
基于OpenCV的气体泵扫描仪数字识别系统
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

综述
2012年iOS应用商店中发布了一个名为FuelMate的Gas跟踪应用。小伙伴们可以使用该应用程序跟踪汽油行驶里程,以及有一些有趣的功能,例如Apple Watch应用程序、vin.li集成以及基于趋势mpg的视觉效果。

燃料伴侣
对此我们有一个新想法,该如何添加一个功能帮助我们在泵中扫描燃油,并在应用程序中输入燃油信息?让我们深入研究如何实现这一目标。
技术
对于这个项目的我们首先应该编写一个简单的Python应用程序以拍摄汽油泵的图像,然后尝试从中读取数字。OpenCV是用于计算机视觉应用程序的流行的跨平台库。它包括各种图像处理实用程序以及某些机器学习功能。除此之外我们希望可以先使用Python对其进行原型设计,然后将处理代码转换为C ++以在iOS应用程序上运行。
目标
我们首先要考虑以下两个问题:
1.我们可以从图像中分离出数字吗?
2.我们可以确定图像代表哪个数字吗?
数字分割
如何确定图像中的数字有多种方法,但是我提出了使用简单的图像阈值法来尝试查找数字的方法。
图像阈值化的基本思想是将图像转换为灰度,然后说灰度值小于某个常数的任何像素,则该像素为一个值,否则为另一个。最后,您得到的二进制图像只有两种颜色,在大多数情况下只是黑白图像。
这个概念在OCR应用中非常有效,但是主要问题是决定对该阈值使用什么。我们可以选择一些常量,也可以使用OpenCV选择其他一些选项。我们可以使用自适应阈值而不是使用常数,这将使用图像的较小部分并确定要使用的不同阈值。这在具有不同照明情况的应用中特别有用,特别是在扫描气泵中。
将图像设置为阈值后,可以使用OpenCV的findContours方法查找图像中连接了白色像素部分的区域。绘制轮廓后,便可以裁剪出这些区域并确定它们是否可能是数字以及它是什么数字。
基本图像处理流程
这是我在测试图像处理中使用的原始图像。它有一些眩光点,但是图像相当干净。让我们逐步完成获取此源图像的过程,并尝试将其分解为单个数字。

原始图片
影像准备
在开始图像处理流程之前,我们决定先调整一些图像属性,然后再继续。这有点试验和错误,但注意到,当我们调整图像的曝光度时,可以获得更好的结果。下面是使用Python调整后的图像,相当于曝光(阿尔法)的图像cv::Mat::convertTo这是刚刚在图像垫乘法操作cv2.multiply(some_img, np.array([some_alpha]),

调整曝光
灰阶
将图像转换为灰度。

转换为灰度
模糊
模糊图像以减少噪点。我们尝试了许多不同的模糊选项,但仅用轻微的模糊就找到了最佳结果。

稍微模糊
阈值图像转换为黑白图像
在下图中,使用cv2.adaptiveThreshold带有cv2.ADAPTIVE_THRES_GAUSSIAN_C选项的方法。此方法采用两个参数,块大小和要调整的常数。确定这两者需要一些试验和错误,更多有关优化部分的内容。
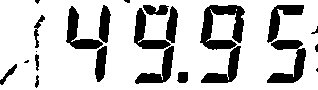
阈值为黑/白
填补空白
由于大多数燃油泵都使用某种7段LCD显示屏,因此数字中存在一些细微的间隙,无法使用轮廓绘制方法,因此我们需要使这些段看起来相连。在这种情况下,我们将转到erode图像来弥补这些差距。由于大家可能希望使用,所以这似乎向后看,dilate但是这些方法通常适用于图像的白色部分。在我们的案例中,我们正在“侵蚀”白色背景以使数字看起来更大。
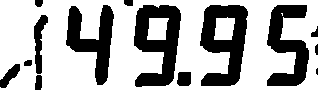
侵蚀出来的数字
反转图像
在尝试在图像中查找轮廓之前,我们需要反转颜色,因为该findContours方法将找到白色的连接部分,而当前的数字是黑色。
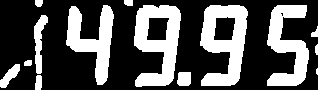
颜色反转
在图像上找到轮廓
下图显示了我们的原始图像,该图像在上图的每个轮廓上都有包围框。大家可以看到它找到了数字,但也找到了一堆不是数字的东西,因此我们需要将它们过滤掉。

红色框显示所有找到的轮廓
轮廓过滤
1.现在我们有了许多轮廓,我们需要找出我们关心的轮廓。浏览了一堆气泵的显示和场景后,使用一套适用于轮廓的快速规则。
2.收集所有我们将分类为潜在小数的正方形轮廓。
3.扔掉任何不是正方形或高矩形的东西。
4.使轮廓与某些长宽比匹配。LCD显示屏中的十个数字中有九个数字的长宽比类似于下面的蓝色框高光之一。该规则的例外是数字“ 1”,其长宽比略有不同。通过使用一些样本轮廓,我将0–9!1方面确定为0.6,将1方面确定为0.3。它将使用这些比率和+/-缓冲区来确定轮廓是否是我们想要的东西,并收集这些轮廓。
5.对潜在数字应用一组附加规则,在这里我们将确定轮廓边界是否偏离所有其他潜在数字的平均高度或垂直位置。由于数字的大小应相同,并且在相同的Y上对齐,因此我们可以丢弃它认为是数字的任何轮廓,但不能像其他轮廓那样将其对齐和调整大小。

