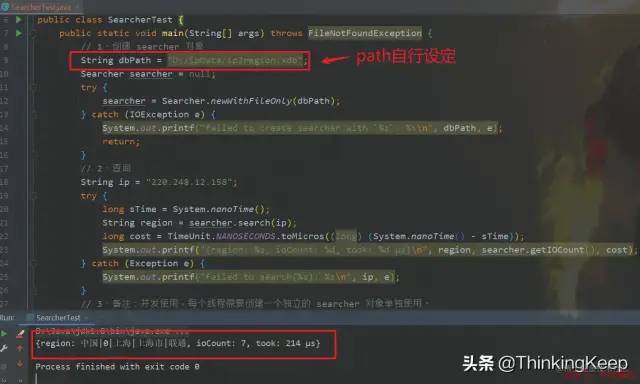
完全基于文件的查询
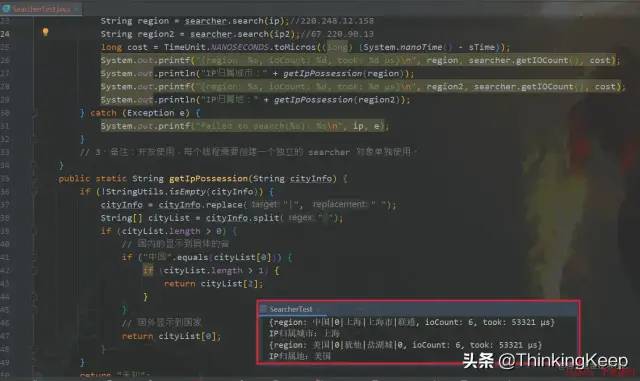
ip属地国内的话,会展示省份,国外的话,只会展示国家。可以通过如下图这个方法进行进一步封装,得到获取IP属地的信息。
❝
下面是官网给出的命令运行jar方式给出的测试demo,可以理解下
❞
编译测试程序
通过 maven 来编译测试程序。
# cd 到 java binding 的根目录
cd binding/java/
mvn compile package
然后会在当前目录的 target 目录下得到一个 ip2region-{version}.jar 的打包文件。
查询测试
可以通过 java -jar ip2region-{version}.jar search 命令来测试查询:
➜ java git:(v2.0_xdb) ✗ java -jar target/ip2region-2.6.0.jar search
java -jar ip2region-{version}.jar search [command options]
options:
--db string ip2region binary xdb file path
--cache-policy string cache policy: file/vectorIndex/content
例如:使用默认的 data/ip2region.xdb 文件进行查询测试:
➜ java git:(v2.0_xdb) ✗ java -jar target/ip2region-2.6.0.jar search --db=../../data/ip2region.xdb
ip2region xdb searcher test program, cachePolicy: vectorIndex
type 'quit' to exit
ip2region>> 1.2.3.4
{region: 美国|0|华盛顿|0|谷歌, ioCount: 7, took: 82 μs}
ip2region>>
输入 ip 即可进行查询测试,也可以分别设置 cache-policy 为 file/vectorIndex/content 来测试三种不同缓存实现的查询效果。
bench 测试
可以通过 java -jar ip2region-{version}.jar bench 命令来进行 bench 测试,一方面确保 xdb 文件没有错误,一方面可以评估查询性能:
➜ java git:(v2.0_xdb) ✗ java -jar target/ip2region-2.6.0.jar bench
java -jar ip2region-{version}.jar bench [command options]
options:
--db string ip2region binary xdb file path
--src string source ip text file path
--cache-policy string cache policy: file/vectorIndex/content
例如:通过默认的 data/ip2region.xdb 和 data/ip.merge.txt 文件进行 bench 测试:
➜ java git:(v2.0_xdb) ✗ java -jar target/ip2region-2.6.0.jar bench --db=../../data/ip2region.xdb --src=../../data/ip.merge.txt
Bench finished, {cachePolicy: vectorIndex, total: 3417955, took: 8s, cost: 2 μs/op}
可以通过分别设置 cache-policy 为 file/vectorIndex/content 来测试三种不同缓存实现的效果。@Note: 注意 bench 使用的 src 文件要是生成对应 xdb 文件相同的源文件。
❝
到这里获取用户IP属地已经完成啦,这篇文章介绍的v2.0版本,有兴趣的小伙伴可以登录上门的github地址了解下v1.0版本
❞
如若觉得有用,欢迎收藏+点赞!
完
程序汪资料链接
卧槽!字节跳动《算法中文手册》火了,完整版 PDF 开放下载!
卧槽!阿里大佬总结的《图解Java》火了,完整版PDF开放下载!
欢迎添加程序汪个人微信 itwang009 进粉丝群或围观朋友圈