
这个 Python 库有必要好好学学
“
阅读本文大概需要 6 分钟。
在很多情况下,我们会有把 Python 对象进行序列化或反序列化的需求,比如开发 REST API,比如一些面向对象化的数据加载和保存,都会应用到这个功能。
这里看一个最基本的例子,这里给到一个 User 的 Class 定义,再给到一个 data 数据,像这样:
class User(object):
def __init__(self, name, age):
self.name = name
self.age = age
data = [{
'name': 'Germey',
'age': 23
}, {
'name': 'Mike',
'age': 20
}]
现在我要把这个 data 快速转成 User 组成的数组,变成这样:
[User(name='Germey', age=23), User(name='Mike', age=20)]
你会怎么来实现?
或者我有了上面的列表内容,想要转成一个 JSON 字符串,变成这样:
[{"name": "Germey", "age": 23}, {"name": "Mike", "age": 20}]
你又会怎么操作呢?
另外如果 JSON 数据里面有各种各样的脏数据,你需要在初始化时验证这些字段是否合法,另外 User 这个对象里面 name、age 的数据类型不同,如何针对不同的数据类型进行针对性的类型转换,这个你有更好的实现方案吗?
初步思路
之前我写过一篇文章这可能是 Python 面向对象编程的最佳实践,介绍过 attrs 和 cattrs 这两个库,它们二者的组合可以非常方便地实现对象的序列化和反序列化。
譬如这样:
from attr import attrs, attrib
from cattr import structure, unstructure
@attrs
class User(object):
name = attrib()
age = attrib()
data = {
'name': 'Germey',
'age': 23
}
user = structure(data, User)
print('user', user)
json = unstructure(user)
print('json', json)
运行结果:
user User(name='Germey', age=23)
json {'name': 'Germey', 'age': 23}
好,这里我们通过 attrs 和 cattrs 这两个库来实现了单个对象的转换。
首先我们要肯定一下 attrs 这个库,它可以极大地简化 Python 类的定义,同时每个字段可以定义多种数据类型。
但 cattrs 这个库就相对弱一些了,如果把 data 换成数组,用 cattrs 还是不怎么好转换的,另外它的 structure 和 unstructure 在某些情景下容错能力较差,所以对于上面的需求,用这两个库搭配起来并不是一个最优的解决方案。
另外数据的校验也是一个问题,attrs 虽然提供了 validator 的参数,但对于多种类型的数据处理的支持并没有那么强大。
所以,我们想要寻求一个更优的解决方案。
更优雅的方案
这里推荐一个库,叫做 marshmallow,它是专门用来支持 Python 对象和原生数据相互转换的库,如实现 object -> dict,objects -> list, string -> dict, string -> list 等的转换功能,另外它还提供了非常丰富的数据类型转换和校验 API,帮助我们快速实现数据的转换。
要使用 marshmallow 这个库,需要先安装下:
pip3 install marshmallow
好了之后,我们在之前的基础上定义一个 Schema,如下:
class UserSchema(Schema):
name = fields.Str()
age = fields.Integer()
@post_load
def make(self, data, **kwargs):
return User(**data)
还是之前的数据:
data = [{
'name': 'Germey',
'age': 23
}, {
'name': 'Mike',
'age': 20
}]
这时候我们只需要调用 Schema 的 load 事件就好了:
schema = UserSchema()
users = schema.load(data, many=True)
print(users)
输出结果如下:
[User(name='Germey', age=23), User(name='Mike', age=20)]
这样,我们非常轻松地完成了 JSON 到 User List 的转换。
有人说,如果是单个数据怎么办呢,只需要把 load 方法的 many 参数去掉即可:
data = {
'name': 'Germey',
'age': 23
}
schema = UserSchema()
user = schema.load(data)
print(user)
输出结果:
User(name='Germey', age=23)
当然,这仅仅是一个反序列化操作,我们还可以正向进行序列化,以及使用各种各样的验证条件。
下面我们再来看看吧。
更方便的序列化
上面的例子我们实现了序列化操作,输出了 users 为:
[User(name='Germey', age=23), User(name='Mike', age=20)]
有了这个数据,我们也能轻松实现序列化操作。
序列化操作,使用 dump 方法即可
result = schema.dump(users, many=True)
print('result', result)
运行结果如下:
result [{'age': 23, 'name': 'Germey'}, {'age': 20, 'name': 'Mike'}]
由于是 List,所以 dump 方法需要加一个参数 many 为 True。
当然对于单个对象,直接使用 dump 同样是可以的:
