
GraphQL 基础实践
编者按:本文作者奇舞团前端开发工程师何文力,同时也是 W3C CSS 工作组成员。
本次内容是基于之前分享的文字版,若想看重点的话,可以看之前的 PPT (https://ppt.baomitu.com/d/4248c64a)。
什么是 GraphQL
GraphQL 是一款由 Facebook 主导开发的数据查询和操作语言, 写过 SQL 查询的同学可以把它想象成是 SQL 查询语言,但 GraphQL 是给客户端查询数据用的。虽然这让你听起来觉得像是一款数据库软件,但实际上 GraphQL 并不是数据库软件。你可以将 GraphQL 理解成一个中间件,是连接客户端和数据库之间的一座桥梁,客户端给它一个描述,然后从数据库中组合出符合这段描述的数据返回。这也意味着 GraphQL 并不关心数据存在什么数据库上。
同时 GraphQL 也是一套标准,在这个标准下不同平台不同语言有相应的实现。GraphQL 中还设计了一套类型系统,在这个类型系统的约束下,可以获得与 TypeScript 相近的相对安全的开发体验。
GraphQL 解决了什么问题
我们先来回顾一下我们已经非常熟悉的 RESTful API 设计。简单的说 RESTful API 主要是使用 URL 的方式表达和定位资源,用 HTTP 动词来描述对这个资源的操作。
我们以 IMDB 电影信息详情页为例子,看看我们得需要什么样的 API 才能满足 RESTful API 设计的要求。先来看看主页面上都需要什么信息。
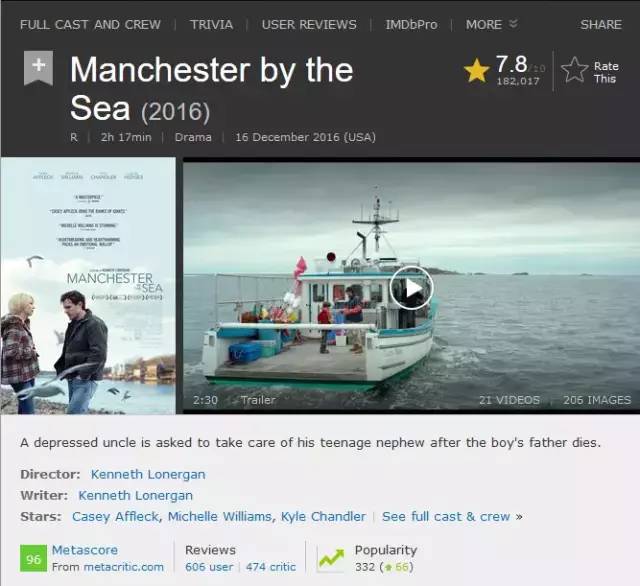
可以看到页面上由电影基本信息,演员和评分/评论信息组成,按照设计要求,我们需要将这三种资源放在不同 API 之下。首先是电影基本信息,我们有 API /movie/:id,给定一个电影ID返回基本信息数据。
假装 GET 一下获得一个 JSON 格式的数据:
{
name: “Manchester by the Sea”,
ratings: “PG-13”,
score: 8.2,
release: “2016”,
actors:[“https://api/movie/1/actor/1/”],
reviews:[“https://api/movie/1/reviews”]
}
这里面包含了我们所需的电影名、分级等信息,以及一种叫做 HyperMedia 的数据,通常是一个 URL,指明了能够获取这个资源的 API 端点地址。如果我们跟着 HyperMedia 指向的连接请求下去,我们就能得到我们页面上所需的所有信息。
GET /api/movue/1/actor/1
{
name: “Ben Affleck”,
dob: “1971-01-26”,
desc: “blablabla”,
movies:[“https://api/movie/1”]
}
GET /api/movie/1/reviews
[
{
content: “Its’s as good as…”,
score: 9
}
]
最后根据需要,我们要将所有包含需要信息的 API 端点都请求一遍,对于移动端来说,发起一个 HTTP 请求还是比较消耗资源的,特别是在一些网络连接质量不佳的情况下,一下发出多个请求反而会导致不好的体验。
而且在这样的 API 设计之中,特定资源分布在特定的 API 端点之中,对于后端来说写起来是挺方便的,但对于Web端或者客户端来说并不一定。例如在 Android 或 iOS 客户端上,发版升级了一个很爆炸的功能,同一个API上可能为了支持这个功能而多吐一些数据。但是对于未升级的客户端来说,这些新数据是没有意义的,也造成了一定的资源浪费。如果单单将所有资源整合到一个 API 之中,还有可能会因为整合了无关的数据而导致数据量的增加。
