
MQ那点破事!消息丢失、重复消费、消费顺序、堆积、事务、高可用....
大家好,我是 Tom哥~
马上要开启国庆小长假了,祝大家节日快乐,吃喝玩乐走起~
为了便于大家查找问题,了解全貌,整理个目录,我们可以快速全局了解关于消息队列,面试官一般会问哪些问题。
本篇文章的目录:
消息队列的应用场景?
答案:1、异步处理 2、流量削峰填谷 3、应用解耦 4、消息通讯
异步处理。将一个请求链路中的非核心流程,拆分出来,异步处理,减少主流程链路的处理逻辑,缩短RT,提升吞吐量。如:注册新用户发短信通知。 削峰填谷。避免流量暴涨,打垮下游系统,前面会加个消息队列,平滑流量冲击。比如:秒杀活动。生活中像 电源适配器也是这个原理。应用解耦。两个应用,通过消息系统间接建立关系,避免一个系统宕机后对另一个系统的影响,提升系统的可用性。如:下单异步扣减库存 消息通讯。内置了高效的通信机制,可用于消息通讯。如:点对点消息队列、聊天室。
常用的消息框架有哪些?
答案:ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaQ,RocketMQ、Pulsar 等
MQ技术选型?
答案:对比了 Kafka、RocketMQ 、Pulsar 三个框架,时耗、吞吐量、可靠性、事务、副本同步策略、多租户、动态扩容、故障恢复等评估指标。详细内容,参考 为什么放弃Kafka,选择Pulsar?
消息模型有哪些?
答案:1、点对点模式 2、发布/订阅模式
如何保证 MQ 消息不丢失?
答案:在了解消息中间件的运作模式后,主要从三个方面来考虑这个问题:
1、生产端,不丢失消息 2、MQ服务端,存储本身不丢失消息 3、消费端,不丢失消息 详细内容,参考 硬核 | Kafka 如何解决消息不丢失?
如何解决消息的重复消费?
答案:生产端为了保证消息发送成功,可能会重复推送(直到收到成功ACK),会产生重复消息。但是一个成熟的MQ Server框架一般会想办法解决,避免存储重复消息(比如:空间换时间,存储已处理过的message_id),给生产端提供一个幂等性的发送消息接口。
但是消费端却无法根本解决这个问题,在高并发标准要求下,拉取消息+业务处理+提交消费位移需要做事务处理,另外消费端服务可能宕机,很可能会拉取到重复消息。
所以,只能业务端自己做控制,对于已经消费成功的消息,本地数据库表或Redis缓存业务标识,每次处理前先进行校验,保证幂等。
如何保证 MQ消息是有序的?
答案:有些业务有上下文要求,比如:电商行业的下单、付款、发货、确认收货,每个环节都会发送消息。而消费端拉取并消费消息时,也是希望按正常的状态机流程进行。所以对消息就有了顺序要求。解决思路:
1、该topic强制采用一个分区,所有消息放到一个队列里,这样能达到全局顺序性。但是会损失高并发特性。 2、局部有序,采用路由机制,将同一个订单的不同状态消息存储在一个分区 partition,单线程消费。比如Kafka就提供了一个接口扩展org.apache.kafka.clients.Partitioner,方便开发人员按照自己的业务场景来定制路由规则。详细内容,参考 面试官问:如何保证 MQ消息是有序的?
消息堆积如何处理?
答案:主要是消息的消费速度跟不上生产速度,从而导致消息堆积。解决思路:
1、可能是刚上线的业务,或者大促活动,流量评估不到位,这时需要增加消费组的机器数量,提升整体消费能力 2、也可能是消费端的问题,正常情况,一条消息处理需要10ms,但是优化不到位或者线上bug,现在要500ms,那么消费端的整体处理速度会下降50倍。这时,我们就要针对性的排查业务代码。Tom哥之前带的团队就有小伙伴出现这个问题,当时是数据库的一条sql没有命中索引,导致单条消息处理耗时拉长,进而导致消息堆积,线上报警,不过凭我们丰富的经验,很快就定位解决了。
如何保证数据一致性问题?