result = schema.dump(user)
print('result', result)
运行结果如下:
result {'name': 'Germey', 'age': 23}
这样的话,单个、多个对象的序列化也不再是难事。
经过上面的操作,我们完成了 object 到 dict 或 list 的转换,即:
object <-> dict
objects <-> list
验证
当然,上面的功能其实并不足以让你觉得 marshmallow 有多么了不起,其实就是一个对象到基本数据的转换嘛。但肯定不止这些,marshmallow 还提供了更加强大啊功能,比如说验证,Validation。
比如这里我们将 age 这个字段设置为 hello,它无法被转换成数值类型,所以肯定会报错,样例如下:
data = {
'name': 'Germey',
'age': 'hello'
}
from marshmallow import ValidationError
try:
schema = UserSchema()
user, errors = schema.load(data)
print(user, errors)
except ValidationError as e:
print('e.message', e.messages)
print('e.valid_data', e.valid_data)
这里如果加载报错,我们可以直接拿到 Error 的 messages 和 valid_data 对象,它包含了错误的信息和正确的字段结果,运行结果如下:
e.message {'age': ['Not a valid integer.']}
e.valid_data {'name': 'Germey'}
因此,比如我们想要开发一个功能,比如用户注册,表单信息就是提交过来的 data,我们只需要过一遍 Validation,就可以轻松得知哪些数据符合要求,哪些不符合要求,接着再进一步进行处理。
当然验证功能肯定不止这一些,我们再来感受一下另一个示例:
from pprint import pprint
from marshmallow import Schema, fields, validate, ValidationError
class UserSchema(Schema):
name = fields.Str(validate=validate.Length(min=1))
permission = fields.Str(validate=validate.OneOf(['read', 'write', 'admin']))
age = fields.Int(validate=validate.Range(min=18, max=40))
in_data = {'name': '', 'permission': 'invalid', 'age': 71}
try:
UserSchema().load(in_data)
except ValidationError as err:
pprint(err.messages)
比如这里的 validate 字段,我们分别校验了 name、permission、age 三个字段,校验方式各不相同。
如 name 我们要判断其最小值为 1,则使用了 Length 对象。permission 必须要是几个字符串之一,这里又使用了 OneOf 对象,age 又必须是介于某个范围之间,这里就使用了 Range 对象。
下面我们故意传入一些错误的数据,看下运行结果:
{'age': ['Must be greater than or equal to 18 and less than or equal to 40.'],
'name': ['Shorter than minimum length 1.'],
'permission': ['Must be one of: read, write, admin.']}
可以看到,这里也返回了数据验证的结果,对于不符合条件的字段,一一进行说明。
另外我们也可以自定义验证方法:
from marshmallow import Schema, fields, ValidationError
def validate_quantity(n):
if n < 0:
raise ValidationError('Quantity must be greater than 0.')
if n > 30:
raise ValidationError('Quantity must not be greater than 30.')
class ItemSchema(Schema):
quantity = fields.Integer(validate=validate_quantity)
in_data = {'quantity': 31}
try:
result = ItemSchema().load(in_data)
except ValidationError as err:
print(err.messages)
通过自定义方法,同样可以实现更灵活的验证,运行结果:
{'quantity': ['Quantity must not be greater than 30.']}
对于上面的例子,还有更优雅的写法:
from marshmallow import fields, Schema, validates, ValidationError
class ItemSchema(Schema):
quantity = fields.Integer()
@validates('quantity')
def validate_quantity(self, value):
if value < 0:
raise ValidationError('Quantity must be greater than 0.')
if value > 30:
raise ValidationError('Quantity must not be greater than 30.')
