
10张思维导图,全面讲解 Pandas
哈喽,大家好。今天 Python 中非常重要的一个库——Pandas。
Pandas 是一个基于 Numpy 的强大工具集,用于数据处理、分析、挖掘和可视化。
我整理一张 Pandas 知识结构的思维导图,本文完整代码可以关注我的另一个公众号【简说编程】,回复:代码 获取。(注意⚠️,看清获取方式哈)。
下面我们用 10 个小节来学习 Pandas,过程简洁,思路清楚。
1. 数据结构
Pandas中有两种数据结构Series和DataFrame。
Series用一维数组,可以存储不同类型的数据。
>>> import pandas as pd
>>> import numpy as np
>>> pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
a 0.881931
b -0.112222
c 0.470156
d 0.394478
e 0.704801
dtype: float64
pd.Series()函数用来创建Series对象。
第一个参数是存储的数据,这里是 Numpy 随机生成的一维数组。
第二个参数index是数据对应的索引。在 Python list或 Numpy 中数组的索引都是数字,也称为下标,但在 Pandas 中索引可以是任意类型。
DataFrame是二维结构,类似 Excel 或数据库中的表。
>>> d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
>>> df = pd.DataFrame(d)
>>> df
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
pd.DataFrame()函数用来创建DataFrame对象。
这里用字典d创建DataFrame对象,d中的两个键值对作为DataFrame两列。键作为列名,值是Series对象作为列值。
创建Series和DataFrame对象的方式还有很多

在 Pandas 中用DataFrame的频率更高,下面的介绍以DataFrame为主。
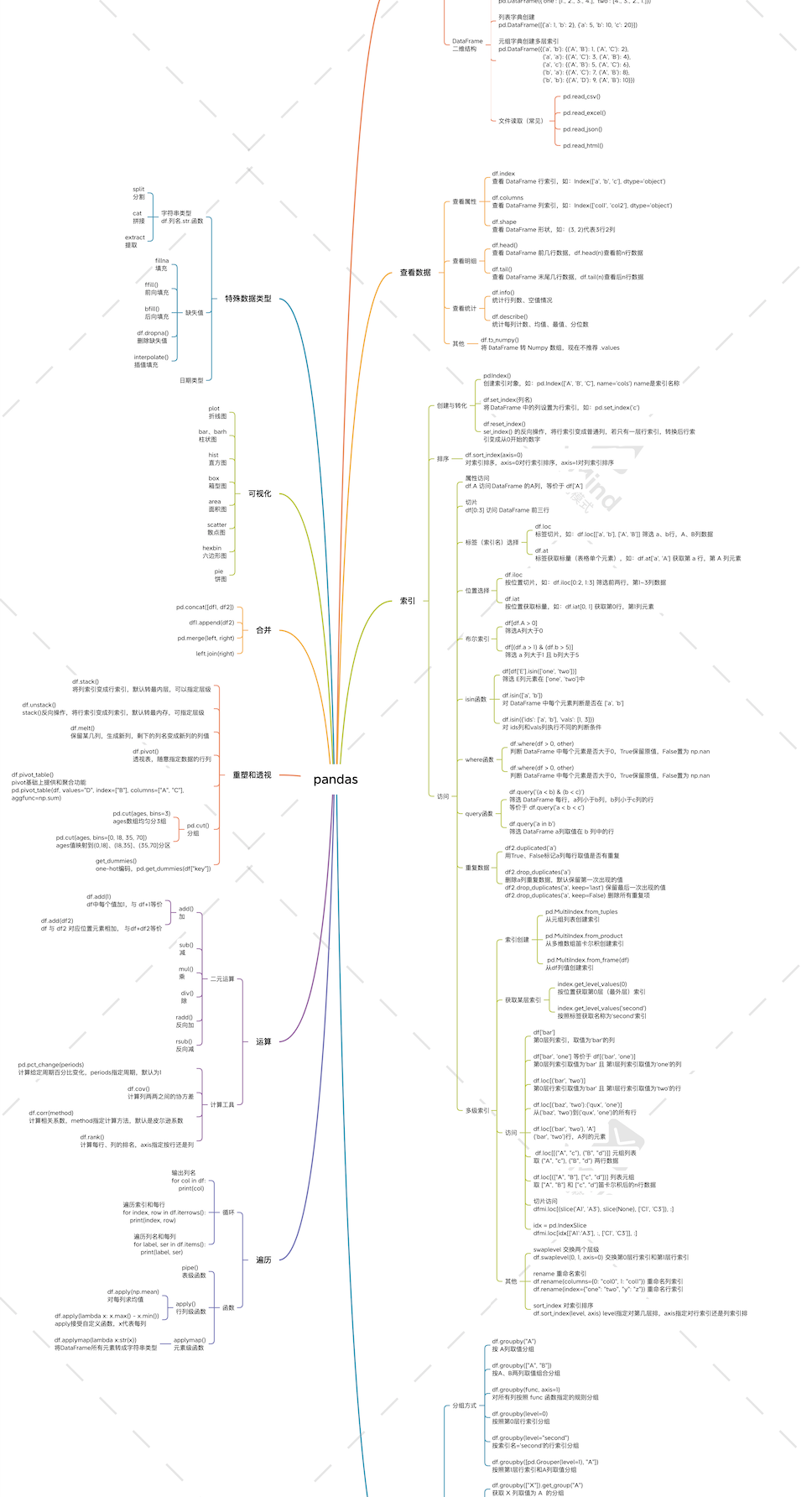
