
NAM: 一种新的注意力计算方式,无需额外的参数 | 代码开源
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
导读
本文介绍了一种新的计算注意力的方式,相比于之前的注意力机制,无需额外的全连接,卷积等额外的计算和参数,直接使用BN中的缩放因此来计算注意力权重,并通过增加正则化项来进一步抑制不显著的特征。
代码:https://github.com/Christian-lyc/NAM
论文:https://arxiv.org/abs/2111.12419
摘要:本文提出一种基于归一化的注意力模块(NAM),可以降低不太显著的特征的权重,这种方式在注意力模块上应用了稀疏的权重惩罚,这使得这些权重在计算上更加高效,同时能够保持同样的性能。我们在ResNet和MobileNet上和其他的注意力方式进行了对比,我们的方法可以达到更高的准确率。
1、介绍
注意力机制在近年来大热,注意力机制可以帮助神经网络抑制通道中或者是空间中不太显著的特征。之前的很多的研究聚焦于如何通过注意力算子来获取显著性的特征。这些方法成功的发现了特征的不同维度之间的互信息量。但是,缺乏对权值的贡献因子的考虑,而这个贡献因子可以进一步的抑制不显著的特征。因此,我们瞄准了利用权值的贡献因子来提升注意力的效果。我们使用了Batch Normalization的缩放因子来表示权值的重要程度。这样可以避免如SE,BAM和CBAM一样增加全连接层和卷积层。这样,我们提出了一个新的注意力方式:基于归一化的注意力(NAM)。
2、方法
我们提出的NAM是一种轻量级的高效的注意力机制,我们采用了CBAM的模块集成方式,重新设计了通道注意力和空间注意力子模块,这样,NAM可以嵌入到每个网络block的最后。对于残差网络,可以嵌入到残差结构的最后。对于通道注意力子模块,我们使用了Batch Normalization中的缩放因子,如式子(1),缩放因子反映出各个通道的变化的大小,也表示了该通道的重要性。为什么这么说呢,可以这样理解,缩放因子即BN中的方差,方差越大表示该通道变化的越厉害,那么该通道中包含的信息会越丰富,重要性也越大,而那些变化不大的通道,信息单一,重要性小。
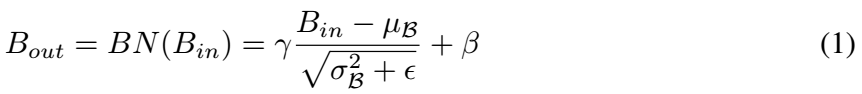
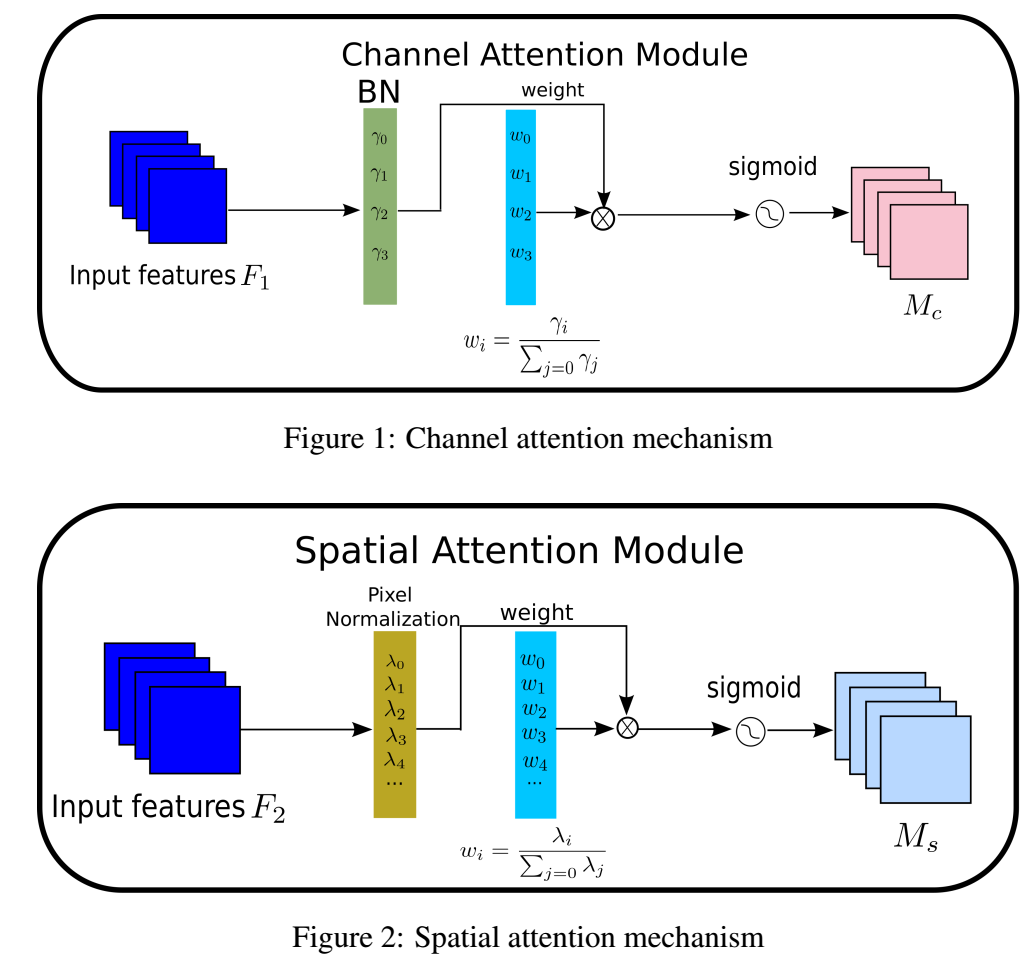
因此,通道注意力子模块如图1,式(2),用表示最后得到的输出特征,γ是每个通道的缩放因子,因此,每个通道的权值可以得到,如果对空间中的每个像素使用同样的归一化方法,就可以得到空间注意力的权重,式(3),就叫做像素归一化。像素注意力见图2,输出为。
为了抑制不重要的特征,我们在损失函数中加入了一个正则化项,如(4)式,
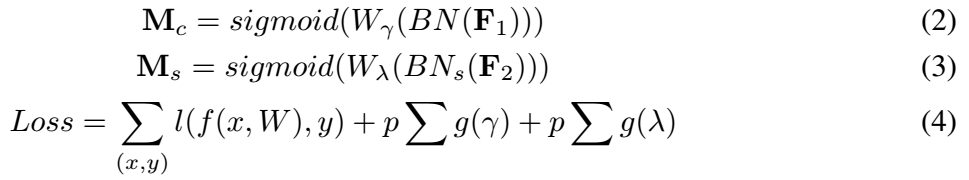
3、实验
我们将NAM和SE,BAM,CBAM,TAM在ResNet和MobileNet上,在CIFAR100数据集和ImageNet数据集上进行了对比,我们对每种注意力机制都使用了同样的预处理和训练方式,对比结果表示,在CIFAR100上,单独使用NAM的通道注意力或者空间注意力就可以达到超越其他方式的效果。在ImageNet上,同时使用NAM的通道注意力和空间注意力可以达到超越其他方法的效果。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