通过定义方法并用 validates 修饰符,使得代码的书写更加简洁。
必填字段
如果要想定义必填字段,只需要在 fields 里面加入 required 参数并设置为 True 即可,另外我们还可以自定义错误信息,使用 error_messages 即可,例如:
from pprint import pprint
from marshmallow import Schema, fields, ValidationError
class UserSchema(Schema):
name = fields.String(required=True)
age = fields.Integer(required=True, error_messages={'required': 'Age is required.'})
city = fields.String(
required=True,
error_messages={'required': {'message': 'City required', 'code': 400}},
)
email = fields.Email()
try:
result = UserSchema().load({'email': 'foo@bar.com'})
except ValidationError as err:
pprint(err.messages)
默认字段
对于序列化和反序列化字段,marshmallow 还提供了默认值,而且区分得非常清楚!如 missing 则是在反序列化时自动填充的数据,default 则是在序列化时自动填充的数据。
例如:
from marshmallow import Schema, fields
import datetime as dt
import uuid
class UserSchema(Schema):
id = fields.UUID(missing=uuid.uuid1)
birthdate = fields.DateTime(default=dt.datetime(2017, 9, 29))
print(UserSchema().load({}))
print(UserSchema().dump({}))
这里我们都是定义的空数据,分别进行序列化和反序列化,运行结果如下:
{'id': UUID('06aa384a-570c-11ea-9869-a0999b0d6843')}
{'birthdate': '2017-09-29T00:00:00'}
可以看到,在没有真实值的情况下,序列化和反序列化都是用了默认值。
这个真的是解决了我之前在 cattrs 序列化和反序列化时候的痛点啊!
指定属性名
在序列化时,Schema 对象会默认使用和自身定义相同的 fields 属性名,当然也可以自定义,如:
class UserSchema(Schema):
name = fields.String()
email_addr = fields.String(attribute='email')
date_created = fields.DateTime(attribute='created_at')
user = User('Keith', email='keith@stones.com')
ser = UserSchema()
result, errors = ser.dump(user)
pprint(result)
运行结果如下:
{'name': 'Keith',
'email_addr': 'keith@stones.com',
'date_created': '2014-08-17T14:58:57.600623+00:00'}
反序列化也是一样,例如:
class UserSchema(Schema):
name = fields.String()
email = fields.Email(load_from='emailAddress')
data = {
'name': 'Mike',
'emailAddress': 'foo@bar.com'
}
s = UserSchema()
result, errors = s.load(data)
运行结果如下:
{'name': u'Mike',
'email': 'foo@bar.com'}
嵌套属性
对于嵌套属性,marshmallow 当然也不在话下,这也是让我觉得 marshmallow 非常好用的地方,例如:
from datetime import date
from marshmallow import Schema, fields, pprint
class ArtistSchema(Schema):
name = fields.Str()
class AlbumSchema(Schema):
title = fields.Str()
release_date = fields.Date()
artist = fields.Nested(ArtistSchema())
bowie = dict(name='David Bowie')
album = dict(artist=bowie, title='Hunky Dory', release_date=date(1971, 12, 17))
schema = AlbumSchema()
result = schema.dump(album)
pprint(result, indent=2)
这样我们就能充分利用好对象关联外键来方便地实现很多关联功能。
以上介绍的内容基本算在日常的使用中是够用了,当然以上都是一些基本的示例,对于更多功能,可以参考 marchmallow 的官方文档:https://marshmallow.readthedocs.io/en/stable/,强烈推荐大家用起来。
广而告之
对了,今天给大家推荐个好福利。
现在疫情基本算是控制住了,国内的一些企业有的已经复工,有的还在 Work From Home,在特殊时期,企业复工复产多有不易,惟有多方合力,才能携手企业共渡难关。华为云基础服务携手云容器外加两位神秘重磅嘉宾加入开年采购季,助力企业共克时艰。
远程办公、视频会议、远程教育、远程医疗有了这些服务的加持,不再是问题。另外这活动送的东西还真不少,送手机、送平板、送手表、送音箱,大家赶紧来上车吧!