2. 查看数据
上面创建的DataFrame只有几条数据,一眼就看完了。如果数据量比较大,就需要借助一些函数来查看。
通过属性查看DataFrame基本情况,如:index、columns和shape
>>> df.index
Index(['a', 'b', 'c', 'd'], dtype='object')
通过head()和tail()函数查看DataFrame明细数据
>>> df.head(2)
one two
a 1.0 1.0
b 2.0 2.0
通过describe()查看DataFrame每列统计摘要
>>> df.describe()
one two
count 3.0 4.000000
mean 2.0 2.500000
std 1.0 1.290994
min 1.0 1.000000
25% 1.5 1.750000
50% 2.0 2.500000
75% 2.5 3.250000
max 3.0 4.000000
3. 索引
索引在 Pandas 中非常重要,通过索引我们可以获取 Series 或 DataFrame中的任意数据。
Pandas的既有行索引,也有列索引。
3.1 索引的创建与转化
索引除了创建Series 或 DataFrame时指定,也可以单独创建。
>>> index = pd.Index(['e', 'd', 'a', 'b'])
>>> columns = pd.Index(['A', 'B', 'C'], name='cols')
>>> df = pd.DataFrame(np.random.randn(4, 3), index=index, columns=columns)
>>> df
cols A B C
e -0.037910 -1.032842 -1.658740
d -0.784543 0.649506 0.928499
a 0.901721 0.022041 -0.515617
b -0.443420 -0.246031 -0.803685
通过pd.Index分别创建行列索引index和columns,并用于创建 DateFrame。

3.2 索引排序
用sort_index函数对上面的df行索引排序
>>> df.sort_index(axis=0)
