
Google Brain发布多任务模型框架TAG,少训2000个小时也能sota!
新智元报道
新智元报道
来源:Google AI
编辑:LRS
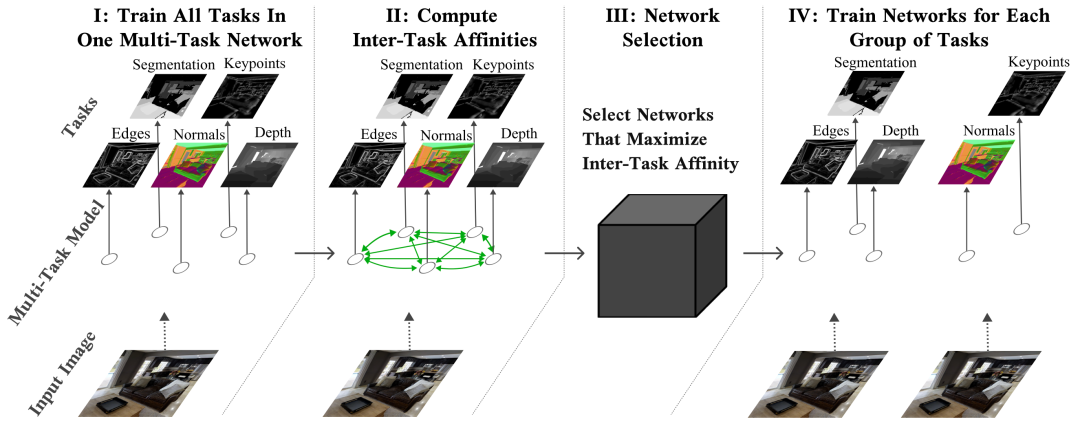
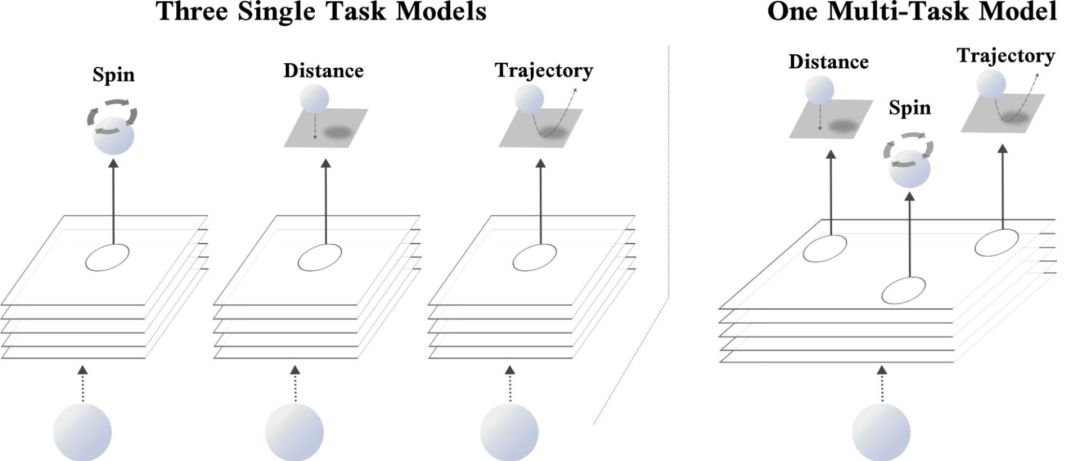
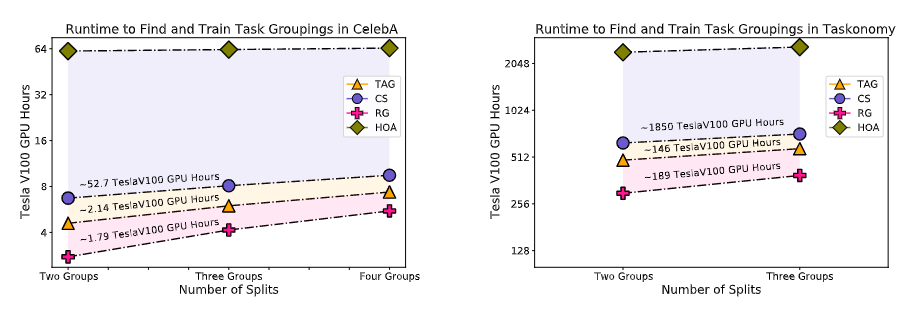
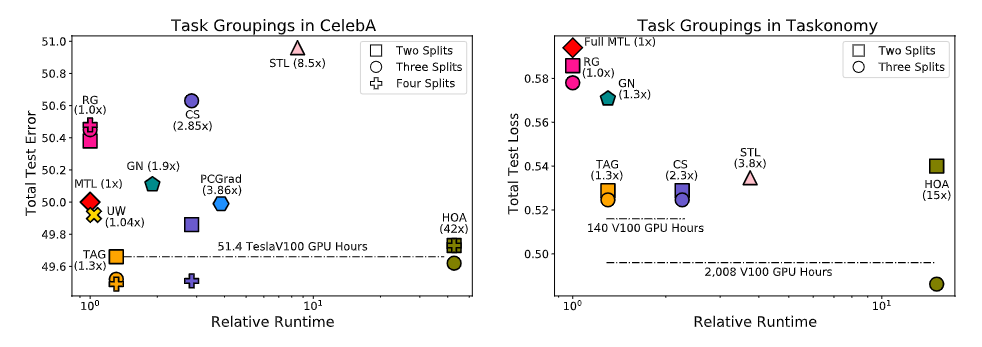
【新智元导读】对于多任务场景来说,最大的难点就在于如何找到多个任务之间相互关联的部分。Google Brain团队在NeurIPS 2021上发表了一篇论文,提出一个亲和力指标,能将训练速度提升32倍,直接少训练2000个小时,相当于省了6200美元!


参考资料:
https://ai.googleblog.com/2021/10/deciding-which-tasks-should-train.html

评论