而 GraphQL 就是为了解决这些问题而来的,向服务端发送一次描述信息,告知客户端所需的所有数据,数据的控制甚至可以精细到字段,达到一次请求获取所有所需数据的目的。
GraphQL Hello World
GraphQL 请求体
我们先来看一下一个 GraphQL 请求长什么样:
query myQry ($name: String!) {
movie(name: “Manchester”) {
name
desc
ratings
}
}
这个请求结构是不是和 JSON 有那么点相似?这是 Facebook 故意设计成这样的,希望你读完之后就能体会到 Facebook 的用心良苦了。
那么,上面的这个请求描述称为一个 GraphQL 请求体,请求体即用来描述你要从服务器上取什么数据用的。一般请求体由几个部分组成,从里到外了解一下。
首先是字段,字段请求的是一个数据单元。同时在 GraphQL 中,标量字段是粒度最细的一个数据单元了,同时作为返回 JSON 响应数据中的最后一个字段。也就是说,如果是一个 Object,还必须选择至少其中的一个字段。
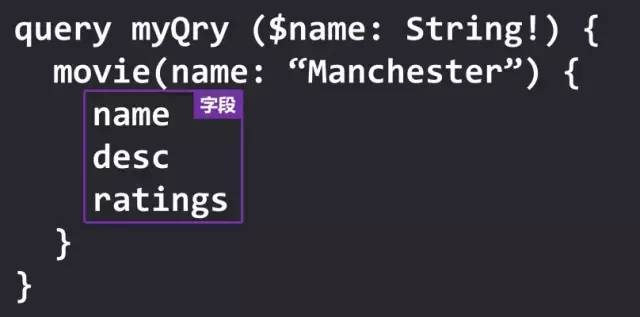
把我们所需要的字段合在一起,我们把它称之为某某的选择集。上面的 name、desc、ratings 合在一起则称之为 movie 的选择集,同理,movie 是 myQry 的选择集。需要注意的是,在标量上使用不能使用选择集这种操作,因为它已经是最后一层了。
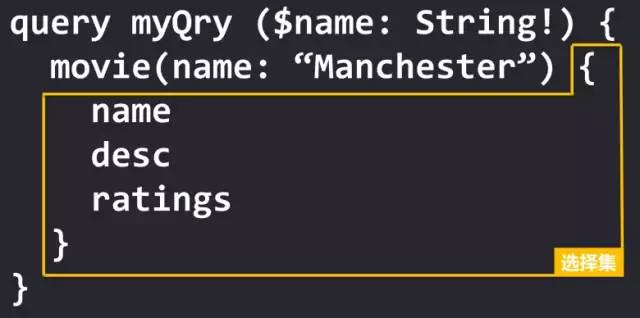
在 movie 的旁边,name: "Manchester",这个代表着传入 movie 的参数,参数名为 name 值为Manchester,利用这些参数向服务器表达你所需的数据需要符合什么条件。
最后我们来到请求体的最外层:
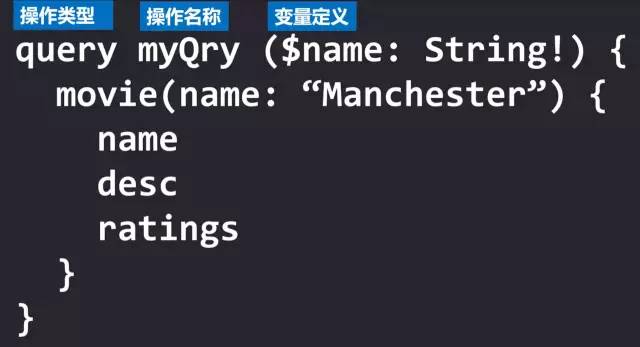
操作类型:指定本请求体要对数据做什么操作,类似与 REST 中的 GET POST。GraphQL 中基本操作类型有 query 表示查询,mutation 表示对数据进行操作,例如增删改操作,subscription 订阅操作。
操作名称:操作名称是个可选的参数,操作名称对整个请求并不产生影响,只是赋予请求体一个名字,可以作为调试的依据。
变量定义:在 GraphQL 中,声明一个变量使用$符号开头,冒号后面紧跟着变量的传入类型。如果要使用变量,直接引用即可,例如上面的 movie 就可以改写成 movie(name: $name)。
如果上述三者都没有提供,那么这个请求体默认会被视为一个 query 操作。
请求的结果
如果我们执行上面的请求体,我们将会得到如下的数据:
{
"data": {
"movie": {
"name": "Manchester By the Sea",
"desc": "A depressed uncle is asked to take care of his teenage nephew after the boy's father dies. ",
"ratings": "R"
}
}
}
仔细对比结果和请求体的结构,你会发现,与请求体的结构是完全一致的。也就是说,请求体的结构也确定了最终返回数据的结构。
GraphQL Server