cols A B C
a 2.180095 -1.820624 0.046273
b -0.607010 -0.123721 1.375773
d -0.057358 -1.403620 0.462811
e -1.672218 1.299837 0.055571
Pandas 函数里经常会见到 axis 参数,用来指定行索引或列索引
axis=0 等价于 axis='index' axis=1 等价于 axis='columns'
axis=0 表示行索引或者行索引对应的列值,因此,axis=0表示处理每列数据。同样地,axis=1表示处理每行数据。
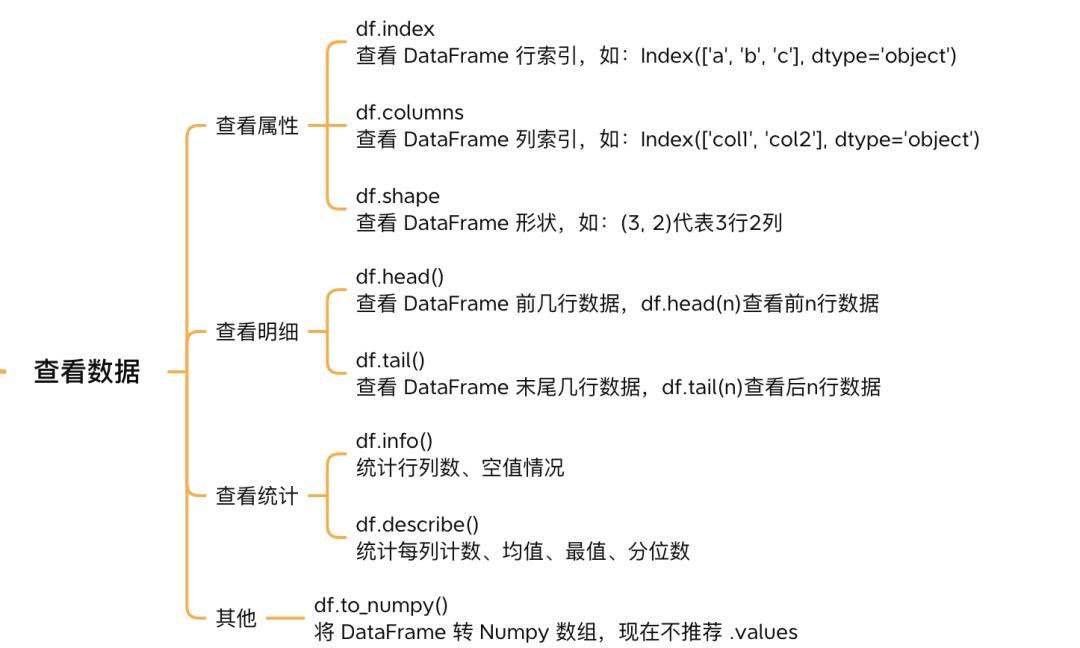
3.3 用索引访问数据
通过[]形式直接获取某列或某行
>>> # 访问A列,等价于 df.A
>>> df['A']
e -1.672218
d -0.057358
a 2.180095
b -0.607010
>>> df[:1] # 切片访问第一行
cols A B C
e -1.672218 1.299837 0.055571
通过标签选择器.loc和.at,可按照索引名访问数据。iloc获取切片,.at获取标量。
>>> df
cols A B C
e -1.672218 1.299837 0.055571
d -0.057358 -1.403620 0.462811
a 2.180095 -1.820624 0.046273
b -0.607010 -0.123721 1.375773
>>> #获取a b两行, A B两列数据
>>> df.loc[['a', 'b'], ['A', 'B']]
cols A B
a 2.180095 -1.820624
b -0.607010 -0.123721
>>> #获取a行, A列元素
>>> df.at['a', 'A']
2.180094959110999
通过位置选择器.iloc和.iat,可按照索引位置访问数据。
之前 Pandas 还可以通过ix和reindex函数访问数据,现在都不推荐使用了。
还可以通过布尔索引筛选满足条件的数据
>>> #获取A列大于0的行
>>> df[df.A > 0]
cols A B C
