
豆瓣9.2分!17万条弹幕告诉你《沉默的真相》凭什么口碑高开暴走!
来源:CDA数据分析师
作者:Mika
数据:真达
【导读】
今天教大家用Python分析《沉默的真相》的17万条弹幕。公众号后台,回复关键字“沉默”获取完整数据。
距离上一部国产良心剧《隐秘的角落》刷屏还不到2个月,“秃头梗”、“爬山梗”还让人记忆犹新。
紧接着又一部爆款国产剧来了,那就是最近口碑炸裂的《沉默的真相》。

同样是来自爱奇艺针对悬疑短剧的“迷雾剧场”,《沉默的真相》根据紫金陈的小说《长夜难明》改编,讲述了检察官江阳历经多年,付出无数代价查清案件真相的故事。
开播当天《沉默的真相》在豆瓣开分8.8分,随着剧集的播出,该剧口碑势不可挡,一路走高,播出六集后,豆瓣评分冲到了9.2分,成功超越了它的前浪《隐秘的角落》。要知道,这种高开高走的趋势,在国产剧里是非常罕见的。
许多网友在最初刷剧时根本不信自己会哭,结果看到大结局才发现,这也太好哭了吧,看到主角江阳的舍命燃灯,真的让人哭出兰州拉面…

01
豆瓣 9.2分!
超越前浪《隐秘的角落》
上一部被称为年度爆款国剧的还是《隐秘的角落》,改编自紫金陈的推理小说--《坏小孩》,《隐秘的角落》一经播出就带着"小白船","爬山梗","秃头梗"热闹了一整个夏天。

在豆瓣已有78万余人进行评分,最终收官8.9分,是非常惊艳的成绩。

谁知仅过去2个月,又一部悬疑剧《沉默的角落》凭借着逆天的口碑火了!同样改编自作者紫金陈的小说《长夜难明》,一开播豆瓣就达到8.8分。随着播出分数越来越高,如今已有20万余人评分,高达9.2分,已经超过了前浪《隐秘的角落》。

豆瓣总体评分分析
近一步分析观众评分,我们发现:
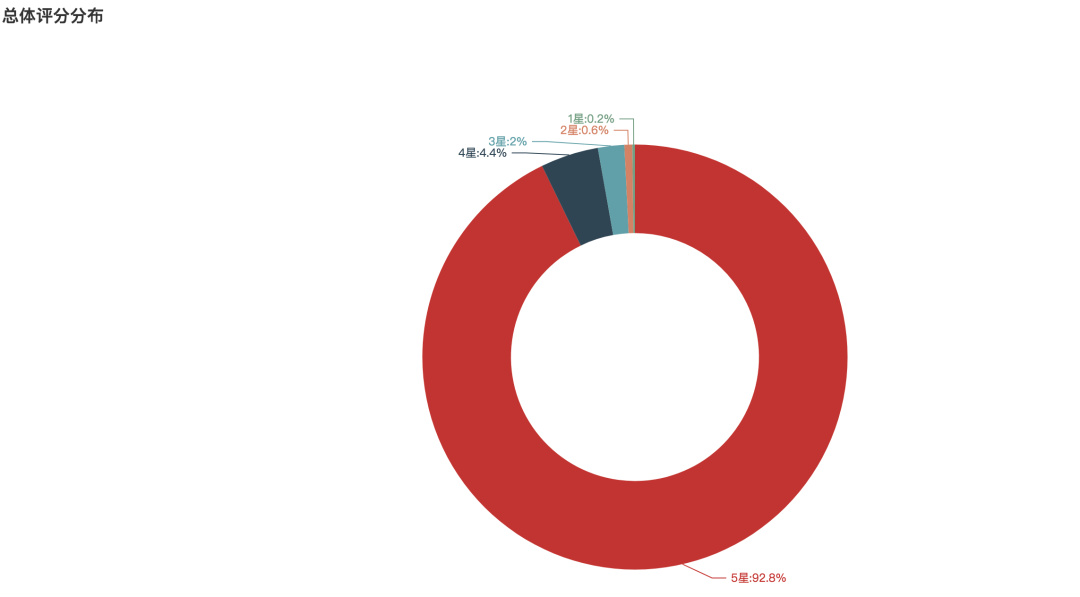
92.8%的观众给出了五星满分,这口碑在国产剧中已经达到标杆的水准。
豆瓣短评词云
然后我们再看到豆瓣的短评词云。

