
深入浅出 Zookeeper 中的 ZAB 协议
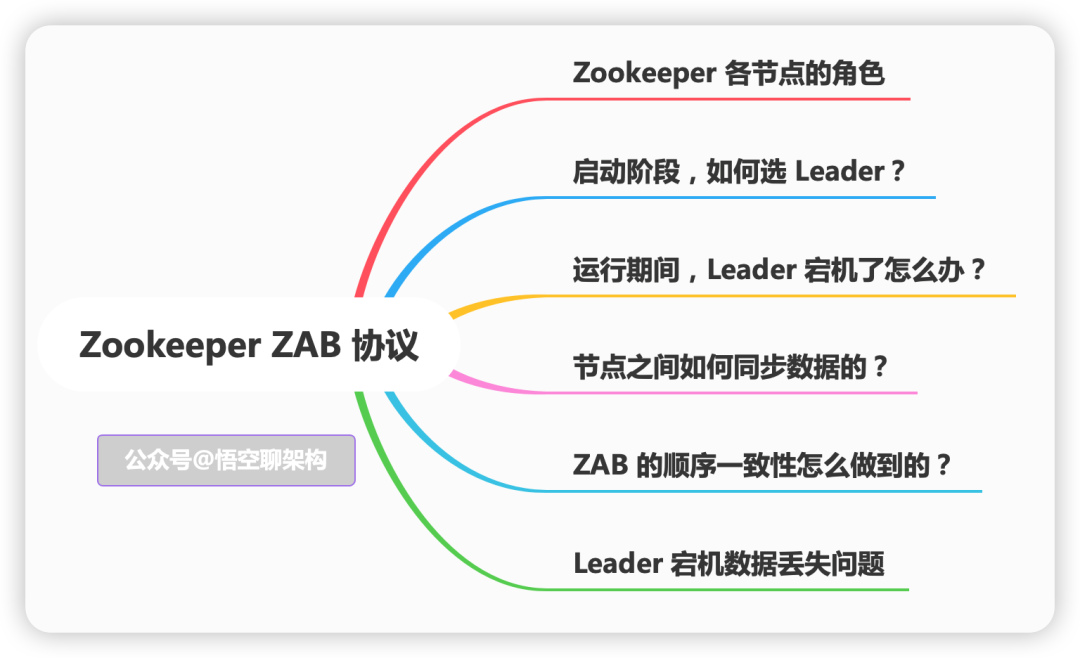
本文主要内容如下:
ZAB 协议的全称是 Zookeeper Atomic Broadcase,原子广播协议。
作用:通过这个 ZAB 协议可以进行集群间主备节点的数据同步,保证数据的一致性。
在讲解 ZAB 协议之前,我们必须要了解 Zookeeper 的各节点的角色。
Zookeeper 各节点的角色
Leader
负责处理客户端发送的 读、写事务请求。这里的事务请求可以理解这个请求具有事务的 ACID 特性。同步 写事务请求给其他节点,且需要保证事务的顺序性。状态为 LEADING。
Follower
负责处理客户端发送的读请求 转发写事务请求给 Leader。 参与 Leader 的选举。 状态为 FOLLOWING。
Observer
和 Follower 一样,唯一不同的是,不参与 Leader 的选举,且状态为 OBSERING。
可以用来线性扩展读的 QPS。
启动阶段,如何选 Leader?
