
LLaMA 2大模型开源世界的安卓与微调项目推荐
LLaMA全称为“Large Language Model Meta AI”,即Meta大型语言模型,其参数量从70亿到650亿不等,当参数越大时,模型所占用的空间就越多,运行时所消耗的算力也就越大。在 LLaMA2 模型发布的第二天,就做了 Docker 支持。LLaMA2开源base模型的一个作用是让优秀的你为他的大模型做优化,为人类做贡献。
此次 Meta 发布的 Llama 2 模型系列包含 70 亿、130 亿和 700 亿三种参数模型。340 亿参数的估计由于安全性问题尚未发布。
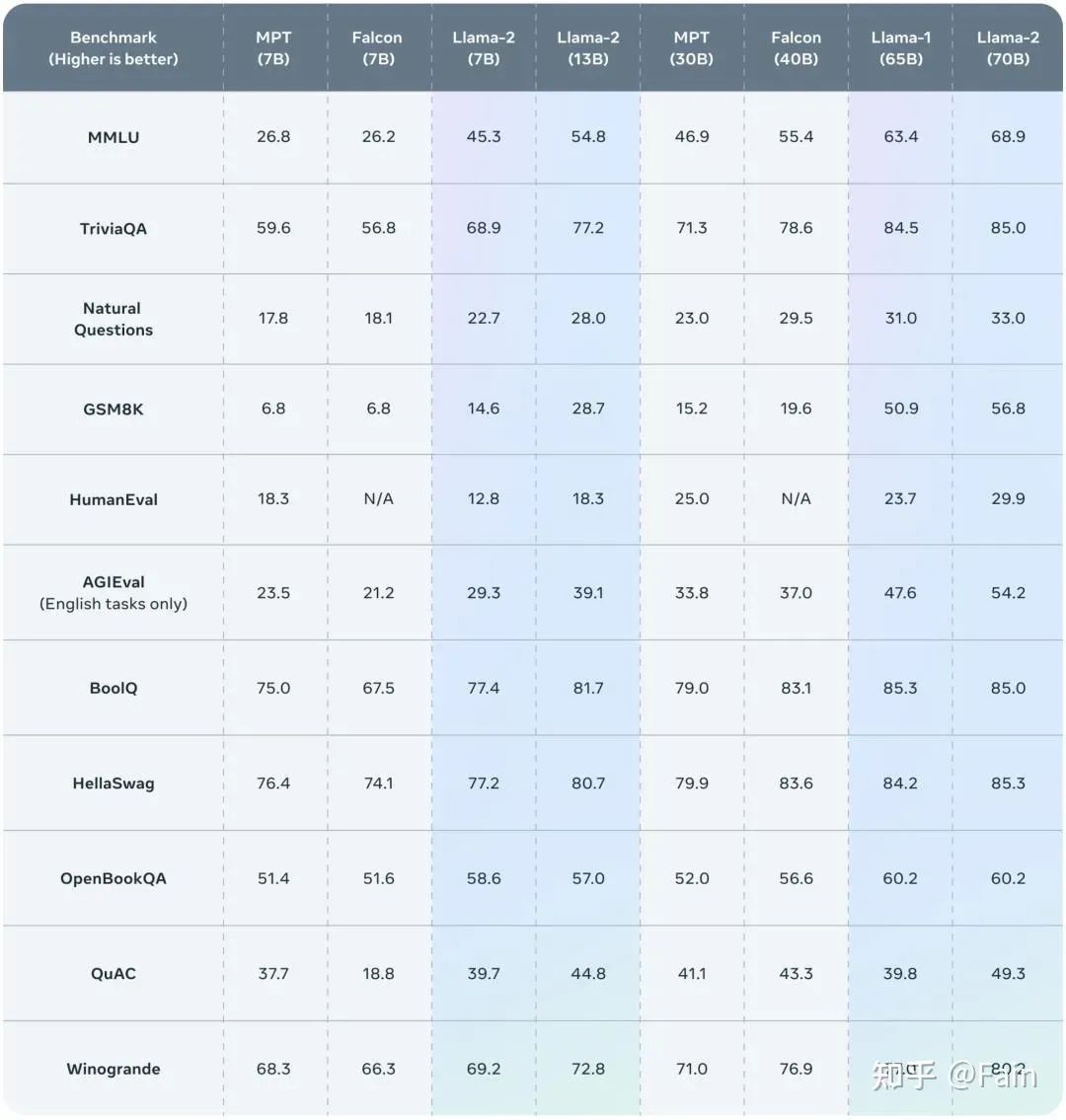
对比LLaMA 1
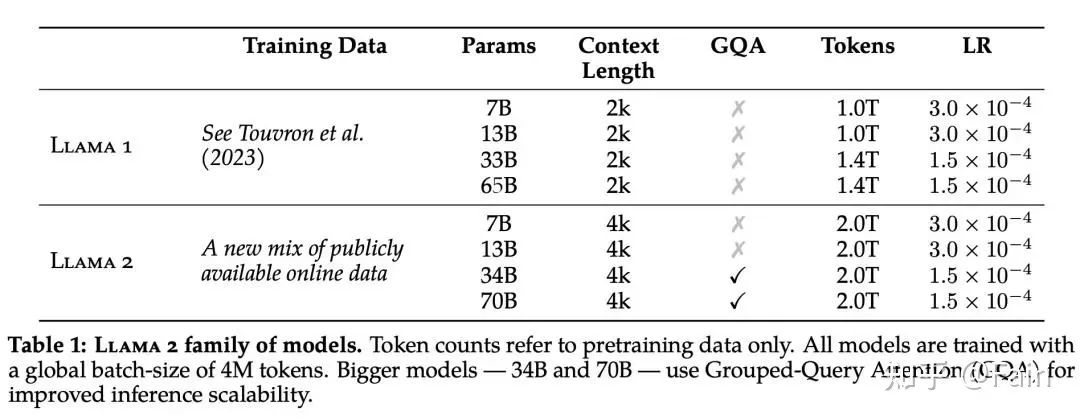
Llama 1、Llama 2 基础模型、MPT(MosaicML)和 Falcon 等开源模型在标准学术基准上的结果。
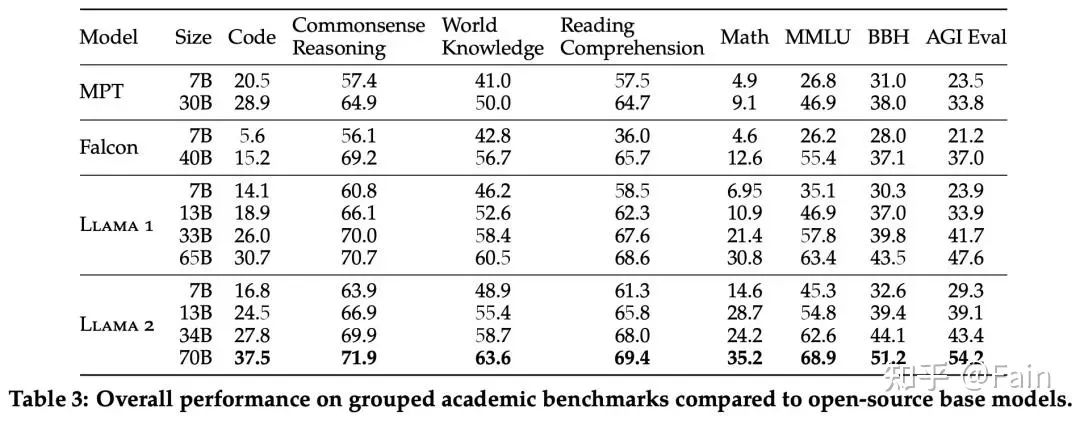