我们可以看到,观众在短评中讨论最多的就是主角"江阳",他的坚定和执着真可谓可歌可泣。"演员的演技","剧情",对"原著"的还原度,都得到了广泛的认可与好评。
02
刷剧《沉默的真相》
17万条弹幕都在说些什么
那么刷剧时,大家都在说些什么呢?接下来我们用Python分析了《沉默的真相》前10集的视频弹幕,共计173226条。
前十集弹幕走势图
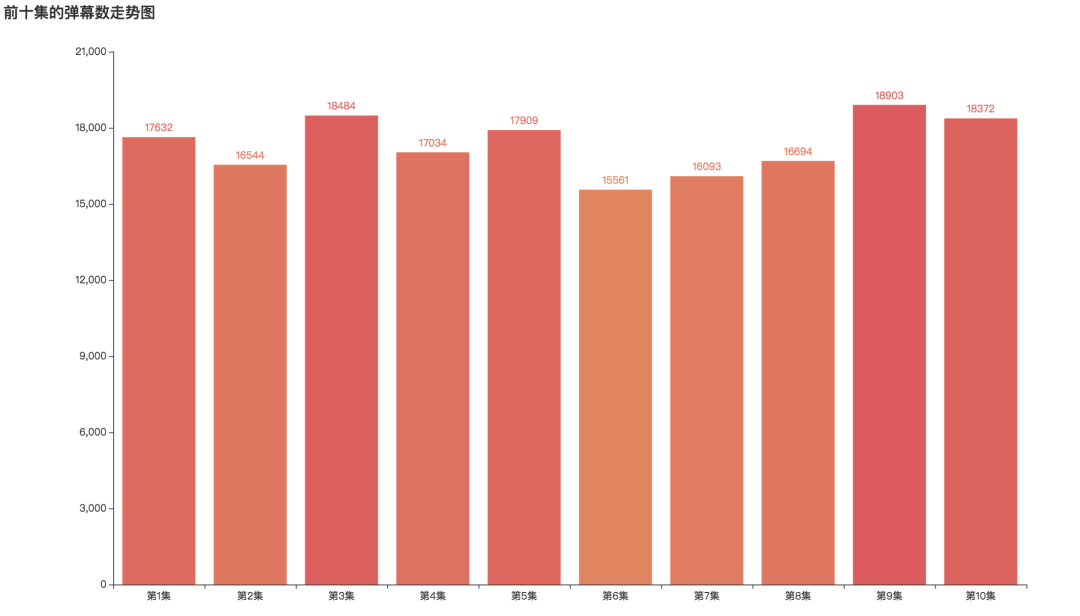
从图中可以看到,看剧时大家都特别爱发弹幕,前十集中:
弹幕数量最多分别是第9集,第3集和第10集,最多一集弹幕数为18903条
弹幕最少的是第六集,弹幕数为15561条
接着我们再看看剧中主要角色的弹幕词云:
江阳弹幕词云

由白宇饰演的江阳,原本年轻有为,但是为了探求真相坚持正义,付出了自己的生命。像"正义"、"厉害"、"演技"等都在词云中频频出现。
李静弹幕词云

关于谭卓饰演的李静,在刷剧时很多人都会联想到她在《延禧攻略》中高贵妃的角色。无论是从“高贵妃”到《我不是药神》中的刘思慧,还是这次的李静,谭卓的演技都让人有目共睹。
严良弹幕词云