在前面的 REST 举例中,我们请求多个资源有多个 API 端点。在 GraphQL 中,只有一个 API 端点,同样也接受 GET 和 POST 动词,如要操作 mutation 则使用 POST 请求。
前面还提到 GraphQL 是一套标准,怎么用呢,我们可以借助一些库去解析。例如 Facebook 官方的 GraphQL.js。以及 Meteor 团队开发的 Apollo,同时开发了客户端和服务端,同时也支持流行的 Vue 和 React 框架。调试方面,可以使用 Graphiql 进行调试,得益于 GraphQL 的类型系统和 Schema,我们还可以在 Graphiql 调试中使用自动完成功能。
Schema
前面我们提到,GraphQL 拥有一个类型系统,那么每个字段的类型是怎么约定的呢?答案就在本小节中。在 GraphQL 中,类型的定义以及查询本身都是通过 Schema 去定义的。GraphQL 的 Schema 语言全称叫 Schema Definition Language。Schema 本身并不代表你数据库中真实的数据结构,它的定义决定了这整个端点能干些什么事情,确定了我们能向端点要什么,操作什么。再次回顾一下前面的请求体,请求体决定了返回数据的结构,而 Schema 的定义决定了端点的能力。
接下来我们就通过一个一个的例子了解一下 Schema。
类型系统、标量类型、非空类型、参数
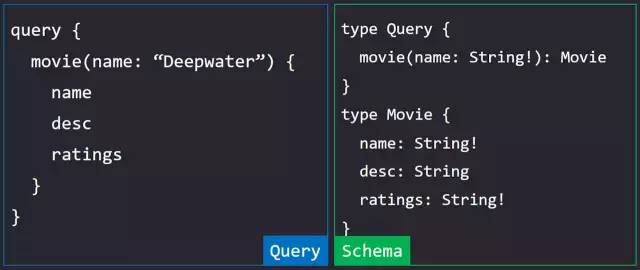
先看右边的 Schema:type 是 GraphQL Schema 中最基本的一个概念,表示一个 GraphQL 对象类型,可以简单地将其理解为 JavaScript 中的一个对象,在 JavaScript 中一个对象可以包含各种 key,在 GraphQL 中,type 里面同样可以包含各种字段(field),而且字段类型不仅仅可以是标量类型,还可以是 Schema 中定义的其他 type。例如上面的 Schema 中, Query 下的 movie 字段的类型就可以是 Movie。
在 GraphQL 中,有如下几种标量类型:Int, Float, String, Boolean, ID ,分别表示整型、浮点型、字符串、布尔型以及一个ID类型。ID类型代表着一个独一无二的标识,ID 类型最终会被转化成String类型,但它必须是独一无二的,例如 mongodb 中的 _id 字段就可以设置为ID类型。同时这些标量类型可以理解为 JavaScript 中的原始类型,上面的标量类型同样可以对应 JavaScript 中的 Number, Number, String, Boolean, Symbol 。
在这里还要注意一点,type Query, Query 类型是 Schema 中所有 query 查询的入口,类似的还有 Mutation 和 Subscription,都作为对应操作的入口点。
在type Query下的 movie 字段中,我们使用括号定义我们可以接受的参数名和参数的类型。在上面的 Schema 中,后面紧跟着的感叹号声明了此类型是个不可空类型(Non-Nullable),在参数中声明表示该参数不能传入为空。如果感叹号跟在 field 的后面,则表示返回该 type 的数据时,此字段一定不为空。
通过上面的类型定义,可以看到 GraphQL 中的类型系统起到了很重要的角色。在本例中,Schema 定义了 name 为 String类型,那么你就不能传 Int类型进去,此时会抛出类型不符的错误。同样的,如果传出的 ratings 数据类型不为 String,也同样会抛出类型不符的错误。
