
【经验】刚读硕士怎么感觉学机器学习和深度学习越学越不懂?
有同学问:研一,在学机器学习和深度学习,为什么感觉越学越不会,怎么解决这个问题?
我搜集了一些意见和建议,供参考。
高赞回答一
作者:曲終人不散丶
来源:知乎
我的研一我记得是先找了一本比较薄的,通俗易懂的深度学习书,内容浅尝辄止,但很基础,主要介绍全连接层,反向传播机制,然后过渡到CNN,池化,批量梯度下降,就这些了。
之后我又看了一本Tensorflow深度学习,代码不看,只看内容。里面也大同小异,不过介绍更细了些,比如AlexNet,
GoogleNet, ResNet等等,还有具体的一些任务。
之后我就不看了,我就去看我最感兴趣的方向(CV的一个子领域)的最SOTA的算法的由来,CSDN上文章很多,多看几个。刚接触一个领域,起码要知道这个领域目前最有影响力的算法的历史及其发展吧?然后逐渐拓宽文献面,个人比较喜欢看一些偏理论推广的东西,特殊推广至一般是常用的创新套路。举几个典型的例子,比如目标检测的Soft-NMS是传统NMS的推广,SENet也是一种推广,Group
Normalization是BN和IN的结合,还有二阶池化策略是比之一阶池化更好的池化。
研一下我就看了少说七十篇文献,都是CVPR, ECCV,
ICCV的文章。然后创新点就很自然地出来了。看多了,多思考,自然就会发现目前尚未解决的问题,以及前人方法的次优性。这里提一句,不同领域的专家,哪怕同为CV但却是不同子领域的人,二者最大的差别不是别的,就是文献量。
然后我就想解决方法啊(其实中国的学生解决问题的能力都很强,就看你能不能想到问题),特别是985研究生,不管大家承认与否,也是中国最优秀的一批人了。
其实最开始我也就抓住了一篇CVPR的一个小问题,随后想了解决方案,利用本科学的数学分析这样的思维(要不怎么说考研要考数学一呢?)进行深入的打磨和推敲,其实问题都不难,这些问题不过都是有限维函数,及其导数(梯度),极限等知识有关。
然后我就得想办法编程了啊,我之前也只会matlab。没试过python,连环境都不会装。
最后磨蹭了一段时间,终于装好了环境,跑通了一遍baseline。开始找别人代码上我应该要改的地方在哪里。
接着就照着别人的代码改,遇到不会就终端输出啊,看一看tensor的size啊,具体的tensor运算啊,这些东西不超过高等代数的范畴(或线性代数)。也得亏是我这个解决方法不涉及大的改动,比如修改网络之类的,于是就做实验吧。
边做实验的同时,也与一起合作的同学交流想法,于是就酝酿出来更好的方法,更进了一步。PS:
论文的层次感也是挺重要的。比起那种CVPR上见到过的一个算法一篇文章,或者一个公式写一篇文章,如果你的文章能有2~3个创新点,无疑是好事。
可能是我个人追求完美的原因吧,加之我做科研具备严谨素养,我会仔细推敲,对别人的repo我训出什么结果就是什么结果,训的高我论文就用训的高的,低了那就是低了。
于是研二就中了一篇一作A会。
总结来说,
首先,不要着急练代码,于我而言就是盲人摸象。
第二,基础知识仅了解那些能助于你理解论文的部分就好了,难道你还指着把周志华的机器学习都看完才做研究吗?书只是一种工具,一份参考,一本字典,不会带给你任何的创新启发。
第三,先从你领域内的最经典的论文开始(可能有好几种不同的经典模型),统统了解来龙去脉。
第四,最经典了解完后,就开始开枝散叶式地了解模型中的每一个细节,因为每一个细节可能都有至少一篇的顶会论文在其中。
第五,不要死磕英语。CSDN,公众号,知乎,有道划线翻译,都会加快你提炼论文核心的速度。
第六,量变产生质变。当你论文阅读量达到五十篇后,基本对这个领域有个不错的认识了,多个改进的算法有何特点,有何区别,你的心中也有了框架,此时产生idea也不奇怪。我目前总阅读量也就180篇左右
