
一文澄清网上对 ConcurrentHashMap 的一个流传甚广的误解!
Hollis的新书限时折扣中,一本深入讲解Java基础的干货笔记!
上周我在极客时间某个课程看到某个讲师在讨论 ConcurrentHashMap(以下简称 CHM)是强一致性还是弱一致性时,提到这么一段话
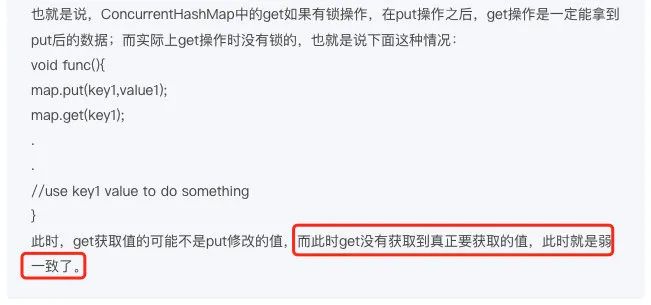
这个解释网上也是流传甚广,那么到底对不对呢,在回答这个问题之前,我们得想清楚两个问题
什么是强一致性,什么是弱一致性
上文提到 get 没有加锁,所以没法即时获取 put 的数据,也就意味着如果加锁就可以立即获取到 put 的值了?那么除了加锁之外,还有其他办法可以立即获取到 put 的值吗
强一致性与弱一致性
强一致性
首先我们先来看第一个问题,什么是强一致性
一致性(Consistency)是指多副本(Replications)问题中的数据一致性。可以分为强一致性、弱一致性。
强一致性也被可以被称做原子一致性(Atomic Consistency)或线性一致性(Linearizable Consistency),必须符合以下两个要求
任何一次读都能立即读到某个数据的最近一次写的数据
系统中的所有进程,看到的操作顺序,都和全局时钟下的顺序一致
简单地说就是假定对同一个数据集合,分别有两个线程 A、B 进行操作,假定 A 首先进行了修改操作,那么从时序上在 A 这个操作之后发生的所有 B 的操作都应该能立即(或者说实时)看到 A 修改操作的结果。
弱一致性
与强一致性相对的就是弱一致性,即数据更新之后,如果立即访问的话可能访问不到或者只能访问部分的数据。如果 A 线程更新数据后 B 线程经过一段时间后都能访问到此数据,则称这种情况为最终一致性,最终一致性也是弱一致性,只不过是弱一致性的一种特例而已
那么在 Java 中产生弱一致性的原因有哪些呢,或者说有哪些方式可以保证强一致呢,这就得先了解两个概念,可见性和有序性
一致性的根因:可见性与有序性
可见性
首先我们需要了解一下 Java 中的内存模型

上图是 JVM 中的 Java 内存模型,可以看到,它主要由两部分组成,一部分是线程独有的程序计数器,虚拟机栈,本地方法栈,这部分的数据由于是线程独有的,所以不存在一致性问题(我们说的一致性问题往往指多线程间的数据一致性),一部分是线程共享的堆和方法区,我们重点看一下堆内存。
我们知道,线程执行是要占用 CPU 的,CPU 是从寄存器里取数据的,寄存器里没有数据的话,就要从内存中取,而众所周知这两者的速度差异极大,可谓是一个天上一个地上,所以为了缓解这种矛盾,CPU 内置了三级缓存,每次线程执行需要数据时,就会把堆内存的数据以 cacheline(一般是 64 Byte) 的形式先加载到 CPU 的三级缓存中来,这样之后取数据就可以直接从缓存中取从而极大地提升了 CPU 的执行效率(如下图示)
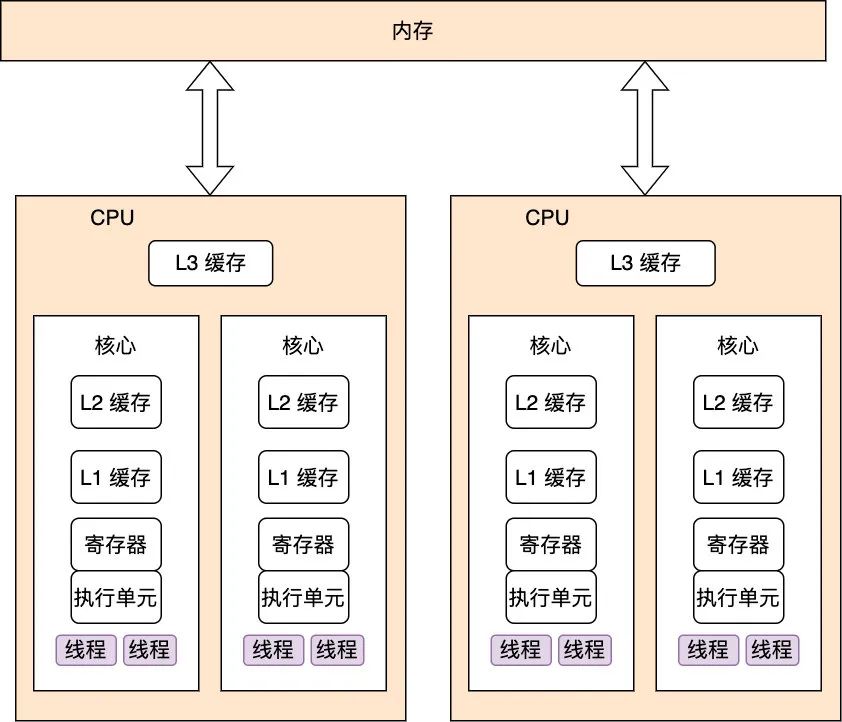