a 2.180095 -1.820624 0.046273
初次学习布尔索引可能会觉得难以理解,这里来拆解一下,帮助大家理解。
第一步,看df.A > 0的返回值
mask = df.A > 0
mask
>>> mask
e False
d False
a True
b False
Name: A, dtype: bool
df.A > 0返回的是Series一维数组,索引跟df一样,取值bool类型。
第二步,将mask应用在df上
>>> df[mask]
cols A B C
a 2.180095 -1.820624 0.046273
因为mask是bool类型,True表示保留该行索引,False表示丢弃该行索引。这里只有索引e取值为True,所以只保留e行。
布尔索引中通过|、&、~连接不同的判断条件,分别代表与、或、非。
3.4 其他函数
Pandas 中还定义了很多有用的函数,可以灵活地访问、获取数据。如:isin()、where()、query()。

3.5 多级索引
之前我们接触的DataFrame行列索引只有一层,Pandas 还支持多级(多层)索引。
多层索引并不难理解,将单层索引的某个值替换成元组,就是多层索引,用法上二者有相似之处。
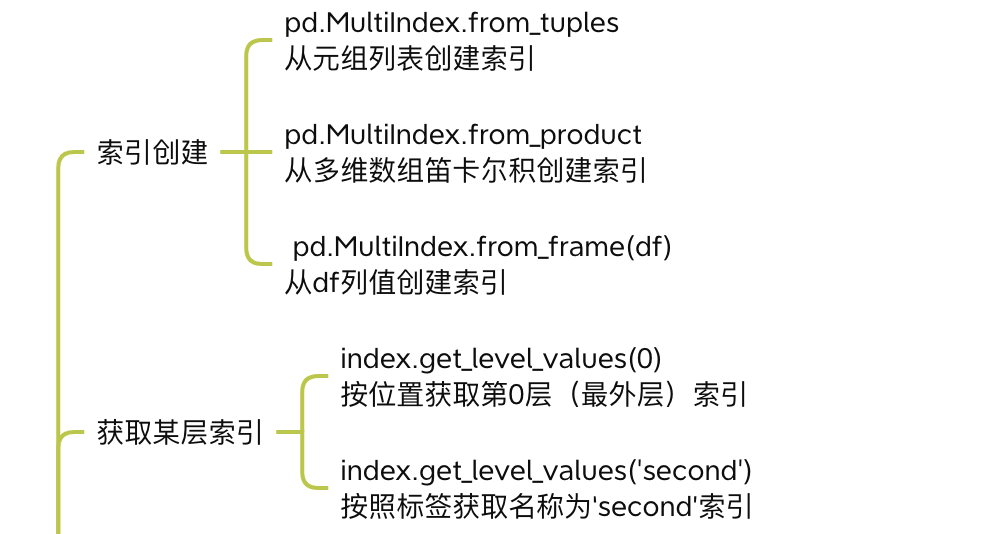
3.5.1 索引创建与获取
一般我们可以通过pd.MultiIndex创建多级索引
>>> # 通过元组列表创建2级行索引
>>> index = pd.MultiIndex.from_tuples([('bar', 'one'),('bar', 'two'),('baz', 'one'),('baz', 'two')], names=['first', 'second'])
>>> df = pd.DataFrame(np.random.randn(4, 2), index=index)
>>> df
0 1
first second
bar one 0.813204 0.817983
two -0.304902 0.396040
baz one -0.634707 0.665182
two 0.246232 -0.609914
3.5.2 多级索引访问
同样可以通过[]、.loc等方式访问多级索引。