答案:为了解耦,引入异步消息机制。先进行本地数据库操作,处理成功后,再发送MQ消息,由消费端进行后续操作。比如:电商订单下单成功后,要通知扣减库存。
这两者一定要保证事务操作,否则就会出现数据不一致问题。这时候,我们就需要引入事务消息来解决这个问题。
另外,在消费环节,也可能出现数据不一致情况。我们可以采用最终一致性原则,增加重试机制。
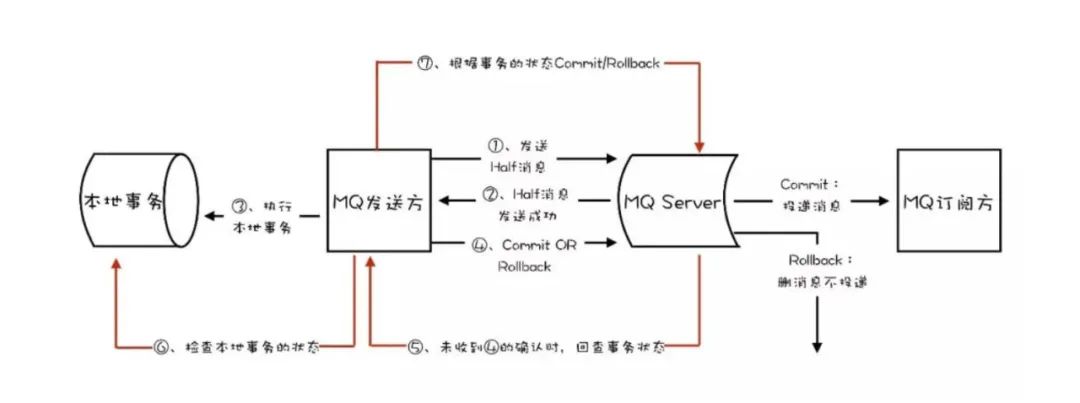
事务消息是如何实现?
答案:
1、生产者先发送一条半事务消息到MQ 2、MQ收到消息后返回ack确认 3、生产者开始执行本地事务 4、if 本地事务执行成功,发送commit到MQ;失败,发送rollback 5、如果MQ⻓时间未收到生产者的二次确认commit或rollback,MQ对生产者发起反向回查 6、生产者查询事务执行最终状态 7、根据查询事务状态,再次提交二次确认
MQ框架 如何实现高吞吐量?
答案:
1、消息的批量处理 2、消息压缩,节省传输带宽和存储空间 3、零拷贝 4、磁盘的顺序写入 5、page cache 页缓存,由操作系统异步将缓存中的数据刷到磁盘,以及高效的内存读取 6、分区设计,一个逻辑topic下面挂载N个分区,每个分区可以对应不同的机器消费消息,并发设计。
Kafka 为什么不支持读写分离?
答案:我们知道,生产端写入消息、消费端拉取消息都是与leader 副本交互的,并没有像mysql数据库那样,master负责写,slave负责读。
这种设计主要是从两个方面考虑:
1、数据一致性。一主多从,leader副本的数据同步到follower副本有一定的延时,因此每个follower副本的消息位移也不一样,而消费端是通过 消费位移来控制消息拉取进度,多个副本间要维护同一个消费位移的一致性。如果引入分布式锁,保证并发安全,非常耗费性能。2、实时性。leader副本的数据同步到follower副本有一定的延时,如果网络较差,延迟会很严重,无法满足实时性业务需求。
综上考虑,读写操作都是针对 leader 副本进行的,而 follower 副本主要是用于数据的备份。
MQ框架如何做到高可用性?
答案:以Kafka框架为例,其他的MQ框架原理类似。
Kafka 由多个 broker 组成,每个 broker 是一个节点。你创建一个 topic,这个 topic 可以划分为多个 partition,每个 partition 存放在不同的 broker 上,每个 partition 存放一部分数据,每个 partition 有多个 replica 副本。
写的时候,leader 会负责把数据同步到所有 follower 上去,读的时候就直接读 leader 上的数据即可。
如果某个 broker 宕机了,没事儿,那个 broker 上面的 partition 在其他机器上都有副本,此时会从 follower 中重新选举一个新的 leader 出来,大家继续读写那个新的 leader 即可。这就是所谓的高可用性。
更多内容,可以参考 关于消息队列,面试官一般都会问哪些?
关于Kafka,面试官一般喜欢考察哪些问题?
答案:
消息压缩 消息解压缩 分区策略 生产者如何实现幂等、事务 Kafka Broker 是如何存储数据?备份机制 为什么要引入消费组? 详细内容,参考之前写的 聊聊 Kafka 那点破事!
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。