Llama 2 70B 的结果与闭源模型进行了比较

llama.cpp
Georgi Gerganov开发的llama.cpp的主要目标就是在MacBook上使用4-bit量化运行大型语言模型。将LLaMA-7B从13GB减少到3.9GB、LLaMA-13B从24GB减少到7.8GB以下。按照作者给出的数据,其在 M1 MacBook Pro 上运行 LLaMA-7B 模型时,推理过程每个词(token)耗时约 60 毫秒,换算每秒十多词。
Baby LLaMA 2
OpenAI科学家Andrej Karpathy,一周末训练微型LLaMA 2,并移植到C语言,这个项目的灵感正是来自llama.cpp。训练代码来自之前他自己开发的nanoGPT,并修改成LLaMA 2架构。在MacBook Air M1 CPU上单线程用fp32精度以每秒18个token的速度生成故事样本。接着使用最高级别编译方式-O3,使用量化后的模型,将MacBook Air M1上的每秒处理token数增加到了98。
项目扩展:
llama.cpp的作者Georgi Gerganov搞出了直接在浏览器里运行的版本;
Alex Volkov甚至做到了在GPT-4代码解释器里跑Baby LLaMA 2。
## Baby LLaMA 2 使用流程
## 下载在TinyStories数据集上训练的这个15M参数模型(约58MB),并将其放入目录out:
wget https://karpathy.ai/llama2c/model.bin -P out
## 编译并C代码:
gcc -O3 -o run run.c -lm
## 运行
./run out/model.binLLaMA-2-chat
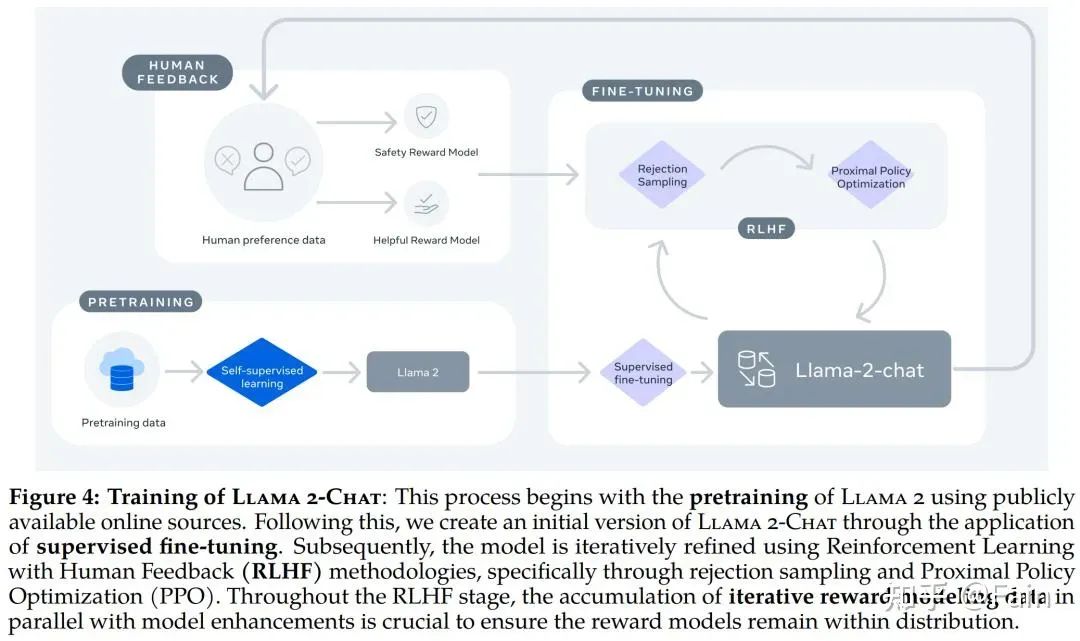
LLaMA-2-chat 目前具备了安全做的太强,且不具备中文能力。下图是Llama 2-Chat 的训练 pipeline。
下图是Llama 2-Chat 与其他开源和闭源模型在安全性人类评估上的结果

微调项目
llama-recipes是Meta开源的项目,可以微调LLaMA-2。
Firefly开源中文大模型项目,支持对LLaMA-2进行微调