>>> df
0 1
first second
bar one 0.813204 0.817983
two -0.304902 0.396040
baz one -0.634707 0.665182
two 0.246232 -0.609914
>>> # 获取从('bar', 'one')到('bar', 'two')的行,0列
>>> df.loc[('bar','one'):('bar', 'two'), 0]
first second
bar one 0.813204
two -0.304902
Name: 0, dtype: float64
>>> # 获取第0层行索引,bar到baz之间所有行
>>> df.loc[(slice('bar', 'baz'), slice(None)), :]
0 1
first second
bar one 0.813204 0.817983
two -0.304902 0.396040
baz one -0.634707 0.665182
two 0.246232 -0.609914
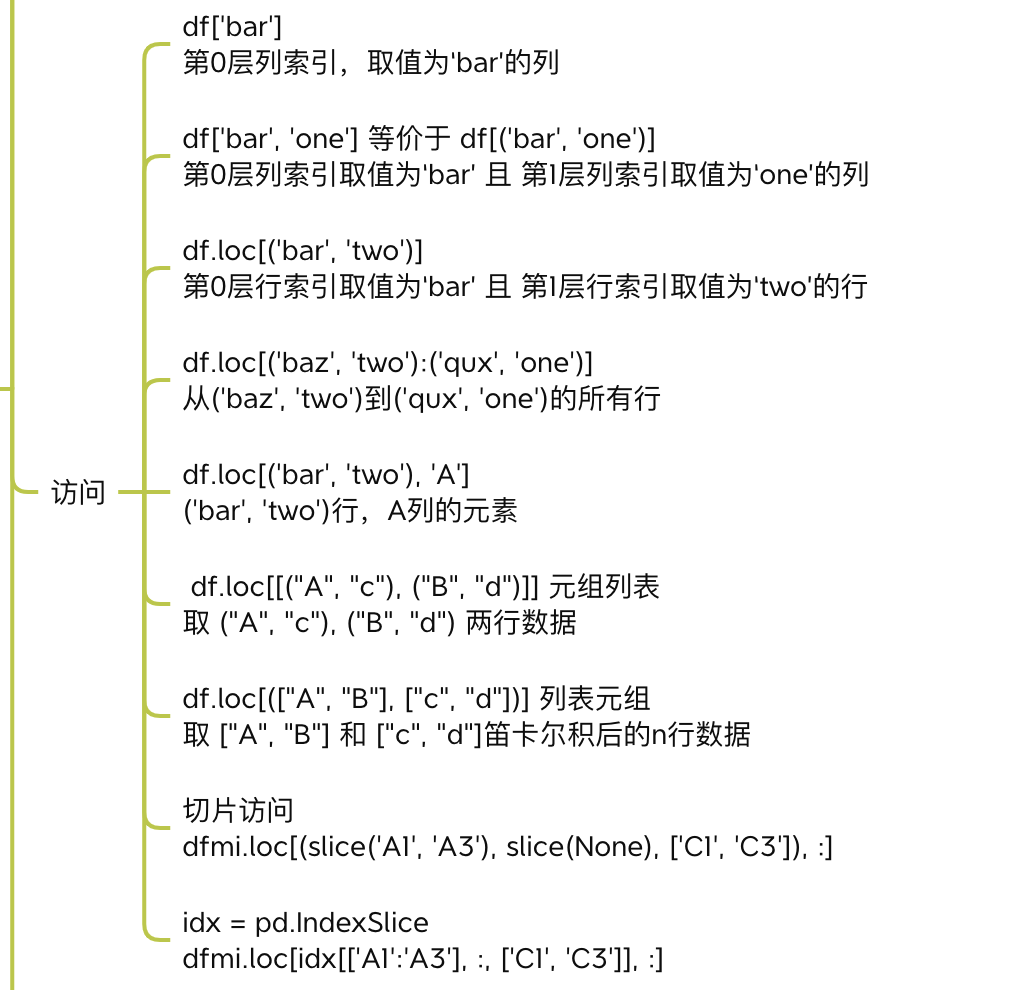
3.5.3 其他函数

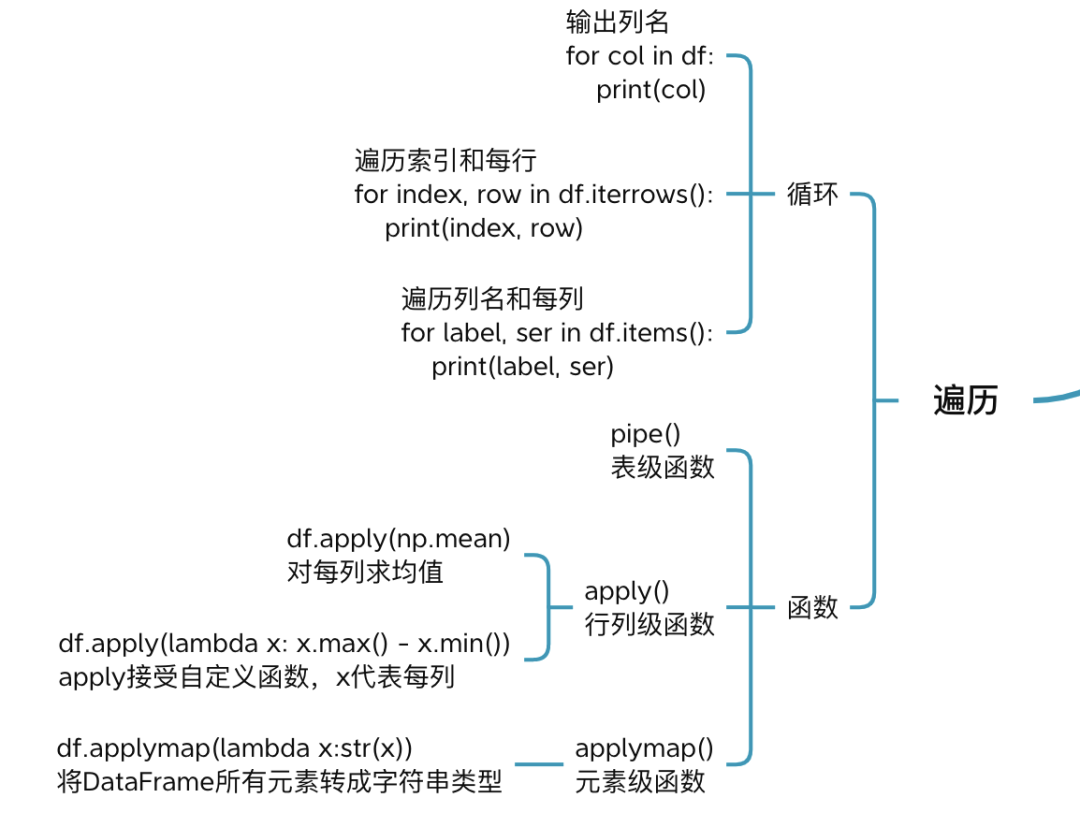
4 遍历
除了上面的访问方式,Pandas 还支持遍历的方式访问 Series 或 DataFrame中的数据。
4.1 循环方式
可以使用for循环遍历DataFrame每行、每列。
df.iterrows()函数可遍历行,df.items()函数可遍历列
>>> df[:2]
0 1
first second
bar one 0.813204 0.817983
two -0.304902 0.396040
>>> for index, row in df[:2].iterrows():
... print(index)
... print(row)
...
('bar', 'one')
0 0.813204
1 0.817983
Name: (bar, one), dtype: float64
('bar', 'two')
0 -0.304902
1 0.396040