但是这样的话由于线程加载执行完数据后数据往往会缓存在 CPU 的寄存器中而不会马上刷新到内存中,从而导致其他线程执行如果需要堆内存中共享数据的话取到的就不会是最新数据了,从而导致数据的不一致
举个例子,以执行以下代码为例
//线程1执行的代码
int i = 0;
i = 10;
//线程2执行的代码
j = i;
在线程 1 执行完后 i 的值为 10,然后 2 开始执行,此时 j 的值很可能还是 0,因为线程 1 执行时,会先把 i = 0 的值从内存中加载到 CPU 缓存中,然后给 i 赋值 10,此时的 10 是更新在 CPU 缓存中的,而未刷新到内存中,当线程 2 开始执行时,首先会将 i 的值从内存中(其值为 0)加载到 CPU 中来,故其值依然为 0,而不是 10,这就是典型的由于 CPU 缓存而导致的数据不一致现象。
那么怎么解决可见性导致的数据不一致呢,其实只要让 CPU 修改共享变量时立即写回到内存中,同时通过总线协议(比如 MESI)通过其他 CPU 所读取的此数据所在 cacheline 无效以重新从内存中读取此值即可
有序性
除了可见性造成的数据不一致外,指令重排序也会造成数据不一致
int x = 1; ①
boolean flag = true; ②
int y = x + 1; ③
以上代码执行步骤可能很多人认为是按正常的 ①,②,③ 执行的,但实际上很可能编译器会将其调换一下位置,实际的执行顺序可能是 ①③②,或 ②①③,也就是说 ①③ 是紧邻的,为什么会这样呢,因为执行 1 后,CPU 会把 x = 1 从内存加载到寄存器中,如果此时直接调用 ③ 执行,那么 CPU 就可以直接读取 x 在寄存器中的值 1 进行计算,反之,如果先执行了语句 ②,那么有可能 x 在寄存器中的值被覆盖掉从而导致执行 ③ 后又要重新从内存中加载 x 的值,有人可能会说这样的指令重排序貌似也没有多大问题呀,那么考虑如下代码
public class Reordering {
private static boolean flag;
private static int num;
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
while (!flag) {
Thread.yield();
}
System.out.println(num);
}
}, "t1");
t1.start();
num = 5; ①
flag = true; ②
}
}
以上代码最终输出的值正常情况下是 5,但如果上述 ① ,② 两行指令发生重排序,那么结果是有可能为 0 的,从而导致我们观察到的数据不一致的现象发生,所以显然解决方案是避免指令重排序的发生,也就是保证指令按我们看到的代码的顺序有序执行,也就是我们常说的有序性,一般是通过在指令之间添加内存屏障来避免指令的重排序
那么如何保证可见性与有序性呢
相信大家都非常熟悉了,使用 volatile 可以保证可见性与有序性,只要在声明属性变量时添加上 volatile 就可以让此变量实现强一致性,也就是说上述的 Reordering 类的 flag 只要声明为 volatile,那么打印结果就永远是 5!
