
Zookeeper 思维导图
常见相关问题
ZooKeeper 是什么?
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是Google 的 Chubby 一个开源的实现,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户。客户端的读请求可以被集群中的任意一台机器处理,如果读请求在节点上注册了监听器,这个监听器也是由所连接的zookeeper机器来处理。对于写请求,这些请求会同时发给其他zookeeper机器并且达成一致后,请求才会返回成功。因此,随着zookeeper的集群机器增多,读请求的吞吐会提高但是写请求的吞吐会下降。有序性是zookeeper中非常重要的一个特性,所有的更新都是全局有序的,每个更新都有一个唯一的时间戳,这个时间戳称为zxid(Zookeeper Transaction Id)。而读请求只会相对于更新有序,也就是读请求的返回结果中会带有这个zookeeper最新的zxid。
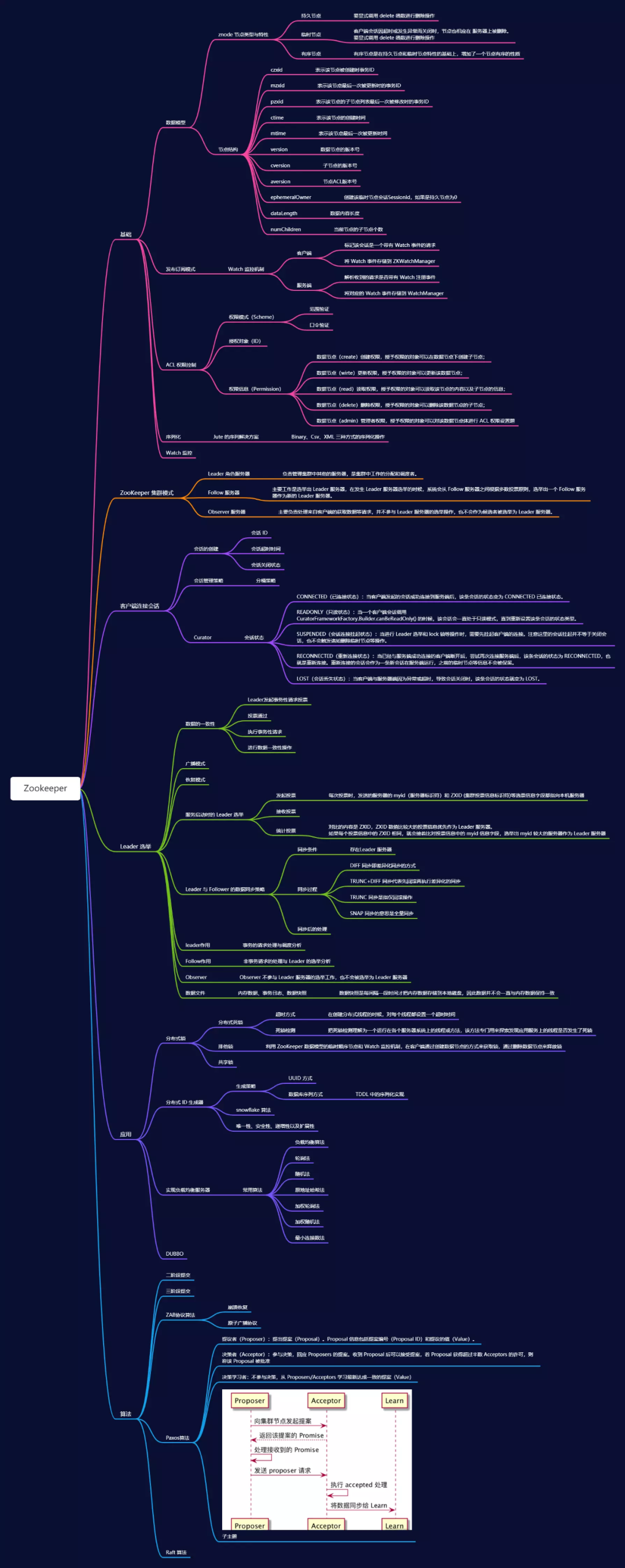
节点类型
PERSISTENT-持久化目录节点 客户端与zookeeper断开连接后,该节点依旧存在 PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点 客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号 EPHEMERAL-临时目录节点 客户端与zookeeper断开连接后,该节点被删除 EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点。客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
集群模式
Leader 角色服务器负责管理集群中其他的服务器,是集群中工作的分配和调度者。 Follow 服务器的主要工作是选举出 Leader 服务器,在发生 Leader 服务器选举的时候,系统会从 Follow 服务器之间根据多数投票原则,选举出一个 Follow 服务器作为新的 Leader 服务器。 Observer 服务器则主要负责处理来自客户端的获取数据等请求,并不参与 Leader 服务器的选举操作,也不会作为候选者被选举为 Leader 服务器。
Zookeeper工作原理
Zookeeper 下 Server工作状态
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步
Zookeeper分布式锁(文件系统、通知机制)
zookeeper是如何选取主leader的?
Zookeeper同步流程

评论