列表(List)、枚举类型(Enum)
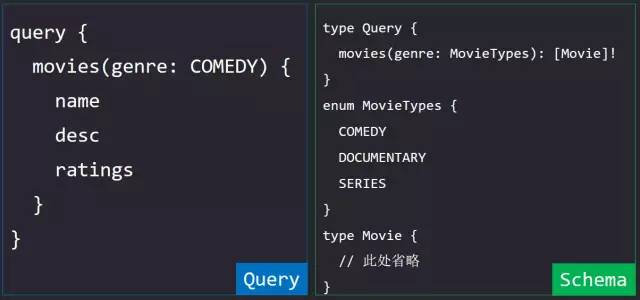
如果我们的某个字段返回不止一个标量类型的数据,而是一组,则需要使用List类型声明,在该标量类型两边使用中括号[]包围即可,与 JavaScript 中数组的写法相同,而且返回的数据也将会是数组类型。
需要注意的是[Movie]!与 [Movie!]两种写法的含义是不同的:前者表示 movies字段始终返回不可为空但Movie元素可以为空。后者表示movies中返回的 Movie 元素不能为空,但 movies字段的返回是可以为空的。
你可能在请求体中注意到,genre 参数的值没有被双引号括起来,也不是任何内置类型。看到 Schema 定义,COMEDY是枚举类型MovieTypes中的枚举成员。枚举类型用于声明一组取值常量列表,如果声明了某个参数为某个枚举类型,那么该参数只能传入该枚举类型内限定的常量名。
传入复杂结构的参数(Input)
前面的例子中,传入的参数均为标量类型,那么如果我们想传入一个拥有复杂结构的数据该怎么定义呢。答案是使用关键字input。其使用方法和type完全一致。
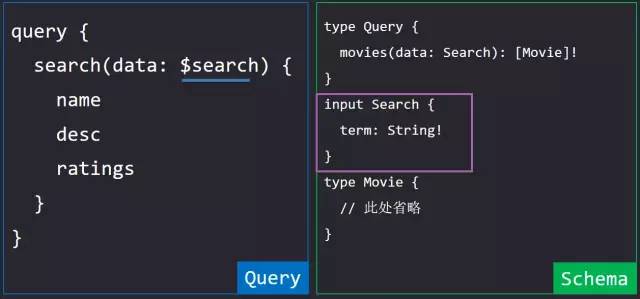
根据本例中的 Schema 定义,我们在查询 search时data的参数必须为
{ term: "Deepwater Horizon" }
别名(Alias)
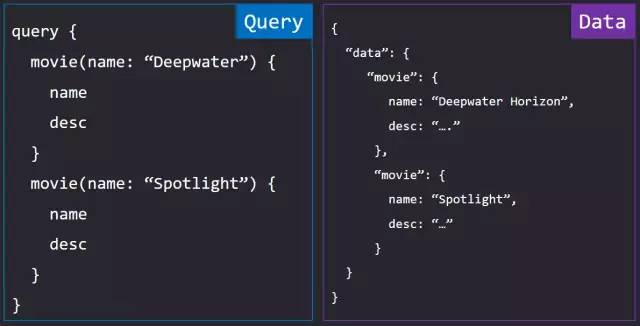
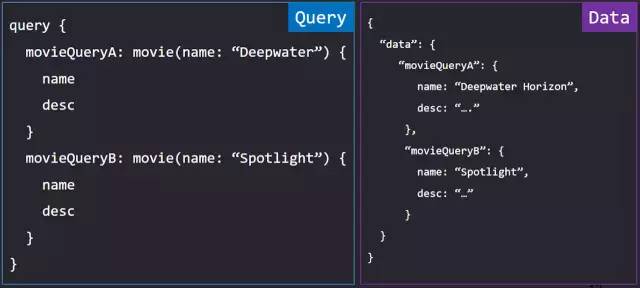
想象这么一个页面,我要列出两个电影的信息做对比,为了发挥 GraphQL 的优势,我要同时查询这两部电影的信息,在请求体中请求 movie 数据。前面我们说到,请求体决定了返回数据的结构。在数据返回前查出两个 key 为 movie 的数据,合并之后由于 key 重复而只能拿到一条数据。那么在这种情况下我们需要使用别名功能。
别名即为返回字段使用另一个名字,使用方法也很简单,只需要在请求体的字段前面使用别名:的形式即可,返回的数据将会自动替换为该名称。
片段(Fragment)、片段解构(Fragment Spread)
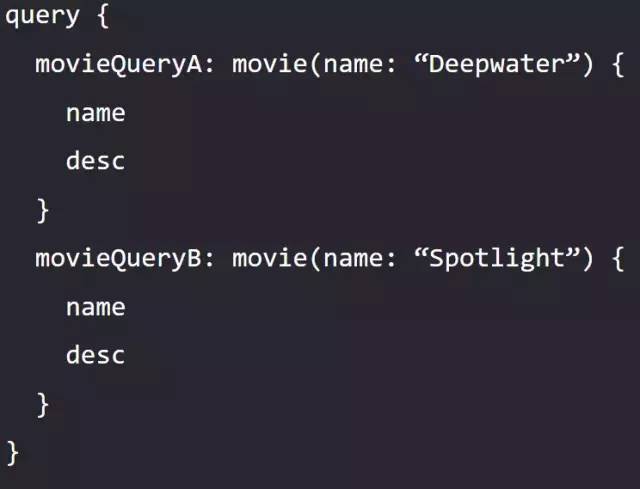
在上面的例子中,我们需要对比两部电影的数据。如果换作是硬件对比网站,需要查询的硬件数量往往不止两个。此时编写冗余的选择集显得非常的费劲、臃肿以及难维护。为了解决这个问题,我们可以使用片段功能。GraphQL 允许定义一段公用的选择集,叫片段。定义片段使用 fragment name on Type 的语法,其中 name为自定义的片段名称,Type为片段来自的类型。
本例中的请求体的选择集公共部分提取成片段之后为
fragment movieInfo on Movie {
name
desc
}
在正式使用片段之前,还需要向各位介绍片段解构功能。类似于 JavaScript 的结构。GraphQL 的片段结构符号将片段内的字段“结构”到选择集中。
接口(Interface)
与其他大多数语言一样,GraphQL 也提供了定义接口的功能。接口指的是 GraphQL 实体类型本身提供字段的集合,定义一组与外部沟通的方式。使用了 implements的类型必须包含接口中定义的字段。
interface Basic {
name: String!