Zookeeper 刚启动的时候,多个节点需要找出一个 Leader。怎么找呢,就是用投票。
比如集群中有两个节点,A 和 B,原理图如下所示:
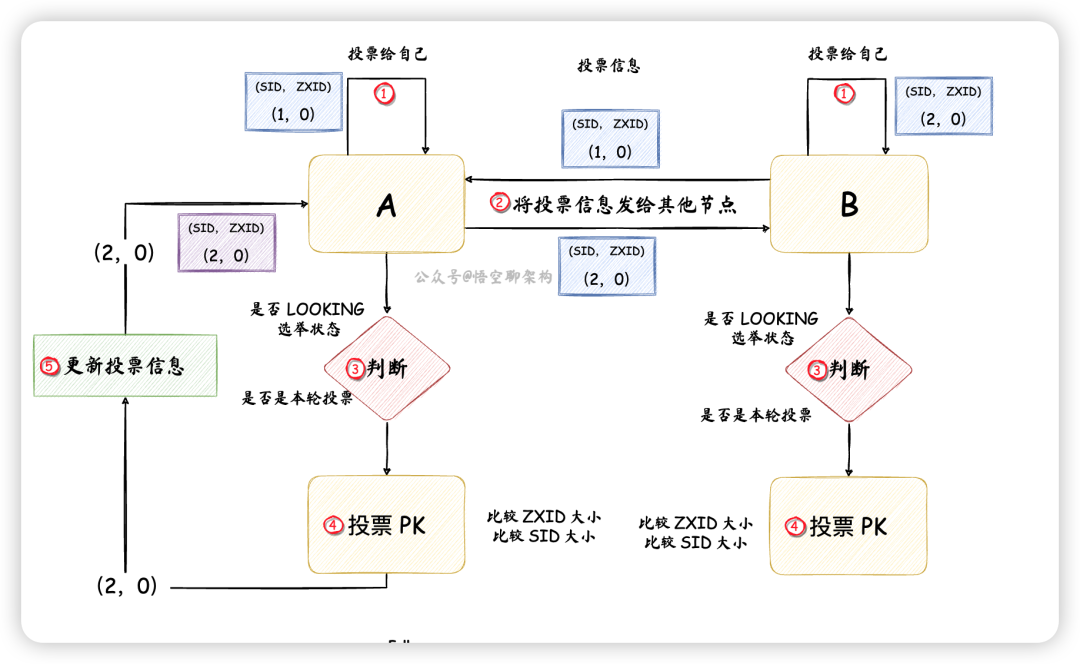
节点 A 先 投票给自己,投票信息包含节点 id(SID)和一个ZXID,如 (1,0)。SID 是配置好的,且唯一,ZXID 是唯一的递增编号。节点 B 先 投票给自己,投票信息为(2,0)。然后节点 A 和 B 将自己的投票信息 投票给集群中所有节点。节点 A 收到节点 B 的投票信息后, 检查下节点 B 的状态是否是本轮投票,以及是否是正在选举(LOOKING)的状态。投票 PK:节点 A 会将自己的投票和别人的投票进行 PK,如果别的节点发过来的 ZXID 较大,则把自己的投票信息 更新为别的节点发过来的投票信息,如果 ZXID 相等,则比较 SID。这里节点 A 和 节点 B 的 ZXID 相同,SID 的话,节点 B 要大些,所以节点 A 更新投票信息为(2,0),然后将投票信息再次发送出去。而节点 B不需要更新投票信息,但是下一轮还需要再次将投票发出去。
这个时候节点 A 的投票信息为(2,0),如下图所示:
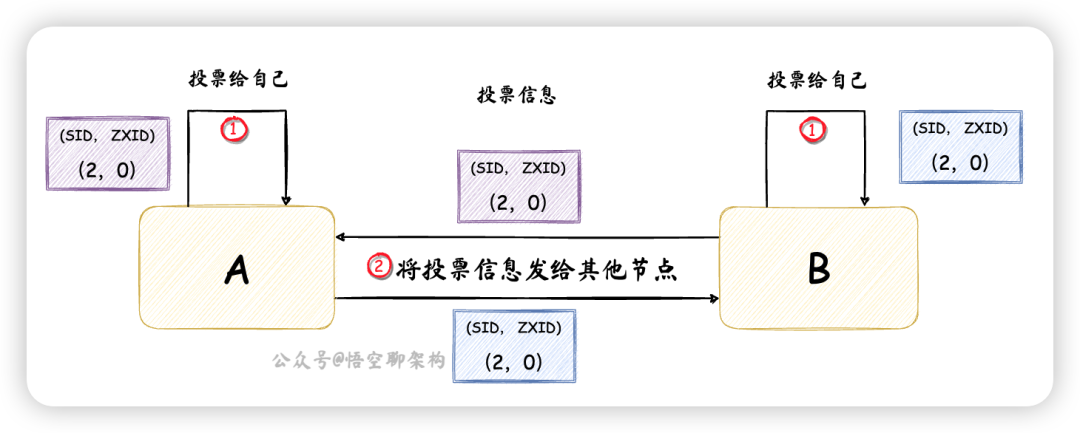
统计投票:每一轮投票,都会统计每台节点收到的投票信息,判断是否有 过半的节点收到了相同的投票信息。节点 A 和 节点 B 收到的投票信息都为(2,0),且数量来说,大于一半节点的数量,所以将节点 B 选出来作为 Leader。更新节点状态:节点 A 作为 Follower,更新状态为 FOLLOWING,节点 B 作为Leader,更新状态为 LEADING。
运行期间,Leader 宕机了怎么办?
