
从零开始写一个推荐系统---推荐电影
上一篇文章讲解了两种计算相似度的方法,理论部分就已经准备完毕了。实践部分,考验的是你的工程能力。首先,我们需要准备一份数据,这份数据我们没办法自己去造,自己造的数据不真实,没有实践的意义。可供与实战的数据有很多,很多研究机构和大学都会公开实验的数据,本文选择使用ml-100k数据集,它是一份电影评分的数据集,我这里提供一份百度网盘的下载地址: https://pan.baidu.com/s/1KWe7gmsFoEHvDd0W762fcA 提取码:6skh
下载后解压,找到u.data文件,这个文件里的数据有四列
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
依次是用户id,电影id,评分,时间,我们只用前3列数据。
需要编写一个函数打开u.data文件读取里面的数据,数据保存为字典,格式如下所示
{
'196': {
'242': 3,
'323': 4
},
'166': {
'242': 4,
'213': 5
}
}
首先用user_id做key,value为这个用户对电影的评分信息,value中以moive_id做key,评分做score, 这样存储,是为了后续计算的方便,函数实现如下
def get_user_score_info():
"""
读取u.data 文件,获得用户对电影的打分信息,文件里有4列,我们只要前3列
用户id 电影id 评分
:return:
"""
user_score_info = {}
with open('./u.data', 'r')as f:
for line in f:
array = line.split()
user_id = array[0]
movie_id = array[1]
score = int(array[2])
user_score_info.setdefault(user_id, {})
user_score_info[user_id][movie_id] = score
return user_score_info
选定一个人,作为base,计算他与其他人的相似度,如果俩俩之间计算相似度,计算量太大了,我最终想要完成的函数,一次只为一个人推荐电影。
在根据电影评分计算两个人的相似度时,我设置了一个前提条件,这两个人打过分的电影,至少有5个相同的电影,不然可能会出现这样的情形,两个人打分电影里只有一个是相同的,而且分数一致,不论采用哪种算法,他们的相似度都很高,可这样的相似度不具备参考价值。
实现函数can_calc_similarity, 计算两个人的评分数据是否可以计算相似度。
def get_same_movie(score_dict_1, score_dict_2):
"""
获取两人看过的相同的电影id
:param score_dict_1:
:param score_dict_2:
:return:
"""
set_1 = set([movie for movie in score_dict_1])
set_2 = set([movie for movie in score_dict_2])
intersection_set = set_1.intersection(set_2)
return intersection_set
def can_calc_similarity(score_dict_1, score_dict_2, same_movie_count=5):
"""
判断两个人是否有必要计算相似度,如果两人评价的电影里,相同的电影数量超过same_movie_count 才进行计算
:param score_dict_1:
:param score_dict_2:
:param same_movie_count:
:return:
"""
intersection_set = get_same_movie(score_dict_1, score_dict_2)
return len(intersection_set) >= same_movie_count
接下来实现函数calc_similarity,它接收一个user_id参数,计算这个用户与其他用户的相似度
import math
import copy
import numpy as np
from rich.console import Console
from rich.table import Table
def calc_person_distance(score_dict_1, score_dict_2):
"""
计算两人对电影评价的相似度
:param score_dict_1:
:param score_dict_2:
:return:
"""
intersection_set = get_same_movie(score_dict_1, score_dict_2)
score_lst_1 = [score_dict_1[movie_id] for movie_id in intersection_set]
score_lst_2 = [score_dict_2[movie_id] for movie_id in intersection_set]
return sim_distance(score_lst_1, score_lst_2)
def calc_similarity(base_user_id):
user_score_info = get_user_score_info()
base_score_dict = user_score_info[base_user_id]
similarity_lst = []
for user_id, score_dict in user_score_info.items():
if user_id == base_user_id:
continue
if not can_calc_similarity(base_score_dict, score_dict):
continue
similarity = calc_person_distance(base_score_dict, score_dict)
similarity_lst.append((user_id, similarity))
similarity_lst.sort(key=lambda x: x[1], reverse=True)
head_5 = similarity_lst[:5]
show_detail(base_user_id, user_score_info, head_5)
def sim_distance(lst1, lst2):
"""
计算欧几里得距离
:param lst1:
:param lst2:
:return:
"""
sum_value = 0
for x1, x2 in zip(lst1, lst2):
sum_value += pow(x1 - x2, 2)
return 1/(1+math.sqrt(sum_value))
if __name__ == '__main__':
calc_similarity('196')
计算好相似度后,按照从大到小进行排序,取出相似度最高的前5名用户,作为电影推荐的参考用户,这一步,我为了查看具体信息,编写了函数show_detail,展示这5个用户与base用户对电影的评价情况,测试时,选择用户196, 实验效果如图
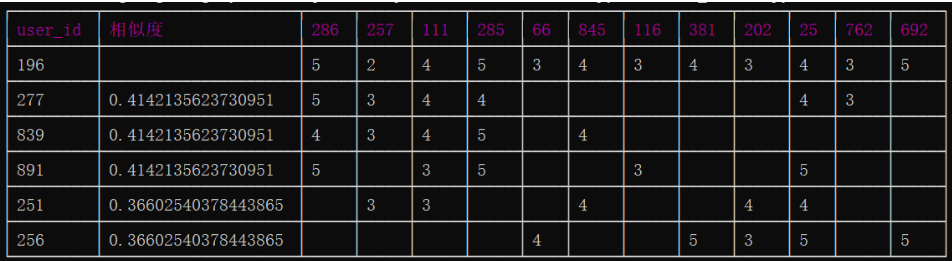
def show_detail(user_id, user_score_info, similarity_lst):
base_score_dict = user_score_info[user_id]
all_moive_set = set()
for item in similarity_lst:
intersection_set = get_same_movie(base_score_dict, user_score_info[item[0]])
all_moive_set = all_moive_set.union(intersection_set)