Name: (bar, two), dtype: float64
4.2 函数方式
df.apply()函数遍历行或列,并接收函数作为参数,用来对行、列处理。
df.applymap() 函数遍历所有元素,接收函数作为参数,用来处理处理。
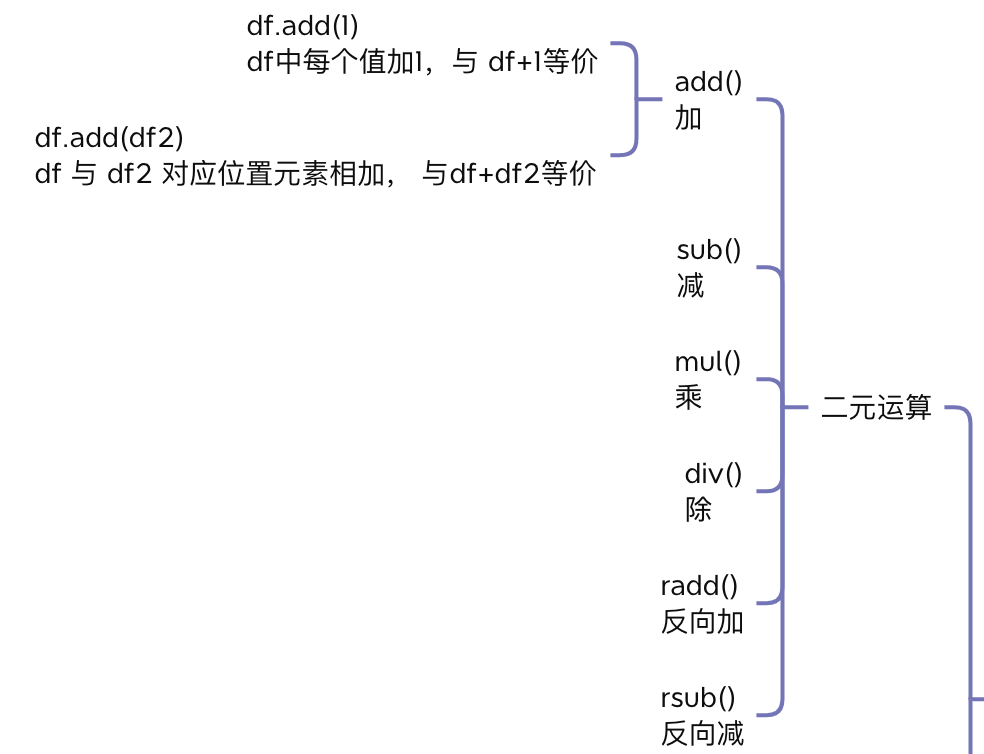
5 运算
只能获取数据还不够,我们还需能对数据做计算。
5.1 二元运算
可以用运算法,也可以用函数对DataFrame做四则运算。
以加法为例
>>> df
a b
0 1 3
1 2 4
>>> df2
a b
0 5 7
1 6 8
>>> # df + 1,等价于 df.add(1)
>>> df + 1
a b
0 2 4
1 3 5
>>> # df + df2,等价于 df.add(df2)
>>> df+df2
a b
0 6 10
1 8 12
这里的运算返回新的DataFrame,而不会改变df中的值。
另外,Pandas 还支持反向运算法。如:df.rdiv(df2) 等价于 df2 / df。
5.2 计算工具
Pandas 还提供了很多好用的计算工具,帮助我们快速完成计算。
以df.cov()函数为例,调用该函数,可以返回列与列之间的协方差。
>>> df.cov()
a b
a 0.5 0.5
b 0.5 0.5

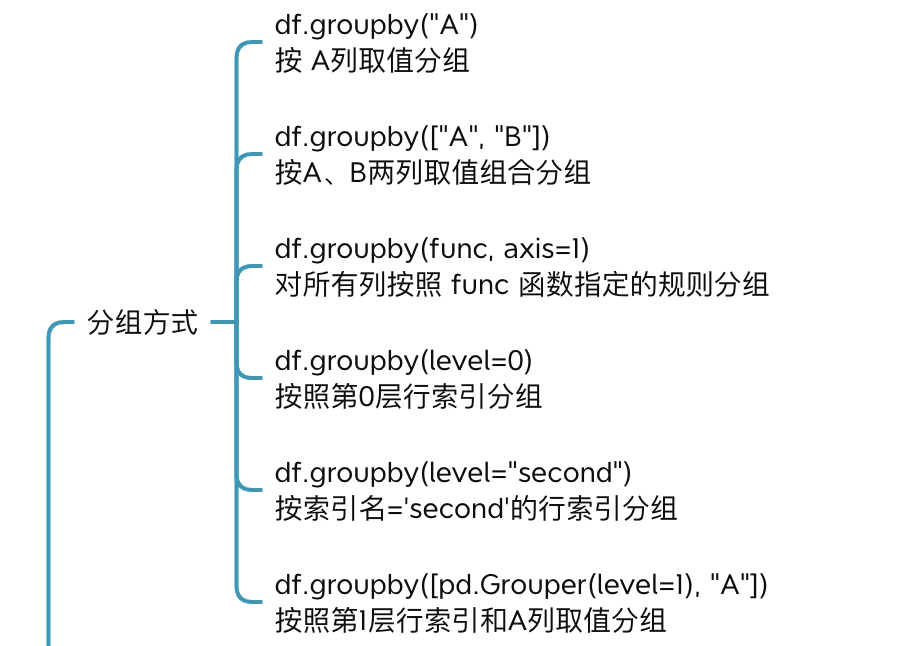
6 分组统计
分组统计是 Pandas 数据分析最常用的功能。
6.1 分组统计
Pandas 可以对 DataFrame按照行、按列、行+列的方式分组。
>>> df
a b
0 a1 1
1 a2 2
2 a1 3
>>> # 按a列分组
>>> df.groupby('a')
0x7fafbe6f4a30>
>>> # 按第0层行索引分组
>>> df.groupby(level=0)
0x7fafbe6f49a0>
>>> # 按第0层行索引和a列,分组计数
0x7fafbe70bac0>
6.2 分组遍历
分完组后,我们可以获取单个分组结果,或者遍历所有分组。
>>> for name, group in df.groupby('a'):
... print(group)
... print(name)
