
简单复习下前端算法复杂度相关的知识
 定义
定义
从广义上讲
数据结构就是指
一组数据的存储结构。算法就是
操作数据的一组方法。
从狭义上讲
是指某些著名的数据结构和算法,比如队列、栈、堆、二分查找、动态规划等
数据结构和算法关系
数据结构是为算法服务的,算法要作用在特定的数据结构之上
比如,因为数组具有随机访问的特点,常用的二分查找算法需要用数组来存储数据。但如果我们选择链表这种数据结构,二分查找算法就无法工作了,因为链表并不支持随机访问
复杂度分析
事后统计法的局限性
测试结果非常依赖测试环境
测试环境中硬件的不同会对测试结果有很大的影响
测试结果受数据规模的影响很大
对于小规模的数据排序,插入排序可能反倒会比快速排序要快
大 O 复杂度表示法
int cal(int n) {int sum = 0;int i = 1;int j = 1;for (; i <= n; ++i) {j = 1;for (; j <= n; ++j) {sum = sum + i * j;}}}

公式:
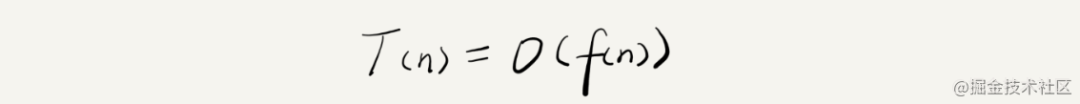
上边例子可表示为T(n) = O(2n^2+2n+3)
大 O 时间复杂度实际上并不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以,也叫作渐进时间复杂度(asymptotic time complexity),简称时间复杂度。

常量级时间
即便这段代码循环 10000 次、100000 次,只要是一个已知的数,跟 n 无关,照样也是常量级的执行时间
时间复杂度分析
1. 只关注循环执行次数最多的一段代码
忽略掉公式中的常量、低阶、系数,只需要记录一个最大阶的量级就可以了
我们在分析一个算法、一段代码的时间复杂度的时候,也只关注循环执行次数最多的那一段代码就可以了。这段核心代码执行次数的 n 的量级,就是整段要分析代码的时间复杂度。
int cal(int n) {int sum = 0;int i = 1;for (; i <= n; ++i) {sum = sum + i;}return sum;}
第 2、3 行代码都是常量级的执行时间,与 n 的大小无关,所以对于复杂度并没有影响。
循环执行次数最多的是第 4、5 行代码,所以这块代码要重点分析。这两行代码被执行了 n 次,所以总的时间复杂度就是
O(n)
2. 加法法则:总复杂度等于量级最大的那段代码的复杂度
int cal(int n) {int sum_1 = 0;int p = 1;for (; p < 100; ++p) {sum_1 = sum_1 + p;}int sum_2 = 0;int q = 1;for (; q < n; ++q) {sum_2 = sum_2 + q;}int sum_3 = 0;int i = 1;int j = 1;for (; i <= n; ++i) {j = 1;for (; j <= n; ++j) {sum_3 = sum_3 + i * j;}}return sum_1 + sum_2 + sum_3;}

3. 乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
落实到具体的代码上,我们可以把乘法法则看成是嵌套循环
int cal(int n) {int ret = 0;int i = 1;for (; i < n; ++i) {ret = ret + f(i);}}int f(int n) {int sum = 0;int i = 1;for (; i < n; ++i) {sum = sum + i;}return sum;}

几种常见时间复杂度实例分析


1. O(1)常量级时间复杂度
要代码的执行时间不随 n 的增大而增长,这样代码的时间复杂度我们都记作 O(1)。
只要算法中不存在循环语句、递归语句,即使有成千上万行的代码,其时间复杂度也是Ο(1)。
2. O(logn)、O(nlogn)对数阶时间复杂度
i=1;while (i <= n) {i = i * 2;}
变量 i 的值从 1 开始取,每循环一次就乘以 2。当大于 n 时
变量 i 的取值就是一个等比数列