好了,现在问题来了,CHM 到底是不是强一致性呢,首先我们以 Java 8 为例来看下它的设计结构(和之前的版本相差不大,主要加上了红黑树提升了查询效率)
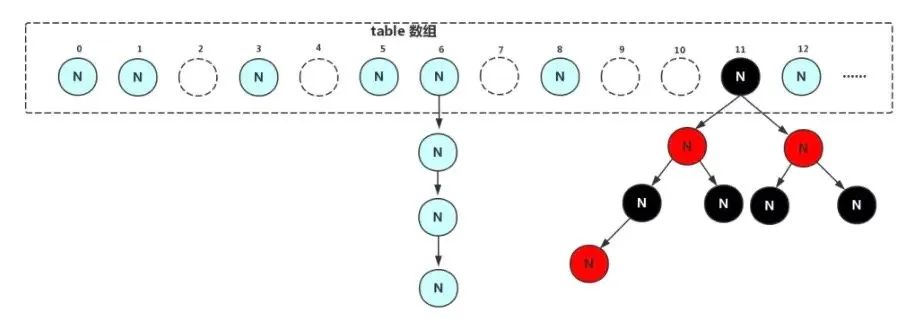
来看下这个 table 数组和节点的声明方式(以下定义 8 和 之前的版本中都是一样的):
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
transient volatile Node[] table;
...
}
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node next;
...
}
可以看到 CHM 的 table 数组,Node 中的 值 val,下一个节点 next 都声明为了 volatile,于是有学员就提出了一个疑问

讲师的回答也提到 CHM 为弱一致性的重要原因:即如果 table 中的某个槽位为空,此时某个线程执行了 key,value 的赋值操作,那么此槽位会新增一个 Node 节点,在 JDK 8 以前,CHM 是通过以下方式给槽位赋 Node 的
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
...
tab[index] = new HashEntry(...);
...
unlock();
}
然后是通过以下方式来根据 key 来读取 value 的
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
可以看到 put 时是直接给数组中的元素赋值的,而由于 get 没有加锁,所以无法保证线程 A put 的新元素对执行 get 的线程可见。
put 是有加锁的,所以其实如果 get 也加锁的话,那么毫无疑问 get 是可以立即拿到 put 的值的。为什么加锁也可以呢,其实这是 JLS(Java Language Specification Java 语言规范) 规定的几种情况,简单地说就是支持 happens before 语义的可以保证数据的强一致性,在官网(https://docs.oracle.com/javase/specs/jls/se8/html/jls-17.html)中列出了几种支持 Happens before 的情况,其中指出使用 volatile,synchronize,lock 是可以确保 happens before 语义的,也就是说使用这三者可以保证数据的强一致性,可能有人就问了,到底什么是 happens before 呢,其实本质是一种能确保线程及时刷新数据到内存,另一线程能实时从内存读取最新数据以保证数据在线程之间保持一致性的一种机制,我们以 lock 为例来简单解释下
public class LockDemo {
private int x = 0;
private void test() {
lock();
x++;
unlock();
}
}
如果线程 1 执行 test,由于拿到了锁,所以首先会把数据(此例中为 x = 0)从内存中加载到 CPU 中执行,执行 x++ 后,x 在 CPU 中的值变为 1,然后解锁,解锁时会把 x = 1 的值立即刷新到内存中,这样下一个线程再执行 test 方法时再次获取相同的锁时又从内存中获取 x 的最新值(即 1),这就是我们通常说的对一个锁的解锁, happens-before 于随后对这个锁的加锁,可以看到,通过这种方式可以保证数据的一致性
至此我们明白了:在 Java 8 以前,CHM 的 get,put 确实是弱一致性的,可能有人会问为什么不对 get 加锁呢,加上了锁不就可以确保数据的一致性了吗,可以是可以,但别忘了 CHM 是为高并发设计而生的,加了锁不就导致并发性大幅度下降了么,那 CHM 存在的意义是啥?