year: Number!
}
type Song implements Basic {
name: String!
year: Number!
artist: [String]!
}
type Video implements Basic {
name: String!
year: Number!
performers: [String]!
}
Query {
search(term: String!): [Basic]!
}
在本例中,定义了一个Basic接口,Song以及Video类型都要实现该接口的字段。然后在search查询中返回该接口。
searchMedia查询返回一组Basic接口。由于该接口中的字段是所有实现了该接口的类型所共有的,在请求体上可以直接使用。而对于特定类型上的其他非共有字段,例如Video中的performers,直接选取是会有问题的,因为searchMedia在返回的数据中类型可能是所有实现了该接口的类型,而在 Song类型中就没有performers字段。此时我们可以借助内联片段的帮助(下面介绍)。
联合类型(Union)
联合类型与接口概念差不多相同,不同之处在于联合类型下的类型之间没有定义公共的字段。在 Union 类型中必须使用内联片段的方式查询,原因与上面的接口类型一致。
union SearchResult = Song | Video
Query {
search(term: String!): [SearchResult]!
}
内联片段(Inline Fragment)
对接口或联合类型进行查询时,由于返回类型的不同导致选取的字段可能不同,此时需要通过内联片段的方式决定在特定类型下使用特定的选择集。内联选择集的概念和用法与普通片段基本相同,不同的是内联片段直接声明在选择集内,并且不需要fragment声明。
查询接口的例子:
query {
searchMedia(term: "AJR") {
name
year
...on Song {
artist
}
...on Video {
performers
}
}
}
首选我们需要该接口上的两个公共字段,并且结果为Song类型时选取artist字段,结果为Video类型时选取performers字段。下面查询联合类型的例子也是一样的道理。
查询联合类型的例子:
query {
searchStats(player: "Aaron") {
...on NFLScore {
YDS
TD
}
...on MLBScore {
ERA
IP
}
}
}
GraphQL 内置指令
GraphQL 中内置了两款逻辑指令,指令跟在字段名后使用。
@include
当条件成立时,查询此字段
query {
search {
actors @include(if: $queryActor) {
name
}
}
}
@skip
当条件成立时,不查询此字段
query {
search {
comments @skip(if: $noComments) {
from
}
}
}
Resolvers
前面我们已经了解了请求体以及 Schema,那么我们的数据到底怎么来呢?答案是来自 Resolver 函数。
Resolver 的概念非常简单。Resolver 对应着 Schema 上的字段,当请求体查询某个字段时,对应的 Resolver 函数会被执行,由 Resolver 函数负责到数据库中取得数据并返回,最终将请求体中指定的字段返回。
type Movie {
name
genre
}
type Query {
movie: Movie!