3. O(m+n)、O(m*n)由两个数据的规模来决定
int cal(int m, int n) {
int sum_1 = 0;
int i = 1;
for (; i < m; ++i) {
sum_1 = sum_1 + i;
}
int sum_2 = 0;
int j = 1;
for (; j < n; ++j) {
sum_2 = sum_2 + j;
}
return sum_1 + sum_2;
}
复制代码上面代码的时间复杂度就是 O(m+n)
空间复杂度分析(只计算与n有关的内存空间)
空间复杂度全称就是
渐进空间复杂度(asymptotic space complexity),表示算法的存储空间与数据规模之间的增长关系常见的空间复杂度就是
O(1)、O(n)、O(n2 ),像O(logn)、O(nlogn)这样的对数阶复杂度平时都用不到
void print(int n) {int i = 0;int[] a = new int[n];for (i; i <n; ++i) {a[i] = i * i;}for (i = n-1; i >= 0; --i) {print out a[i]}}
第 2 行代码中,我们申请了一个空间存储变量 i,但是它是常量阶的,跟数据规模 n 没有关系,所以我们可以忽略。
第 3 行申请了一个大小为 n 的 int 类型数组,除此之外,剩下的代码都没有占用更多的空间,所以整段代码的空间复杂度就是 O(n)。
总结
复杂度也叫渐进复杂度,包括时间复杂度和空间复杂度,用来分析算法执行效率与数据规模之间的增长关系,可以粗略地表示,越高阶复杂度的算法,执行效率越低
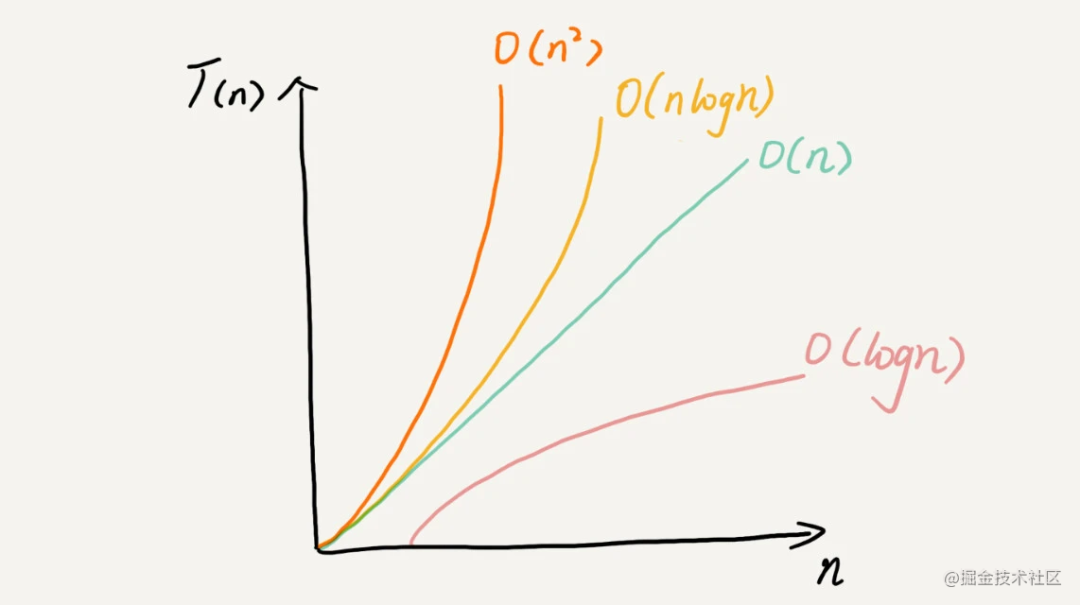
浅析最好、最坏、平均、均摊时间复杂度
最好、最坏情况时间复杂度
// n表示数组array的长度int find(int[] array, int n, int x) {int i = 0;int pos = -1;for (; i < n; ++i) {if (array[i] == x) pos = i;}return pos;}
上面 这段代码的复杂度是 O(n),其中,n 代表数组的长度
int find(int[] array, int n, int x) {int i = 0;int pos = -1;for (; i < n; ++i) {if (array[i] == x) {pos = i;break; //加入了break}}return pos;}
上边的代码 如果数组中第一个元素正好是要查找的变量 x,那就不需要继续遍历剩下的 n-1 个数据了,那时间复杂度就是 O(1)。
但如果数组中不存在变量 x,那我们就需要把整个数组都遍历一遍,时间复杂度就成了 O(n)。所以,不同的情况下,这段代码的时间复杂度是不一样的。
最好情况时间复杂度就是,在最理想的情况下,执行这段代码的时间复杂度
最坏情况时间复杂度就是,在最糟糕的情况下,执行这段代码的时间复杂度
平均情况时间复杂度
// n表示数组array的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break; //加入了break
}
}
return pos;
}
假设在数组中与不在数组中的概率都为 1/2。
另外,要查找的数据出现在 0~n-1 这 n 个位置的概率也是一样的,为 1/n。
所以,根据概率乘法法则,要查找的数据出现在 0~n-1 中任意位置的概率就是 1/(2n)
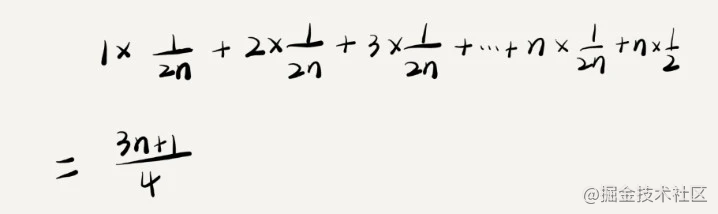
这个值就是概率论中的加权平均值,也叫作期望值,
所以平均时间复杂度的全称应该叫加权平均时间复杂度或者期望时间复杂度。