...
a b
0 a1 1
2 a1 3
a1
a b
1 a2 2
a2
name是a列取值,group是每个分组DataFrame。

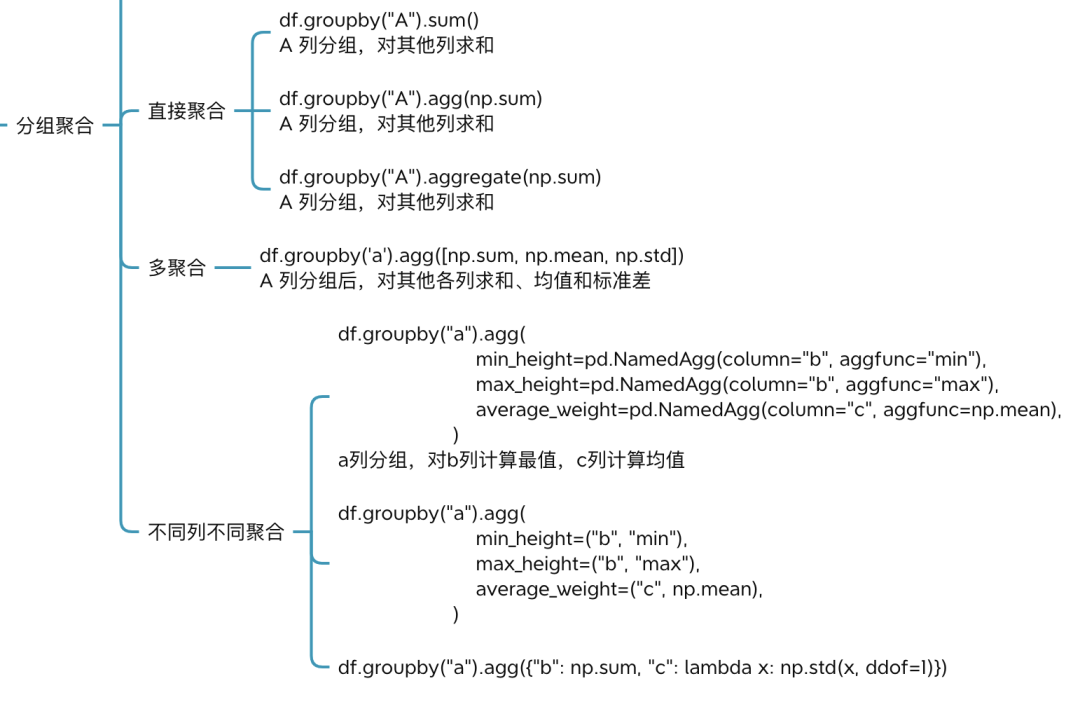
6.3 分组聚合
分组的最终目的就是为了对每个分组的数据做聚合统计。
Pandas 提供了一些内置的聚合函数,下面列举一些常见的
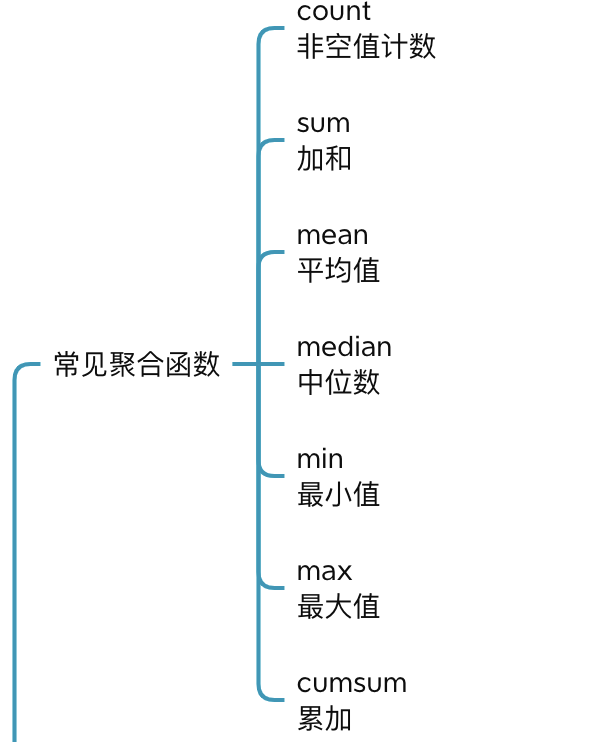
同时,也支持 Numpy 的聚合函数和自定义聚合函数。
可以指定1个聚合函数,也可以指定多个聚合函数,甚至还可以对不同列指定不同的聚合函数。
>>> df
a b c
0 a1 1 4
1 a2 2 5
2 a1 3 6
>>> # 对a列分组求和
>>> df.groupby("a").sum()
b c
a
a1 4 10
a2 2 5
>>> # 对a列分组,对b c列求和、求均值
>>> df.groupby("a").agg([np.sum, np.mean])
b c
sum mean sum mean
a
a1 4 2.0 10 5.0
a2 2 2.0 5 5.0
>>> # 对a列分组,b列求和,c列用自定函数求方差
>>> df.groupby("a").agg({"b": np.sum, "c": lambda x: np.std(x, ddof=1)})
b c
a
a1 4 1.414214
a2 2 NaN
7. 重塑和透视
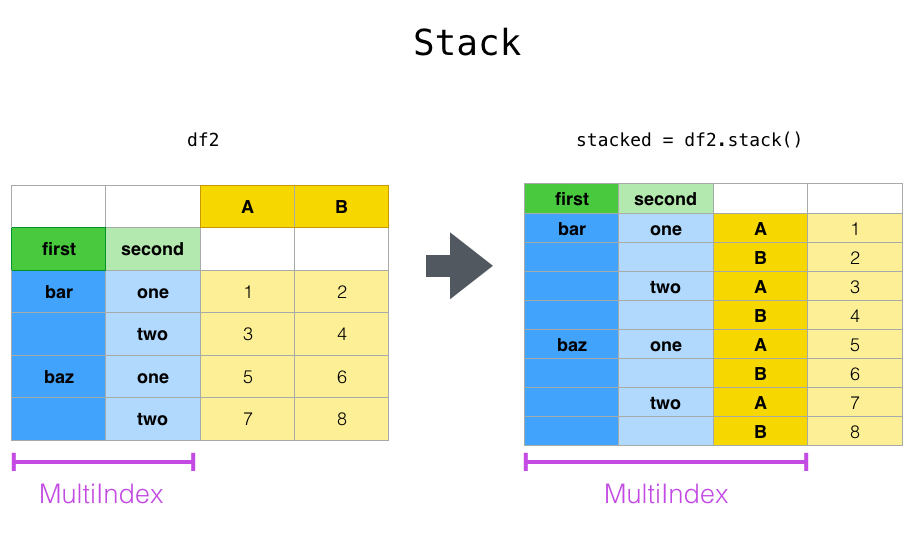
之前无论对DataFrame做什么操作,都不会改变它的结构。这部分我们会改变DataFrame的形状,即:改变现有的行列结构。
pd.stack()将列索引变成行索引。
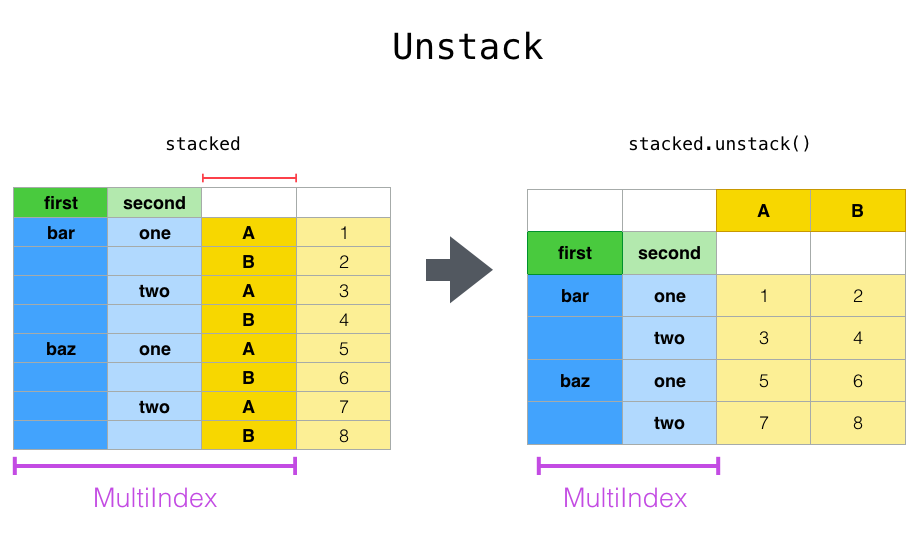
pd.unstack()是pd.stack()的反向操作
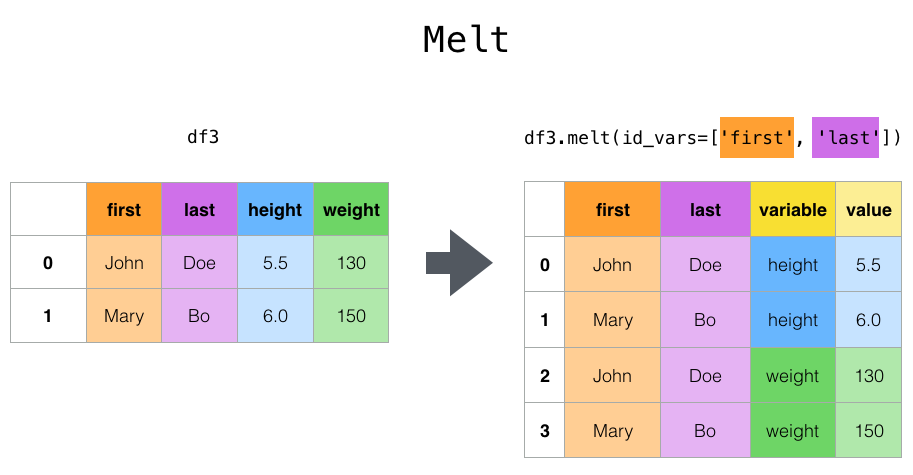
pd.melt(),保留某几列,将剩下的列“融化”掉,生成两个新列,一个存放被“融化”的列名,另一个存放被“融化”的列值。
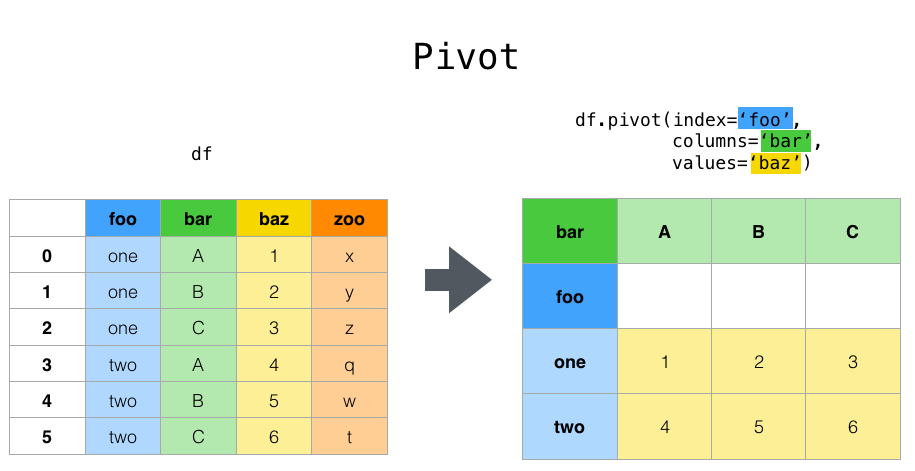