从最初官宣影帝廖凡,就有不少观众表示冲着廖凡也得看《沉默的真相》,果不其然,剧集一播出,粉丝就夸他是“免检产品”,妥妥的~
张超弹幕词云

饰演张超的宁理老师是迷雾剧场的老朋友了,之前在《无罪之证》中他演的社会"丰田哥"人狠话不多,"反向抽烟"实在是太深入人心了。从《无证之罪》到《隐秘的角落》,再到《沉默的真相》,严良都换了三个人了,真是流水的严良,铁打的李丰田。
03
手把手教你
如何用Python分析弹幕
我们使用Python获取并分析爱奇艺《沉默的真相》前十集的弹幕数据,整个数据分析的流程分为以下三个部分:
弹幕数据获取 数据读入和简单处理 数据可视化分析
1. 数据获取
关于爱奇艺的弹幕数据获取程序之前文章中已经做过阐述。
2. 数据读入和预处理
首先导入所需包,其中pandas用于数据读入和数据处理,os用于文件操作,jieba用于中文分词,pyecharts和stylecolud用于数据可视化。
# 导入库
import os
import jieba
import pandas as pd
from pyecharts.charts import Bar, Pie, Line, WordCloud, Page
from pyecharts import options as opts
from pyecharts.globals import SymbolType, WarningType
WarningType.ShowWarning = False
import stylecloud
from IPython.display import Image
将爬取的数据存放在data文件夹下,使用os操作获取需要读取的csv文件列表并循环读入文件。
# 读入数据
data_list = os.listdir('../data/')
df_all = pd.DataFrame()
for i in data_list:
if i.endswith('csv'):
df_one = pd.read_csv(f'../data/{i}', engine='python', encoding='utf-8', index_col=0)
df_all = df_all.append(df_one, ignore_index=False)
print(df_all.shape)
(173226, 6)
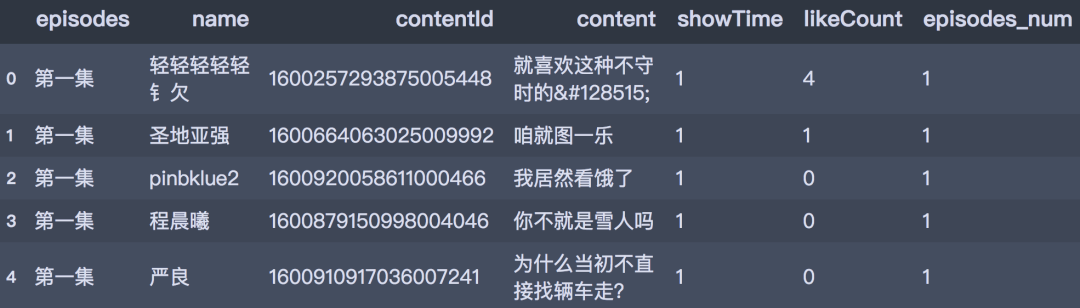
弹幕数量一共有173226条,预览一下数据:
df_all['name'] = df_all.name.str.strip()
df_all.head()
3. 数据可视化
分集的弹幕数
代码解说:
repl_list = {
'第一集 ': 1,
'第二集': 2,
'第三集': 3,
'第四集': 4,
'第五集': 5,
'第六集': 6,
'第七集': 7,
'第八集': 8,
'第九集': 9,
'第十集': 10
}
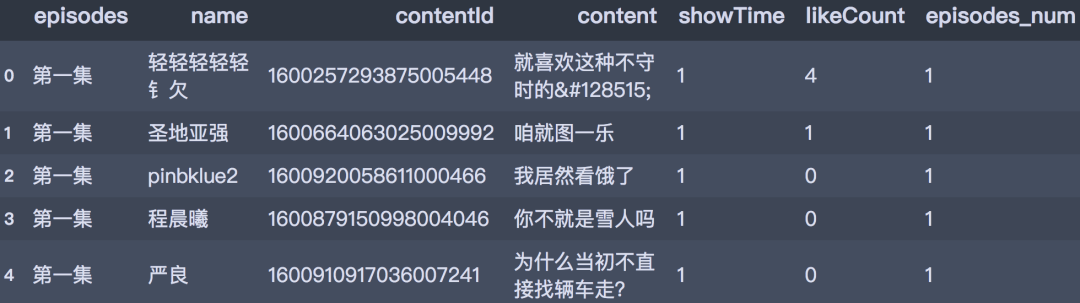
df_all['episodes_num'] = df_all['episodes'].map(repl_list)
df_all.head()
# 产生数据
danmu_num = df_all.episodes_num.value_counts()
danmu_num = danmu_num.sort_index()
x_data = ['第' + str(i) + '集' for i in danmu_num.index]
y_data = danmu_num.values.tolist()
# 条形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(xaxis_data=x_data)
bar1.add_yaxis('', y_axis=y_data)
bar1.set_global_opts(title_opts=opts.TitleOpts(title='前十集的弹幕数走势图'),
visualmap_opts=opts.VisualMapOpts(max_=20000, is_show=False)
)
bar1.render()
x_data = ['第' + str(i) + '集' for i in danmu_num.index]
y_data = danmu_num.values.tolist()
# 条形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(xaxis_data=x_data)
bar1.add_yaxis('', y_axis=y_data)
bar1.set_global_opts(title_opts=opts.TitleOpts(title='前十集的弹幕数走势图'),
visualmap_opts=opts.VisualMapOpts(max_=20000, is_show=False)
)
bar1.render('../html/爱奇艺弹幕数走势图.html')
弹幕角色-江阳 词云图
# 定义分词函数
def get_cut_words(content_series):
# 读入停用词表
stop_words = []
with open(r"stop_words.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加关键词
my_words = ['廖凡', '严良', '白宇', '江阳', '谭卓', '李静',
'宁理', '张超', '黄尧', '张晓倩', '奥利给'
]
for i in my_words:
jieba.add_word(i)
# 自定义停用词
my_stop_words = ['真的', '这部', '这是', '一种', '那种', '啊啊啊', '哈哈哈',
'哈哈哈哈', '我要']
stop_words.extend(my_stop_words)
# 分词
word_num = jieba.lcut(content_series.str.cat(sep='。'), cut_all=False)
# 条件筛选
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2]
return word_num_selected
# 获取分词结果
text1 = get_cut_words(content_series=df_all[df_all.name=='江阳']['content'])
# 绘制词云图
stylecloud.gen_stylecloud(text=' '.join(text1), max_words=1000,
collocations=False,
font_path=r'C:\Windows\Fonts\msyh.ttc',
icon_name='fas fa-heart',
size=653,
output_name='弹幕角色-江阳词云图.png')
恋习Python 关注恋习Python,Python都好练
好文章,我在看❤️