所以 put,get 就无法做到强一致性了吗?
我们在上文中已经知道,使用 volatile,synchronize,lock 是可以确保 happens before 语义的,同时经过分析我们知道使用 synchronize,lock 加锁的设计是不满足我们设计 CHM 的初衷的,那么只剩下 volatile 了,遗憾的是由于 Java 数组在元素层面的元数据设计上的缺失,是无法表达元素是 final、volatile 等语义的,所以 volatile 可以修饰变量,却无法修饰数组中的元素,还有其他办法吗?来看看 Java 8 是怎么处理的(这里只列出了写和读方法中的关键代码)
private static final sun.misc.Unsafe U;
// 写
final V putVal(K key, V value, boolean onlyIfAbsent) {
...
for (Node[] tab = table;;) {
if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node(hash, key, value, null)))
break;
}
}
...
}
static final boolean casTabAt(Node[] tab, int i,
Node c, Node v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
// 读
public V get(Object key) {
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
...
}
return null;
}
@SuppressWarnings("unchecked")
static final Node tabAt(Node[] tab, int i) {
return (Node)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
可以看到在 Java 8 中,CHM 使用了 unsafe 类来实现读写操作
对于写首先使用 compareAndSwapObject(即我们熟悉的 CAS)来更新内存中数组中的元素
对于读则使用了 getObjectVolatile 来读取内存中数组中的元素(在底层其实是用了 C++ 的 volatile 来实现 java 中的 volatile 效果,有兴趣可以看看)
由于读写都是直接对内存操作的,所以通过这样的方式可以保证 put,get 的强一致性,至此真相大白!Java 8 以后 put,get 是可以保证强一致性的!CHM 是通过 compareAndSwapObject 来取代对数组元素直接赋值的操作,通过 getObjectVolatile 来补上无法对数组元素进行 volatile 读的坑来实现的
注意并不是说 CHM 所有的操作都是强一致性的,比如 Java 8 中计算容量的方法 size() 就是弱一致性(Java 7 中此方法反而是强一致性),所以我们说强/弱一致性一定要确定好前提(比如指定 Java 8 下 CHM 的 put,get 这种场景)
总结
其实 Java 8 对 CHM 进行了一番比较彻底的重构,让它的性能大幅度得到了提升,比如弃用 segment 这种设计,改用对每个槽位做分段锁,使用红黑树来降低查询时的复杂度,扩容时多个线程可以一起参与扩容等等,可以说 Java 8 的 CHM 的设计非常精妙,集 CAS,synchroinize,泛型等 Java 基础语法之大成,又有巧妙的算法设计,读后确实让人大开眼界,有机会我会再和大家分享一下其中的设计精髓,另外我们对某些知识点一定要多加思考,最好能自己去翻翻源码验证一下真伪,相信你会对网上的一些谬误会更容易看穿。
完
往期推荐

跳槽后要赔130万!原公司:竞业协议你自己签的
JDK有BUG!!!
年年出妖事,一例由JSON解析导致的"薛定谔BUG"排查过程记录
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️