在 Zookeeper 运行期间,Leader 会一直保持为 LEADING 状态,直到 Leader 宕机了,这个时候就要重新选 Leader,而选举过程和启动阶段的选举过程基本一致。
需要注意的点:
剩下的 Follower 进行选举,Observer 不参与选举。 投票信息中的 zxid 用的是本地磁盘日志文件中的。如果这个节点上的 zxid 较大,就会被当选为 Leader。如果 Follower 的 zxid 都相同,则 Follower 的节点 id 较大的会被选为 Leader。
节点之间如何同步数据的?
不同的客户端可以分别连接到主节点或备用节点。
而客户端发送读写请求时是不知道自己连的是Leader 还是 Follower,如果客户端连的是主节点,发送了写请求,那么 Leader 执行 2PC(两阶段提交协议)同步给其他 Follower 和 Observer 就可以了。但是如果客户端连的是 Follower,发送了写请求,那么 Follower 会将写请求转发给 Leader,然后 Leader 再进行 2PC 同步数据给 Follower。
两阶段提交协议:
第一阶段:Leader 先发送 proposal 给 Follower,Follower 发送 ack 响应给 Leader。如果收到的 ack 过半,则进入下一阶段。 第二阶段: Leader 从磁盘日志文件中加载数据到内存中,Leader 发送 commit 消息给 Follower,Follower 加载数据到内存中。
我们来看下 Leader 同步数据的流程:

① 客户端发送写事务请求。 ② Leader 收到写请求后,转化为一个 "proposal01:zxid1" 事务请求,存到磁盘日志文件。 ③ 发送 proposal 给其他 Follower。 ④ Follower 收到 proposal 后,Follower 写磁盘日志文件。
接着我们看下 Follower 收到 Leader 发送的 proposal 事务请求后,怎么处理的:
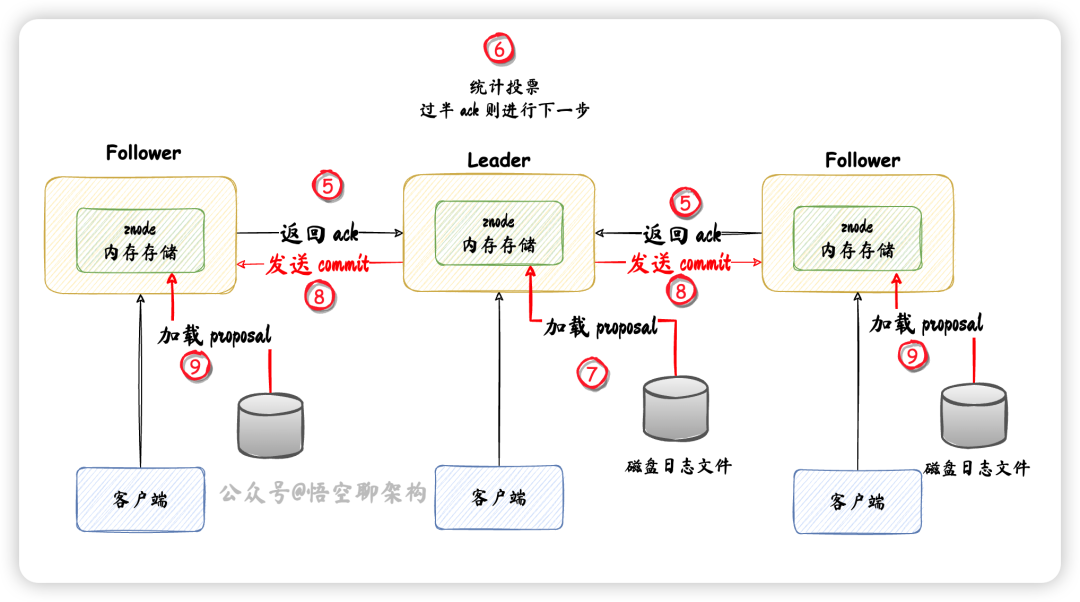
⑤ Follower 返回 ack 给 Leader。 ⑥ Leader 收到超过一半的 ack,进行下一阶段 ⑦ Leader 将磁盘中的日志文件的 proposal 加载到 znode 内存数据结构中。 ⑧ Leader 发送 commit 消息给所有 Follower 和 Observer。 ⑨ Follower 收到 commit 消息后,将 磁盘中数据加载到 znode 内存数据结构中。
现在 Leader 和 Follower 的数据都是在内存数据中的,且是一致的,客户端从 Leader 和 Follower 读到的数据都是一致的。
ZAB 的顺序一致性怎么做到的?
