
用得到的Python数据可视化探索实例,拿走不谢!
利用可视化探索图表
df_iris[['sepal length (cm)']].plot.line()
plt.show()
ax = df[['sepal length (cm)']].plot.line(color='green',title="Demo",style='--')
ax.set(xlabel="index", ylabel="length")
plt.show()
df = df_iris
df.plot.scatter(x='sepal length (cm)', y='sepal width (cm)')
from matplotlib import cm
cmap = cm.get_cmap('Spectral')
df.plot.scatter(x='sepal length (cm)',
y='sepal width (cm)',
s=df[['petal length (cm)']]*20,
c=df['target'],
cmap=cmap,
title='different circle size by petal length (cm)')
df[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)','petal width (cm)']].plot.hist()
2 df.target.value_counts().plot.bar()
df.target.value_counts().plot.pie(legend=True)
df.boxplot(column=['target'],figsize=(10,5))
数据探索实战分享
# 读取数据
df = pd.read_csv("./ss13husa.csv")
# 栏位种类数量
df.shape
# (756065,231)
# 栏位数值范围
df.describe()pusa = pd.read_csv("ss13pusa.csv") pusb = pd.read_csv("ss13pusb.csv")
# 串接两份数据
col = ['SCHL','PINCP','ESR']
df['ac_survey'] = pd.concat([pusa[col],pusb[col],axis=0)group = df['ac_survey'].groupby(by=['SCHL']) print('学历分布:' + group.size())
group = ac_survey.groupby(by=['SCHL']) print('平均收入:' +group.mean())df = pd.read_csv("./housing.data")
# 栏位种类数量
df.shape
# (506, 14)
#栏位数值范围df.describe()
import matplotlib.pyplot as plt
df[['MEDV']].plot.hist()
plt.show()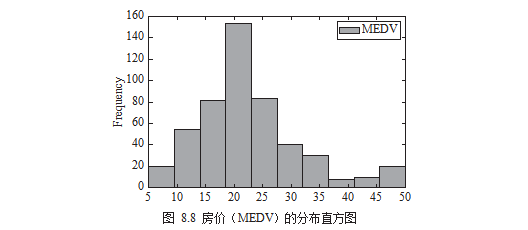
# draw scatter chart
df.plot.scatter(x='MEDV', y='RM') .
plt.show()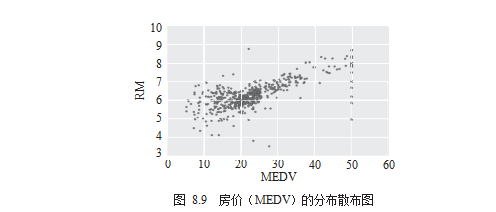
# compute pearson correlation
corr = df.corr()
# draw heatmap
import seaborn as sns
corr = df.corr()
sns.heatmap(corr)
plt.show()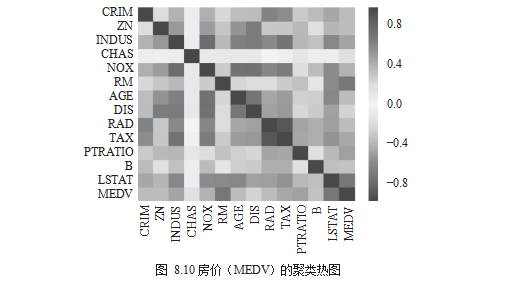
评论