蓝色矩形显示我们的数字/十进制,红色被忽略
预测
有两个等高线轮廓,一个带潜在位数,一个带潜在小数位,我们可以使用这些轮廓边界裁剪图像,并将其输入经过训练的系统中以预测其值。有关此过程的更多信息,请参见“数字培训”部分。

查找小数
在图像中查找小数点是要解决的另一个问题。由于它很小,有时会连接到它旁边的手指,因此使用我们在手指上使用的方法来确定它似乎有问题。当我们过滤轮廓时,我们收集了可能是十进制的正方形轮廓。从上一步获得经过验证的数字轮廓之后,我们将找到数字的最左x位置和最右x位置,以确定我们期望的小数位数。然后,我们将遍历那些潜在的小数,确定它是否在该空间以及该空间的下半部分,并将其分类为小数。找到小数点后,我们可以将其插入到我们上面预测的数字字符串中。

只在黄色部分中查找小数
数字培训
在机器学习的世界中,解决OCR问题是一个分类问题。我们建立了一组训练有素的数据,例如图像处理中的数字,将它们分类为某种东西,然后使用该数据来匹配任何新图像。一旦基本的图像隔离功能开始工作,我就创建了一个脚本,该脚本可以遍历图像文件夹,运行数字隔离代码,然后将裁剪的数字保存到新文件夹中供我查看。运行完之后,我会有一个未经训练的数字文件夹,然后可以用来训练系统。

由于OpenCV已经包含了k近邻(k-NN)实现,因此无需引入任何其他库。为了进行训练,我们浏览了数字作物的文件夹,然后将其放入标有0–9的新文件夹中,因此每个文件夹中都有一个数字的不同版本的集合。我们没有大量的这些图像,但是有足够的证据来证明这是可行的。由于这些数字是相当标准的,我认为我不需要大量训练有素的图像就可以相当准确。
k-NN工作原理的基础是,我们将以黑白方式加载每个图像,将该图像存储在每个像素处于打开或关闭状态的数组中,然后将这些打开/关闭像素与特定的数字相关联。然后,当我们要预测一个新图像时,它将找出哪个训练图像与这些像素最匹配,然后向我们返回最接近的值。
整理好数字后,将创建一个新的脚本,该脚本将遍历这些文件夹,获取每个图像并将该图像与数字关联。到目前为止,在大多数代码中,一般的图像处理概念在Python和C ++中都应用相同,但是在这里会有细微的差别。
在大多数此类应用程序的Python示例中,分类被写入两个文件,一个包含分类,另一个包含该分类的图像内容。通常使用NumPy和标准文本文件完成此操作。但是,由于我想在iOS应用程序上重用该系统,因此我需要想出一种可以拥有跨平台分类文件的方式。当时,我什么都找不到,因此最终编写了一个快速实用程序,该实用程序将从Python中获取分类数据并将其序列化为JSON文件,我可以在OpenCV的FileStorage系统的C ++端使用它。这不漂亮,但是我写了一个简单的MatPython中的序列化方法,它将为OpenCV创建合适的结构以在iOS端读取。现在,当我训练数字时,我将获得NumPy文件供我的Python测试使用,然后获取一个JSON文档,我可以将其拖到我的iOS应用程序中。您可以在此处看到该代码。
优化
一旦确定了数字隔离和预测的两个目标,就需要对算法进行优化,以预测泵的新图像上的数字。
在优化的初始阶段,创建了一个简单的Playground应用程序,其中使用了OpenCV提供的一些简单的UI组件。使用这些组件,可以创建一些简单的轨迹栏,以左右滑动并更改不同的值并重新处理图像。围绕该cv2.imshow方法创建了一个小包装程序,该方法可以平铺显示的窗口,因为我讨厌总是重新放置它们,
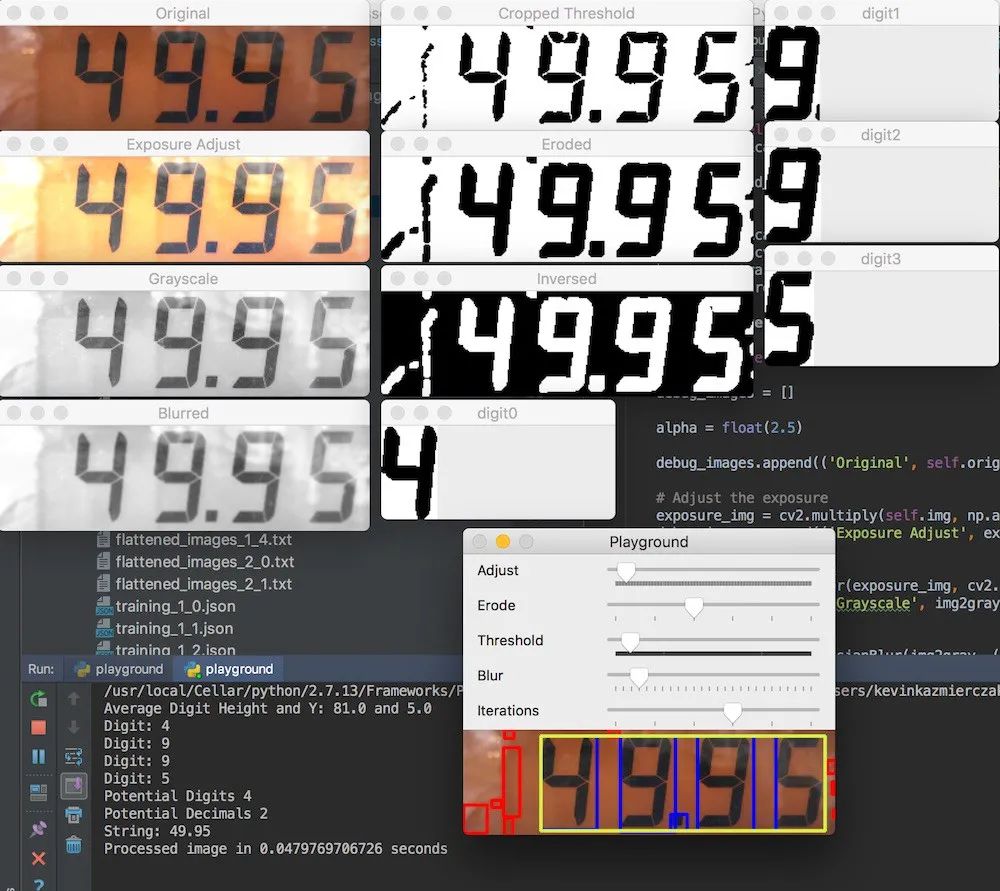
尝试不同的变量
我们可以加载不同的图像,并在图像处理中尝试变量的不同变化,并确定最佳的组合。
自动化
在每个图像上测试不同的变量是上手的好方法,但是我们想要一种更好的方法来验证是否更改了一个图像的变量是否会对其他任何图像产生影响。为此,我们想出了针对这些图像进行一些自动化测试的系统。
我拍摄了每个测试图像,并将它们放在文件夹中。然后,我用图像中期望的数字来命名每个文件,并用小数点“ A”表示。应用程序可以加载该目录中的每个图像并预测数字,然后将其与文件名中的数字进行比较以确定是否匹配。这使我们可以针对所有不同的图像快速尝试更改。
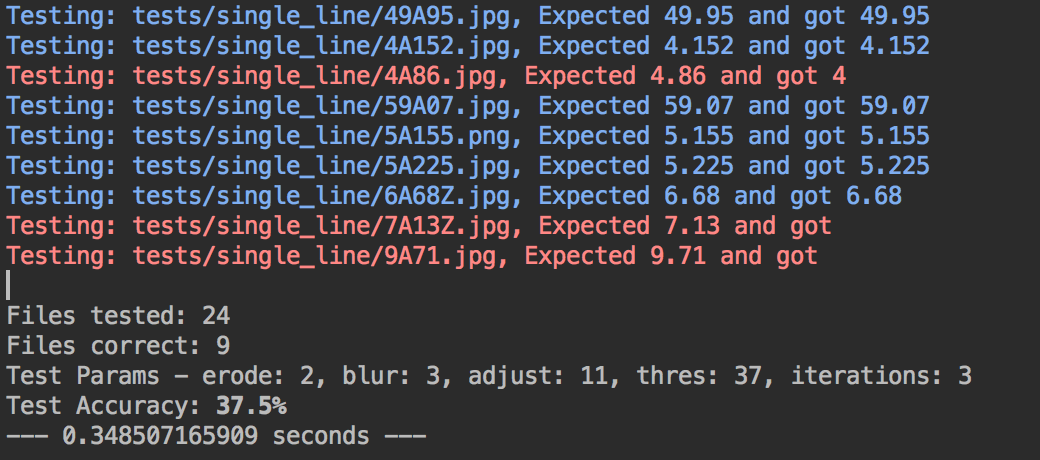
自动测试输出
更进一步,我创建了此脚本的不同版本,该脚本将尝试对这组图像进行模糊,阈值等变量的几乎每种组合,并找出最优化的变量集将具有最佳的性能。准确性。该脚本在计算机上花费了相当长的时间才能运行,大约需要7个小时,但是最后提出了一组不同的变量,这些变量在我们手动测试时找不到。
结论
这是否是任何人实际上都会使用的功能尚待确定,但这在实现某些机器学习概念和使用OpenCV方面是一个有趣的练习。到目前为止,在我们的测试中,应用程序最大的问题是泵显示屏上的眩光。根据泵上的照明和手机的角度,可能会导致某些扫描失效。
代码链接:https://github.com/kazmiekr/GasPumpOCR
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~