用大 O 表示法来表示,去掉系数和常量,这段代码的加权平均时间复杂度仍然是 O(n)。
大多数情况下,我们并不需要区分最好、最坏、平均情况时间复杂度三种情况
只有同一块代码在不同的情况下,时间复杂度有量级的差距,我们才会使用这三种复杂度表示法来区分
均摊时间复杂度
摊还分析法,通过摊还分析得到的时间复杂度我们起了一个名字,叫均摊时间复杂度。
// array表示一个长度为n的数组// 代码中的array.length就等于nint[] array = new int[n];int count = 0;void insert(int val) {if (count == array.length) {int sum = 0;for (int i = 0; i < array.length; ++i) {sum = sum + array[i];}array[0] = sum;count = 1;}array[count] = val;++count;}
这段代码实现了一个往数组中插入数据的功能。
当数组满了之后,也就是代码中的 count == array.length 时,我们用 for 循环遍历数组求和,并清空数组,将求和之后的 sum 值放到数组的第一个位置
然后再将新的数据插入。但如果数组一开始就有空闲空间,则直接将数据插入数组
最理想的情况下,数组中有空闲空间,我们只需要将数据插入到数组下标为 count 的位置就可以了,所以最好情况时间复杂度为 O(1)
最坏的情况下,数组中没有空闲空间了,我们需要先做一次数组的遍历求和,然后再将数据插入,所以最坏情况时间复杂度为 O(n)
平均时间复杂度是O(1): 假设数组的长度是 n,根据数据插入的位置的不同,我们可以分为 n 种情况,每种情况的时间复杂度是 O(1)。除此之外,还有一种“额外”的情况,就是在数组没有空闲空间时插入一个数据,这个时候的时间复杂度是 O(n)。而且,这 n+1 种情况发生的概率一样,都是 1/(n+1)。所以,根据加权平均的计算方法,我们求得的平均时间复杂度就是:
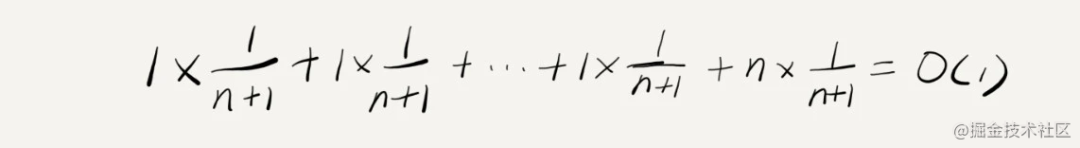
O(n) 的插入操作 就是 最坏的情况下 求和清空插入 O(1) 的插入操作 就是 最理想的情况下 直接插入
每一次 O(n) 的插入操作,都会跟着 n-1 次 O(1) 的插入操作,所以把耗时多的那次操作均摊到接下来的 n-1 次耗时少的操作上,均摊下来,这一组连续的操作的均摊时间复杂度就是 O(1),这就是均摊分析的大致思路
在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度就等于最好情况时间复杂度。
// 全局变量,大小为10的数组array,长度len,下标i。int array[] = new int[10];int len = 10;int i = 0;// 往数组中添加一个元素void add(int element) {if (i >= len) { // 数组空间不够了// 重新申请一个2倍大小的数组空间int new_array[] = new int[len*2];// 把原来array数组中的数据依次copy到new_arrayfor (int j = 0; j < len; ++j) {new_array[j] = array[j];}// new_array复制给array,array现在大小就是2倍len了array = new_array;len = 2 * len;}// 将element放到下标为i的位置,下标i加一array[i] = element;++i;}
转自:https://juejin.cn/post/7001810638703951902