pd.pivot()类似 Excel 中的透视表,任意指定新的行列值。
pd.pivot_table()提供了透视表的聚合功能。

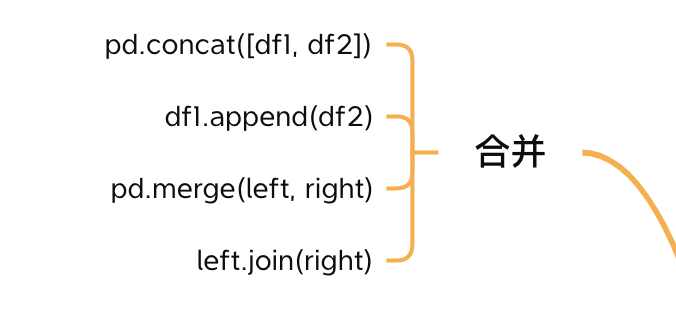
8. 合并
Pandas 提供了一些函数,可以将多个DataFrame合并,既可以按行和并也可以按列合并。
这些函数的功能类似 SQL 中的union和join。
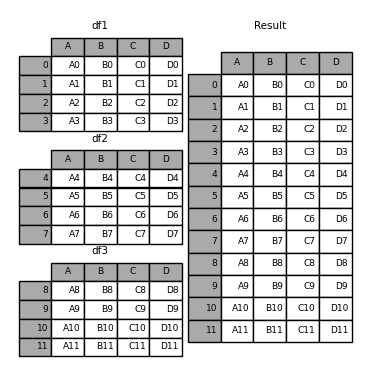
以pd.concat()为例,按列合并
pd.concat([df1, df2, df3])
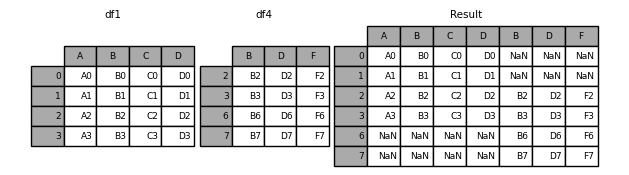
按行和并
pd.concat([df1, df4], axis=1)
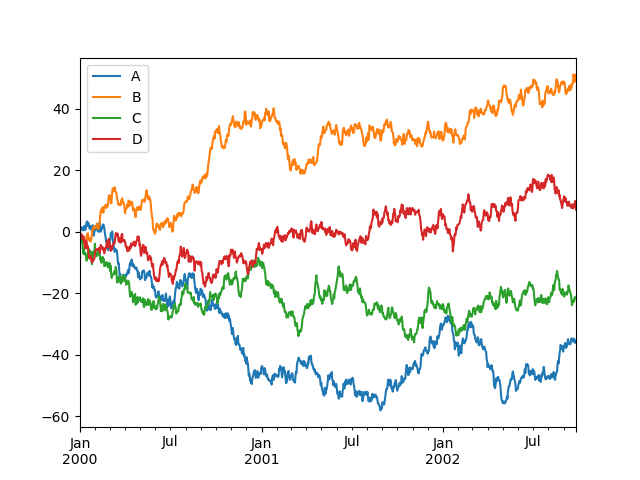
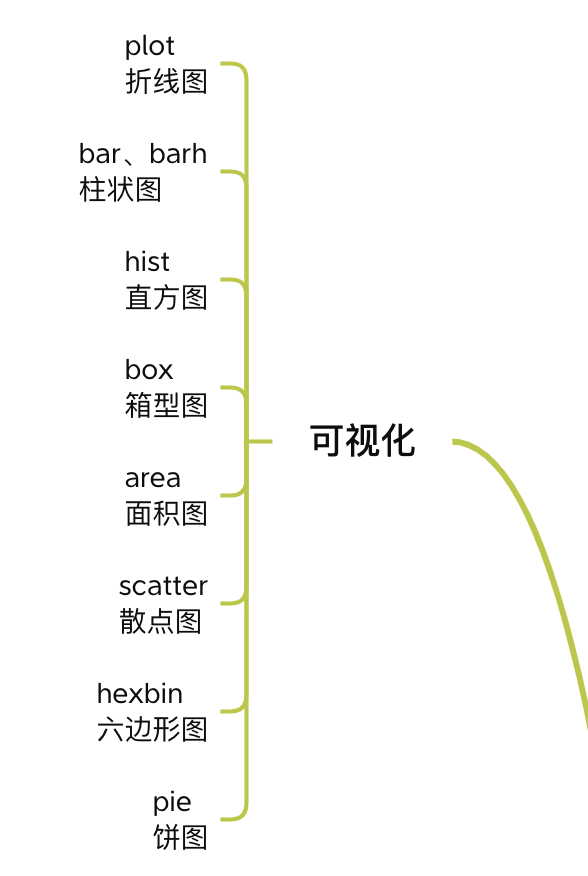
9. 可视化
Pandas 集成了 Matplotlib ,可以帮助我们快速作图。
ts = pd.Series(np.random.randn(1000), index=pd.date_range("1/1/2000", periods=1000))
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list("ABCD"))
df = df.cumsum()
plt.figure()
df.plot()
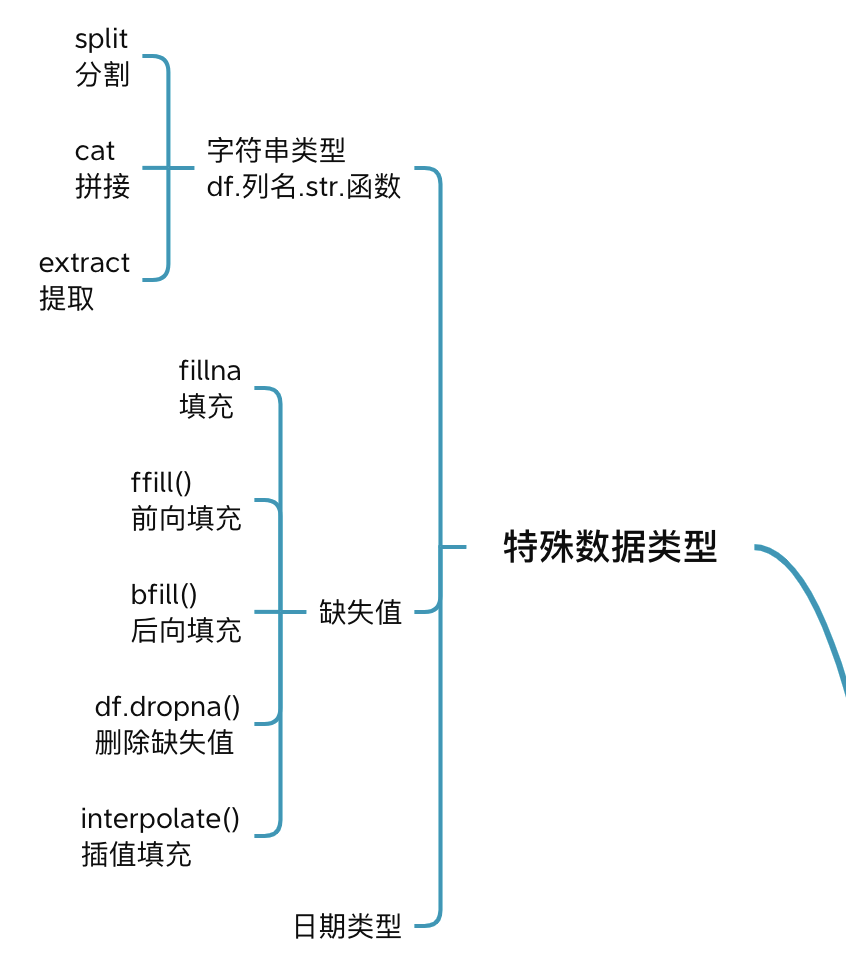
10. 特殊数据类型
Padans 对某些特殊数据类型提供一些函数,方便数据处理。
对字符串类型的数据,提供字符串分割、拼接、提取等函数。
对缺失值,提供填充、插值和删除等函数
对日期类型,提供日期加减、日期间隔等函数。
至此,我们通过 10 个小节把 Pandas 常用的功能讲完了。
本文完整代码可以关注我的另一个公众号【简说编程】,回复:代码 获取。(注意⚠️,看清获取方式哈)。
点赞、在看、转发,感谢支持,我们下期见~
近期文章:
【干货+赠书】手写一个 Python "病毒"
如何找到我: