
小米chaosblade的故障注入平台实践
1. 背景
当今社会互联网应用越来越广泛,用户量日益剧增。在人们对互联网服务的依赖性增大的同时,也对服务的可用性和体验感有了更高的要求。那么如何保障服务在运营过程中能一直给用户提供稳定的、不间断的、可靠可信的服务呢?
二 混沌工程介绍
都是基于故障注入来引入的。
混沌工程是一种生成新信息的实践,而故障测试是测试一种情况的一种特定方法。
故障测试会在具体的场景实施注入实验和验证预期,而混沌工程实验是围绕一个“稳态状态”通过更多场景来验证。
混沌工程建议是在生产环境中进行实验。
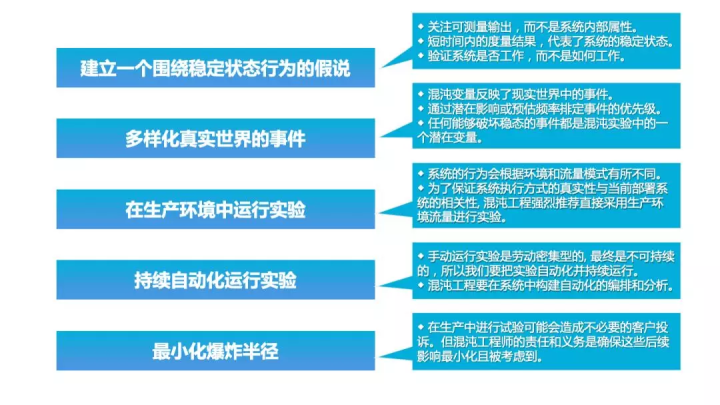
三 混沌工程原则

四 故障注入平台的构建
提供多样化、可视化操作的故障注入自动化平台
作为各种演练和故障测试及验证的统一入口
积累沉淀多种实验方案,建立系统上线健壮性评估基线
帮助业务发现更多未知的影响业务稳定的问题
验证业务的告警有效性和完整性
验证业务的故障预案是否有效
目前业内模拟故障的工具比较多样化,支持的功能和场景也各有优劣。通过对比来看,chaosblade支持功能和场景比较丰富,同时社区也是比较活跃的。我们在充分验证了大部分注入功能后,选择了它作为底层注入的核心模块。
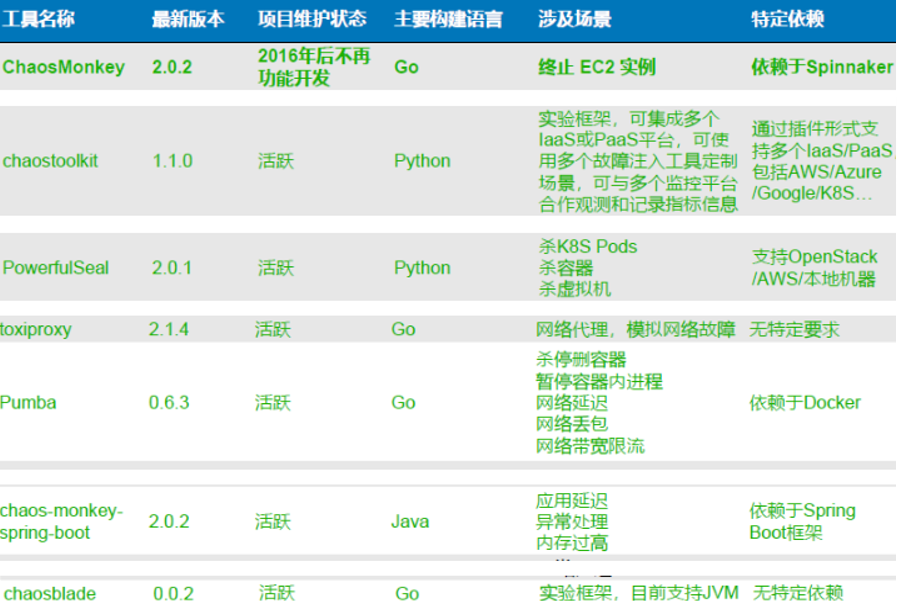
https://chaosblade-io.gitbook.io/chaosblade-help-zh-cn/
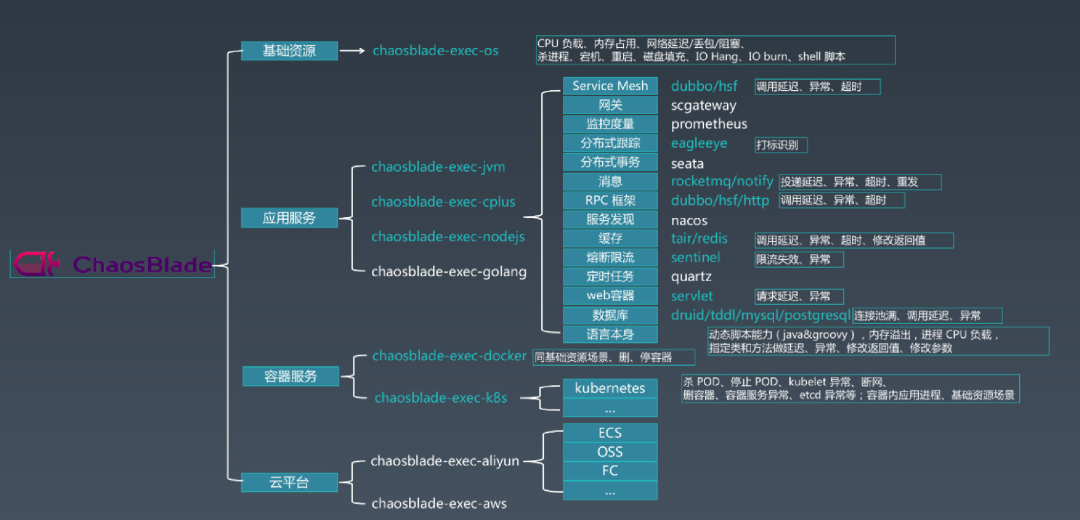
整个故障注入一共分为四个阶段:


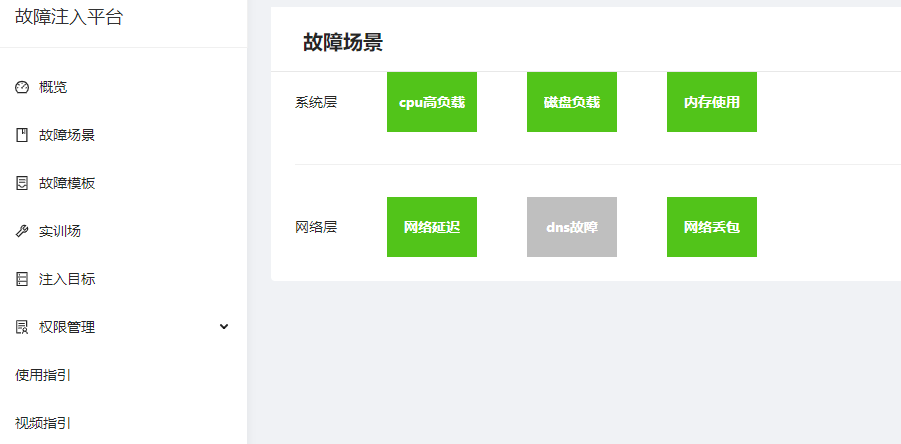
五 演练实践
定义并测量系统的“稳定状态”,精确定义指标 创建假设 线上流量复制持续导入测试环境 模拟现实世界中可能发生的事情 证明或反驳假设 总结和反馈问题优化
集群服务整体CPS 任务提交响应延迟 任务提交成功率 任务解析失败率 目标获取成功率 数据一致性和完整性
假设存在节点宕机,不影响稳态(此处不做介绍)。
使用系统层+网络层随机注入场景模拟。
在平台选择我们提供的系统场景故障模板和注入目标(一个注入任务中,单个机器只能注入一种场景,场景和机器随机选择)
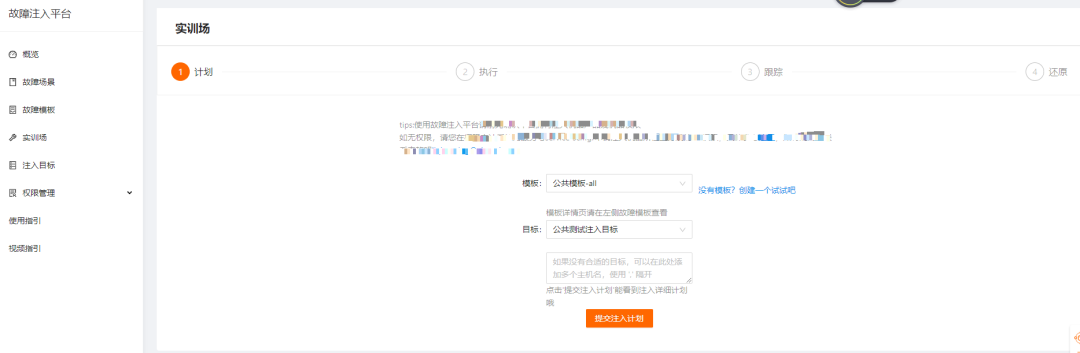
通过选择的注入模板和目标,生成一个注入计划,如下图:
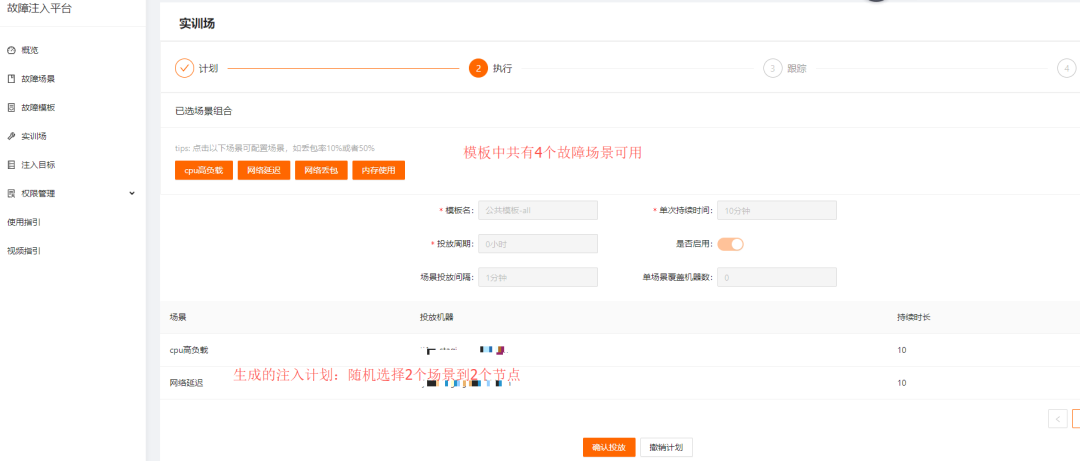
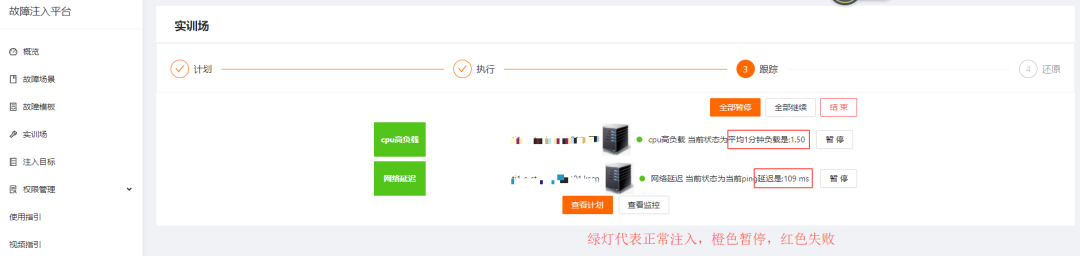
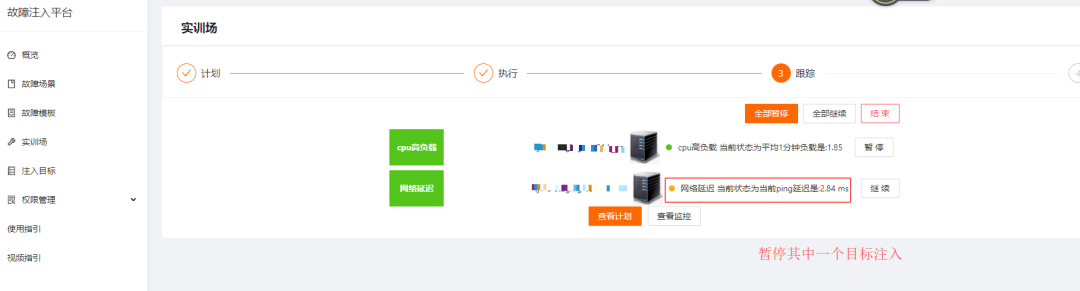
人为暂停指定目标,点击继续会继续注入
服务cps陡降
提交成功的任务,失败率大幅提升
用户任务提交出现不同程度延迟
关联服务进程异常退出
监控不细粒,能发现cps和失败率增加,但定位困难

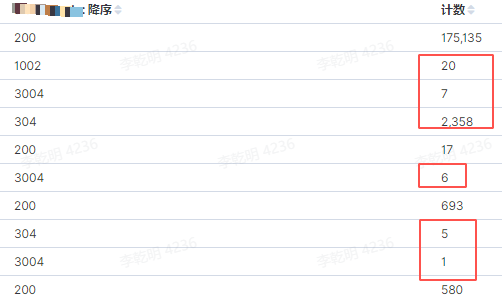
用户提交延迟和超时增加
结束整个注入任务
假设:某些节点在存在性能或者网络相关问题的时候,可能存在任务提交响应延迟,不影响稳态。
证明:存在任务提交响应延迟,间接性意味cps的下降。
反驳:发现非预期的 任务执行失败增加和关联进程异常退出的问题,监控缺失和不细粒等问题。


六 其他问题

七 未来规划