华为云开年采购季来了!送8888元企业助力礼包,云服务产品低至1折云服务器79元/年,更有WeLink免费办公!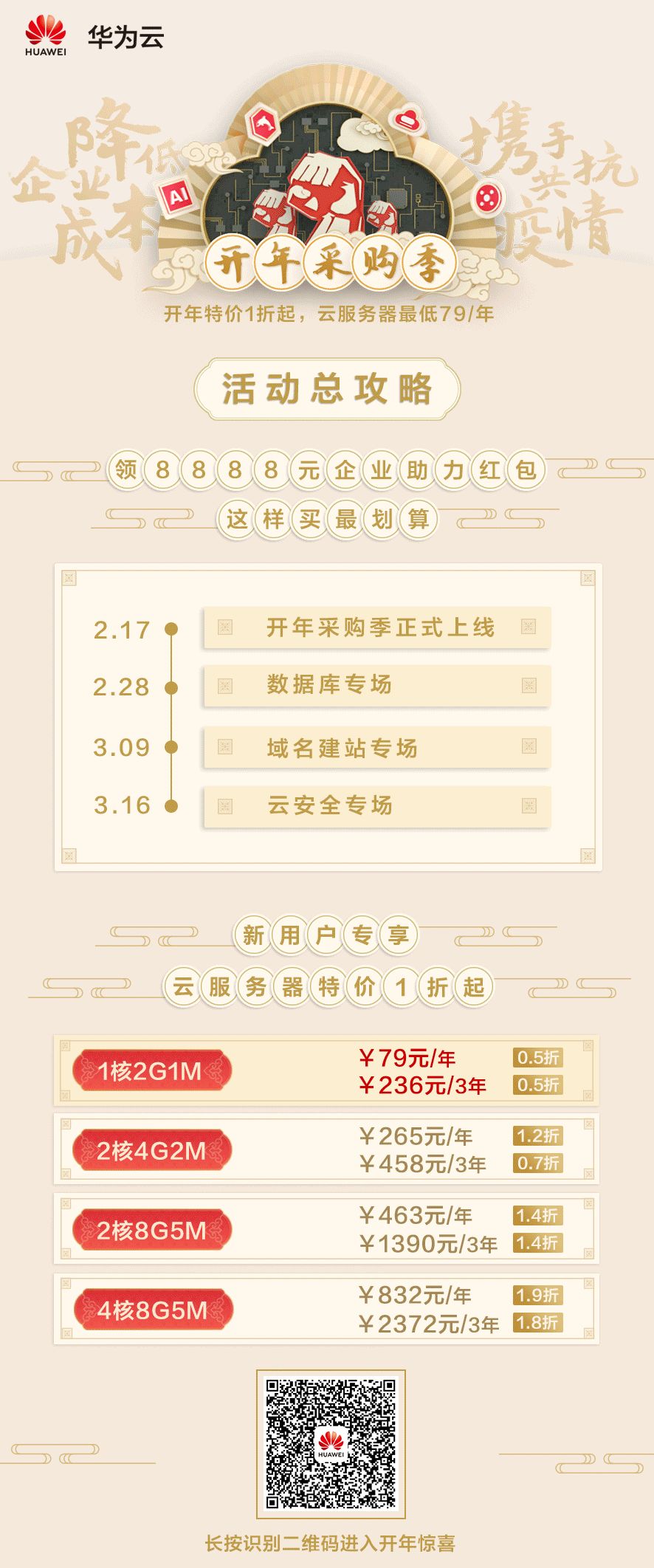



![]() 点击“阅读原文”,立即领取助力礼包节流增效
点击“阅读原文”,立即领取助力礼包节流增效