Leader 发送 proposal 时,其实会为每个 Follower 创建一个队列,都往各自的队列中发送 proposal。
如下图所示是 Zookeeper 的消息广播流程:
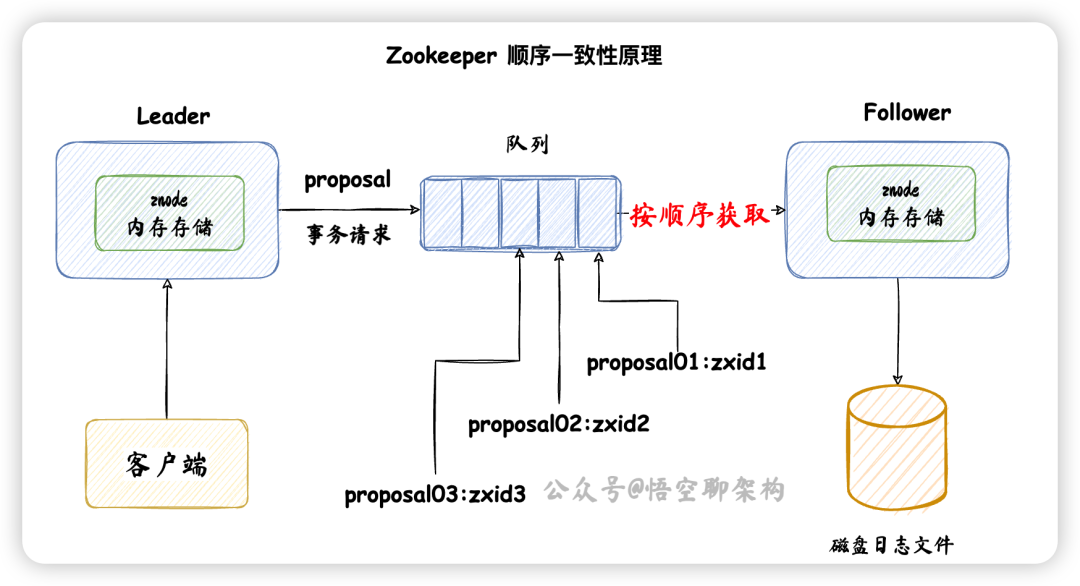
客户端发送了三条写事务请求,对应的 proposal 为
proposal01:zxid1
proposal02:zxid2
proposal03:zxid3
Leader 收到请求后,依次放到队列中,然后 Follower 依次从队列中获取请求,这样就保证了数据的顺序性。
Zookeeper 到底是不是强一致性?
官方定义:顺序一致性。
不保证强一致性,为什么呢?
因为 Leader 再发送 commit 消息给所有 Follower 和 Observer 后,它们并不是同时完成 commit 的。
比如因为网络原因,不同节点收到的 commit 较晚,那么提交的时间也较晚,就会出现多个节点的数据不一致,但是经过短暂的时间后,所有节点都 commit 后,数据就保持同步了。
另外 Zookeeper 支持强一致性,就是手动调用 sync 方法来保证所有节点都 commit 才算成功。
这里有个问题:如果某个节点 commit 失败,那么 Leader 会进行重试吗?如何保证数据的一致性?欢迎讨论。
Leader 宕机数据丢失问题
第一种情况:假设 Leader 已经将消息写入了本地磁盘,但是还没有发送 proposal 给 Follower,这个时候 Leader 宕机了。
那就需要选新的 Leader,新 Leader 发送 proposal 的时候,包含的 zxid 自增规律会发生一次变化:
zxid 的高 32 位自增 1 一次,高 32 位代表 Leader 的版本号。 zxid 的低 32 位自增 1,后续还是继续保持自增长。
当老 Leader 恢复后,会转成 Follower,Leader 发送最新的 proposal 给它时,发现本地磁盘的 proposal 的 zxid 的高 32 位小于新 Leader 发送的 proposal,就丢弃自己的 proposal。
第二种情况:如果 Leader 成功发送了 commit 消息给 Follower,但是所有或者部分 Follower 还没来得及 commit 这个 proposal,也就是加载磁盘中的 proposal 到 内存中,这个时候 Leader 宕机了。
那么就需要选出磁盘日志中 zxid 最大的 Follower,如果 zxid 相同,则比较节点 id,节点 id 大的作为 Leader。
本篇尽量用大白话+画图的方式进行讲解,希望能给大家带来启发。如有不足,欢迎留言讨论。
参考资料:
《从Paxos到Zookeeper 分布式一致性原理与实践》
https://time.geekbang.org/column/article/229975