第七,不要畏惧编程。你只有去适应它,习惯了之后,编程都是小意思。
第八,严谨性,不得意于眼前的成功。只有认真打磨,深入挖掘一项工作,才有可能做出真正solid的工作。
第九,能吃苦。现在的AI方向更新速度太快,你必须与别人拼速度,包括合作者,硬件设备。你知道何恺明为何能在2017的ICCV上大展手脚吗?因为他与他的好朋友Ross
Girshick两个人加起来正好能工作满24小时。其实我有时也是非常羡慕,如果能有一个人也与我工作满24小时该多好。我醒了,他去睡了,我睡了他接着干了。当然这个也只能在大厂或者知名高校这样的地方可能见到了,那么你未来如何进这样的地方?只有取决于你的现在。设备不多,自然就要充分利用好每一秒,我的实验由于不是恰好24小时的整数倍能做完的,所以经常需要半夜爬起来去测试,去开下一个实验。又或者我一个实验凌晨一点出结果,我也要熬到那时候做完才回寝室。时间都是挤出来的。当然也不用太累,做实验期间,你该上课上课,该打球打球,该看电影看电影,该约火锅约火锅,生活要丰富起来,精神才能丰富,锻炼身体我也是没有落下,羽毛球乒乓球三天不打就手痒。
第十,真心的热爱。只有你热爱了,你才会乐此不疲,甚至以此为一生的职业追求。迈克尔杰克逊老时可以说自己一生热爱的是音乐与舞蹈,赵忠祥老时也可以说自己一生热爱的是主持与播音事业,我不希望我老时谈及自己热爱什么的时候,发现自己说不出来云云。可见一个人能一辈子从事自己所热爱的事业将是多么不容易也是多么幸福的一件事,年轻人就该把握好,把力往最擅长的点上使。
当然了,最关键的是你要有拼劲。多少次我在实验室看到美轮美奂的日出,多少次我大半夜顶着寒风骑电动车回寝室我就不说了。可能这对于身处大牛组的人来说感受会低一些,但对于我这种孤军奋战的人来说,所拥有的资源就是双GPU显卡,感触会非常深,但同时对我个人能力的锤炼也无疑会更好,无论是科研能力,科研精神,还是工程代码能力。
说了这么多突然感慨万千,其实当你看到CMT上“Accept”这个词时,一切的苦痛也都全然消失了,转而来临的是无尽的欢笑与成功的泪水……
——————————————————
感觉看的人挺多的,那就再更新一波,有关论文写作。
其实很多公众号如SCI,上面都会有详细的论文写作教程,都可以看看,但我当时写论文却没有依赖这些教程。
写论文的关键在于如何组织结构,如何写好一个故事。哪些是不得不说的废话,哪些才是真正的核心论点。初高中时我们都一直锻炼过如何写好一篇议论文,这时候就有用武之地了。大致可总结为自圆其说四个字。
首先,你得有相当量的文献阅读量,这样你在写论文时,下笔将非常有一种统领千军的感觉。前人的工作,目前研究的现状,别人都是如何解决问题的,却又留下了哪些问题,这些东西不通过看文献你是不会有足够深的理解和意识的。
如果你缺乏这方面意识,比如你只看了10篇文献,然后你相当天才也想出了绝佳的idea,并付出行动后成功了,此时你再面对文章,你将非常痛苦。这仅仅10篇的知识面,甚至只能让你写一章Proposed
Method。这时你该怎么办?基本上只能照搬别人论文里的句子,各个地方都借用一点,凑出一篇文章。
可是如果你有相当的文献储备量,写起来将轻松多了。首先你根本无需照搬别人的论文,你就像个音乐指挥家,用自己的话把这个故事写了出来。
我举个例子。
比如你解决的是目标检测领域某篇CVPR
2020的一个尚未解决的问题,你想了改进方案,成功在ResNet50下提高了性能1.5个百分点。
这时你无比兴奋地向导师汇报了成果,毕竟1.5个百分点可不是一个小数字了。
你要知道1.5个绝对百分点的提升,换做大牛组来做,可以必中A会,甚至oral。
那么你一个小白,该如何给这个小小的苗子一个适合它的家?