console = Console()
table = Table(show_header=True, header_style="bold magenta", show_lines=True)
table.add_column('user_id')
table.add_column('相似度')
for moive_id in all_moive_set:
table.add_column(moive_id)
similarity_lst_coyp = copy.deepcopy(similarity_lst)
similarity_lst_coyp.insert(0, (user_id, ''))
for id, similarity in similarity_lst_coyp:
value_lst = [id, str(similarity)]
for moive_id in all_moive_set:
value_lst.append(str(user_score_info[id].get(moive_id, '')))
table.add_row(*value_lst)
console.print(table)
已经从成千上万的用户中找到了电影品味和id为196的用户十分接近的5个用户,接下来,要根据这5位用户对电影的评分来为196推荐电影。直接从这5个用户中选择一个为196做推荐是不可行的,我们需要综合这5个人的评分情况来做推荐,具体算法如下。
对于一部电影,用相似度乘评分,得到的是一个加权的评分,这个评分更能反映出这个评论者对电影的评价推196的影响。
将这5个人对于一部电影加权后的评分累加在一起,得到的结果为socre_sum
计算这5个人与196的相似度之和,得到的结果为similarity_sum
计算socre_sum/similarity_sum , 这个结果作为这这一部影的推荐值,它考虑到了每一个人对电影的评分,也考虑到了每一个人和196的品味相似程度,更加客观,如果一部电影只有4个人评价,计算方法不变,缺失的评分视为0
算法实现如下
def calc_similarity(base_user_id):
user_score_info = get_user_score_info()
base_score_dict = user_score_info[base_user_id]
similarity_lst = []
for user_id, score_dict in user_score_info.items():
if user_id == base_user_id:
continue
if not can_calc_similarity(base_score_dict, score_dict):
continue
similarity = calc_person_distance(base_score_dict, score_dict)
similarity_lst.append((user_id, similarity))
similarity_lst.sort(key=lambda x: x[1], reverse=True)
head_5 = similarity_lst[:5]
show_detail(base_user_id, user_score_info, head_5)
recommend(base_user_id, user_score_info, head_5)
def recommend(base_user_id, user_score_info, head_5):
diff_moive_set = set() # 所有base_user_id 没看过的电影
for user_id, similarity in head_5:
diff_moive = get_diff_moive(user_score_info[base_user_id], user_score_info[user_id])
diff_moive_set = diff_moive_set.union(diff_moive)
recommend_lst = []
for moive_id in diff_moive_set:
moive_socre_sum = 0
similarity_sum = 0
user_score_count = 0
for user_id, similarity in head_5:
if moive_id in user_score_info[user_id]:
user_score_count += 1
moive_socre_sum += user_score_info[user_id][moive_id]*similarity
similarity_sum += similarity
if user_score_count < 3:
continue
recommend_lst.append((moive_id, moive_socre_sum/similarity_sum))
recommend_lst.sort(key=lambda x: x[1], reverse=True)
recommend_lst = recommend_lst[:5]
print(recommend_lst)
show_recommend_detail(user_score_info, recommend_lst, head_5)
def show_recommend_detail(user_score_info, recommend_lst, similarity_lst):
console = Console()
table = Table(show_header=True, header_style="bold magenta", show_lines=True)
table.add_column('user_id')
table.add_column('相似度')
for moive_id, _ in recommend_lst:
table.add_column(moive_id)
for user_id, similarity in similarity_lst:
value_lst = [user_id, str(similarity)]
for moive_id, _ in recommend_lst:
value_lst.append(str(user_score_info[user_id].get(moive_id, '')))
table.add_row(*value_lst)
console.print(table)
def get_diff_moive(base_score, score_dict_2):
set_1 = set([movie for movie in base_score])
set_2 = set([movie for movie in score_dict_2])
return set_2.difference(set_1)
这部分代码并不复杂,get_diff_moive函数返回两个人点评分的差异化部分,我们需要找到196用户没有评价过的电影,然后计算这些电影的推荐分数,在计算电影推荐分数时,只计算那些至少有3个人评价过的电影,这3个人已经是品味和196很相似了,他们又都看过这部电影,才有推荐价值。如果一部电影只有5个人中的一个人看过,说明这部电影不是很受这5个人喜欢,5个人超过半数的人都喜欢的电影才有推荐意义。
程序最终的输出如下图
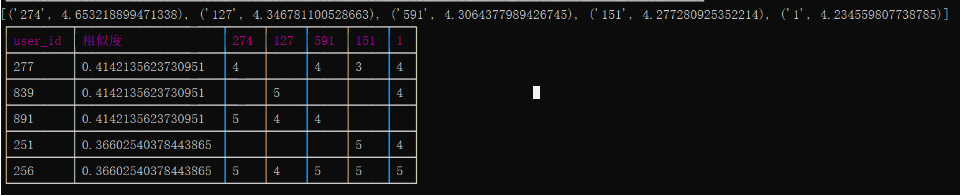
最终,本系统为196用户推荐了5部电影。这是一个非常简单的推荐系统,它的算法核心是基于用户的,是基于用户的协同过滤推荐,当用户数量并不大时,它可以胜任推荐任务,但当用户数量非常大时,就会遇到性能问题。当你想为196推荐电影时,你不得不计算他和所有用户的相似度,如果所有用户的总量为一千万,其计算量会非常的大。
想要解决海量用户下的推荐,可以使用基于物品的协同过滤算法,关于这个算法,我将在下一篇文章继续和大家分享。