让我来告诉你大牛组的人会怎么做。首先,已知你在A模型的ResNet50上比baseline提高1.5个点,接着马上做ResNet101看看情况。如果你的提升是有理论依据,并且不太可能是偶然因素的话(1.5的提升基本不可能是偶然),那么R101多半也是提升1.5±0.8。
这下基本确定这个idea是有效可行了之后,开始尝试把改进方法移植到B模型,C模型(三个就够了)。让我们看看最终的实验表格,以提升最多的那个模型为主要的结果。ABC三个表,Ablation
study包括探究主干网络是否影响,超参数的敏感性实验,涉及改动网络的还需要考虑bflops,探究是不是增加网络层数带来的提升。涉及降低推理速度的,还得探究这种牺牲大不大。
以上这些都是常见的Ablation。最好你在实验过程中能酝酿出第二个更好的改进方案。这样你在纵向上也能列出表格,这就是所谓的论文层次感。更有甚者,有人甚至可以一开始觉得想出的改进太成功了,却又想不出更好的方法,可以在baseline和你的方法之间找一个中间状态的方法,然后以这个中间状态方法为第一个创新点,接着针对这个创新的不足,提出第二个创新点(实际就是你最开始想的那个),自己改进自己,自己革新自己,说不定还能从中找出事物背后的深刻道理,无疑都会为你的文章增添色彩。
回到论文写作上来,假设你已经有了所有的主要实验和Ablation(当然实际上肯定是一边写一边做)。abstract,Introduction,related
work,这三大部分就是写故事的关键了。
套路一般是,先说大环境下本领域的发展,分类,极其对其他领域的作用。进而转到其中某某模块(你针对的模块)对整体的性能至关重要。该模块已被多个其他领域应用,如U,V,W(列出参考文献)。针对该模块,大家都使用的方法是Z,近十年来一直如此。后续针对传统方法Z的不足,近几年有学者提出了D方法(ECCV2017),用以改善XXXX。接着针对D方法的不足,又有人提出了E,解决了D的问题,比如提高D的速度,或者D的稳定性,或者是D的推广版本。E是相当经典的,这么多年以来成为了主导,可谓人尽皆知。最新的研究进展中,有学者还提出了F,
H等变体,分别考虑了XXXX,有的还应用在其他领域中。但是(关键来了),上述这些方法,都仅仅考虑了XXXX层面,因素。However,
we observed that......,they may suffer from……,they face the problem
of……这个地方最好需要你用一句神来之笔的观点说出这些方法的问题,从而让人眼前一亮,让人恍悟好像这些方法确实是这么一回事,甚至让人恍悟原来E方法能有提升是出于背后这么个原因。总之你若能总结到类似于这样的深刻道理,那基本上审稿人对你论文的看法就是very
novel。加之你的提升有1.5个点这么多,那么审稿人对你实验结果的看法也将是significant或very
convincing。
上述这些东西挑最关键的部分放在abstract,占1/3到1/2左右。然后全部内容放在Introduction,作为引入你的观点的背景故事。Introduction剩下两段,一段用来说明你的改进方法的大致流程,最后一段用以总结本文的贡献。还是那句话,只要你有足够的文献储备量,这些东西写起来信手拈来,几乎是畅所欲言,写的爽死。当然还需注意语言表达要客观,要尊重,还要犀利。
related work,分两种,一种是针对你改进点的相关工作,比如刚刚的传统方法以及D, E,
F,
H方法。还有一种没的写了就写大框架的工作,比如机器阅读理解方法,目标检测方法,图像去噪方法,3D重建方法(根据你的领域),算是一个汇总性的介绍。
高赞回答二
作者:机器学习入坑者
来源:知乎
研一刚入学,一定要“小步慢跑”,学一个算法就一定要学透(公式推导+代码编写),不要今天看一下SVM、明天瞅一眼MLP。
写代码能够学到东西,跑代码是学不到任何东西的。
从基本的算法开始,比如KNN,花上一周时间按照类似下面的流程进行实验:
(0)公式推理
(1)筛选数据
(2)模型搭建(编写代码)
(3)指标计算
(4)调参分析(不断优化)
(5)重新理解公式推理
按照上述步骤学完第一个算法以后,再以相同的过程学习第二个算法。对不同算法重复相同的实验流程,能让自己对模式识别那本书理解更深刻。
我认为从事深度学习最忌讳的就是“急”,python还没学好,就去学pytorch;pytorch还没学好,就去跑开源项目。编程基础和理论基础还没打好,就去看论文跑开源代码,时间都浪费在环境配置和版本兼容调试上面了。
美其名曰项目驱动学习,实际上就是浮土筑高台。研一基础不牢靠,研二很难静下心来弥补缺失的知识。然后就有趣了,研一整年没能学到扎实的技能,导致二年级做实验的时候举步维艰。在这种焦虑的情况下只能继续听从“项目驱动学习”这种策略,害怕组会、害怕导师催你。(我并非反对项目驱动学习,我反对的是没有ML或DL基础的情况下就搞项目)。
相反的,如果研一的基础非常扎实,天天写代码夯实实践基础,天天推导公式夯实理论基础。研二的时候就能水到渠成,自然就能把论文实验做的很好,磨刀不误砍柴工。
一步急,步步急,最后就只会跑别人代码调调参数,关掉github以后连一个基本的CNN分类pipeline都写不出来(数据清洗+数据读取+网络设计+损失选择+模型训练+指标计算+调优)。
粗略的读一读理论证明,然后找个开源代码跑一下,我认为这种方式真的学不好模式识别那门课。
补充:关于学习经历
如何系统型地学习深度学习?(https://www.zhihu.com/question/305745486/answer/557055667)
补充:关于pytorch
曾经写过一些pytorch的日志,包含数据采样、增强、模型搭建等等:
(https://zhuanlan.zhihu.com/c_1176057805353766912)
补充:关于书籍选择
if(good_at_math){choose("西瓜书");}else{choose("机器学习实战");}
补充:关于视频学习资料
吴恩达老师有两个视频课程,建议选择早期版本(好像是零几年),那个版本的数学论证比较完整。
高赞回答三
作者:匿名用户
来源:知乎
我认为在项目中学习机器学习和深度学习更加容易,主要是实际的例子会帮助你更好理解其中的思想和计算过程。越学越不会说明已经开始会一些东西了,实践之后可能明白更多东西。但是如果让我回到研一,我会选择放弃这个方向。
本人就读于一所中上的211学校,还有1个月就毕业了。研一时候我和楼主一样,一直在学习,自己也会找一些开源的项目,也参加过一些比赛,个别比赛成绩也说得过去。但是学校位置比较偏,导师资源不好,实验室不让出去实习等因素,我处于单打独斗阶段。找工作之前我已经能熟练推出各种主流机器学习公式,用Numpy写出大部分模型,在力扣等网站上刷了500+的题目。
刚入坑的时候,网上的各种行业前景的评价蒙蔽了我的双眼,我满怀自信的参加了2019年的秋招,结果以失败告终,ML、DL基础知识、手撕代码都没什么问题。参加招聘的所有公司中,只有腾讯告诉了我的不足之处,没有实习、没有论文。(很多大佬这时会说了,没有论文还想找算法工程师的职位,我只能告诉你们,实验室只有自己研究这个方向时,需要踩的坑多到无法想象)。华为的招聘我走的最远,但是终面被刷了,因为非科班,没办法这是事实。最后的最后,我去一家通信公司做软开去了。这也算比较好的结果吧。
简单总结一些招聘时候我都会什么了吧,ML基本模型的公式推导+numpy实现,DL的基础知识,CV领域自己手写过SSD、Faster
R-CNN、YOLO、retinanet这几种基本目标检测算法的全部代码。改进了Faster
R-CNN,但是没来得及出文章。参加了几次比赛,成绩一般,最好成绩是1000个队伍比赛的前20名。数据结构方面,力扣里的中等题基本思路都有,大部分能写出来,毕竟刷了500多个算法题。
我只想说如果是非985硕士,没法发论文,没法去实习,还是老老实实做些软开的项目吧,这些可能更有用。当然,如果你是大佬,就当我在放屁好了。
学这方面的知识还是别看书了,每天认认真真学会一种模型,从公式到代码,每个细节理清,你就可以说你会这个模型了。书上理论讲的很好,但是我认为找一些项目更能帮助你理解这些。如果是数学知识不会的话,就需要好好补习一下了,其实里面的数学知识不算难。
祝您学有所成。
没想到这么多评论和赞,谢谢知乎的大佬们。
学习机器学习和深度学习不要只关注项目上的东西,很多trick已经是很通用的了,很多优秀的公众号和文章已经分享了的差不多了,还有很多比赛大佬分享的竞赛经验,数据科学比赛决赛的PPT也是一个收集trick的途径。
个人认为:如果比赛成绩没进决赛或者项目没有落地,一般情况下是没什么价值的,除非基于这些能写出来文章。这个过程能收获到的也只有经验了。
如果出于找工作的考虑的话,非科班的大佬们一定一定要把CS基础打牢(我就是折在了这里,半年时间恶补了一番,受益匪浅)。绝对不要把python作为第一语言,C\C++或者java作为第一语言最好,这个很重要。机器学习的那些理论知识要非常熟悉,最起码要做到公式推导以及代码实现。
现在算法岗工作真的比较难找了,要有拿得出手的项目、比赛、论文,基础知识牢固,编程能力极强。满足这些条件才能入得了面试官的眼吧。
大佬加油,坚持学习,虽然这几年算法岗的工作就是独木桥,但是相应的,网上公开的知识也越来越多了,认真学习的人一定能通过这个独木桥。
评论区的大佬们就不要问我去哪工作或者面试经验什么的了,我就是一个渣渣,我的这些信息对你们来说也没什么参考价值,有很多有价值的经历值得学习。而且我水平确实一般,找不到算法岗也正常,趁着现在更强迫自己学习基础知识,这样对我来说也很好。
总结
作者:黄海广
学习路线可以参考这篇(适合初学者入门人工智能的路线及资料下载)
其实以上三位大佬把问题都回答得差不多了。再说说我的看法:
首先,务必要学基础知识,学好数学,会手写算法,最好能用Python复现下算法(主要用Numpy实现),不会手写算法没关系,看懂别人写的代码就行,依样画葫芦改改。
最重要的一点:多记笔记!!!
可以看看我怎么记笔记(节选):
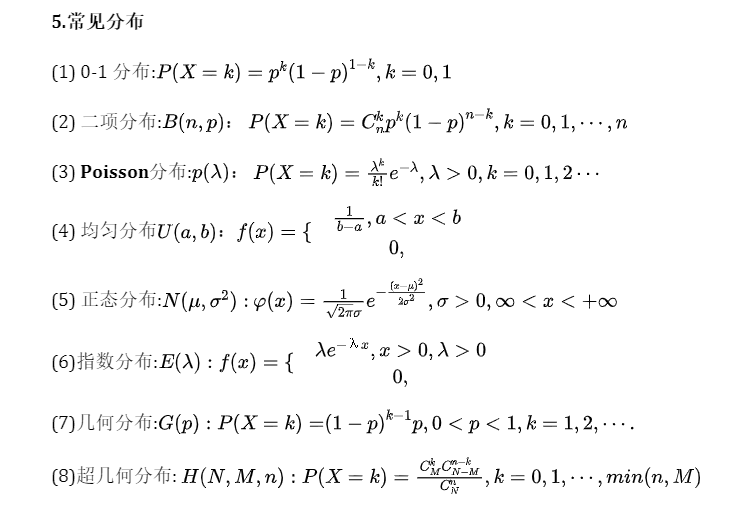
图:我的笔记,好像是考研时候弄的,机器学习也用到
其次,多看论文,看一篇论文的关键,在于复现作者的算法(吴恩达老师说的)。
最后,多和人交流,我感觉水平提升最快的时候,是跟大神交流,跟优秀的人在一起,前面有人拉你,后面有人推你,你就能前进。
微信群交流其实也不错,不过只有200人能扫码进群,需要用文末的摆渡方式进群了。
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):