}
当请求体查询movie时,同名的 Resolver 必须返回Movie类型的数据。当然你还可以单独为name字段使用独立的 Resolver 进行解析。后面的代码例子中将会清楚地了解 Resolver。
使用 ThinkJS 搭建 GraphQL API
本例中我们将使用 ThinkJS 配合 MongoDB 进行搭建 GraphQL API,ThinksJS 的简单易用性会让你爱不释手!
快速安装
首先安装 ThinkJS 脚手架 npm install -g think-cli
使用 CLI 快速创建项目 thinkjs new gqldemo
切换到工程目录中 npm install && npm start
不到两分钟,ThinkJS 服务端就搭建完了,so easy!
配置 MongoDB 数据库
由于本人比较喜欢 mongoose,刚好 ThinkJS 官方提供了 think-mongoose 库快速使用,安装好之后我们需要在 src/config/extend.js中引入并加载该插件。
const mongoose = require('think-mongoose');
module.exports = [mongoose(think.app)];
接下来,在 adapter.js 中配置数据库连接
export.model = {
type: 'mongoose',
mongoose: {
connectionString: 'mongodb://你的数据库/gql',
options: {}
}
};
现在,我们在整个 ThinkJS 应用中都拥有了 mongoose 实例,看看还差啥?数据模型!
借助 ThinkJS 强大的数据 模型功能,我们只需要以数据集合的名称作为文件名建立文件并定义模型即可使用,相比 mongoose 原生的操作更为简单。
本例中我们实现 actor 和 movie 两组数据,在 model 目录下分别建立 actor.js 和 movie.js,并在里面定义模型。
actor.js
module.exports = class extends think.Mongoose {
get schema() {
return {
name: String,
desc: String,
dob: String,
photo: String,
addr: String,
movies: [
{
type: think.Mongoose.Schema.Types.ObjectId,
ref: 'movie'
}
]
};
}
};
movie.js
module.exports = class extends think.Mongoose {
get schema() {
return {
name: String,
desc: String,
ratings: String,
score: Number,
release: String,
cover: String,
actors: [
{
type: think.Mongoose.Schema.Types.ObjectId,
ref: 'actor'
}
]
};
}
};
处理 GraphQL 请求的中间件
要处理 GraphQL 请求,我们就必须拦截特定请求进行解析处理,在 ThinkJS 中,我们完全可以借助中间件的能力完成解析和数据返回。中间件的配置在 middleware.js中进行。
ThinkJS 中配置中间件有三个关键参数:
match: 用于匹配 URL,我们想让我们的请求发送到 /graphql 中进行处理,那么我们对这个路径进行 match 后进行处理;
handle:中间件的处理函数,当 match 到时,此处理函数会被调用执行,我们的解析任务也在这里进行,并将解析结果返回;
options:options 时传给中间件的参数,我们可以在此将我们的 Schema 等内容传给解析器使用。
我们的中间件配置大概长这样:
{
match: '/graphql',
handle: () => {},
options: {}
}
解析 GraphQL 的核心
Apollo Server
Apollo Server 是一款构建在 Node.js 基础上的 GraphQL 服务中间件,其强大的兼容性以及卓越的稳定性是本文选取此中间件的首要因素。
尽管 Apollo Server 没有 ThinkJS 版的中间件,但是万变不离其宗,我们可以通过 Apollo Server Core 中的核心方法 runHttpQuery 进行解析。
将它安装到我们的项目中:npm install apollo-server-core graphql --save
编写中间件
runHttpQuery主要接受两个参数,第一个是 GraphQLServerOptions,这个我们可以不需要配置,留空数组即可;第二个是HttpQueryRequest对象,我们至少需要包含 methods,options以及query,
他们分别表示当前请求的方法,GraphQL服务配置以及请求体。
而GraphQL服务配置中我们至少要给出 schema, schema 应该是一个 GraphQLSchema实例,对于我们前面例子中直接写的 Schema Language,是不能被识别的,此时我们需要借助 graphql-tools 中的 makeExecutableSchema 工具将我们的 Schema 和 Resolvers 进行关联成 GraphQLSchema实例。
将它安装到我们的项目中:npm install graphql-tools --save
编写 Schema 和 Resolver
在转换成 GraphQLSchema 之前,首先要将我们的 Schema 和 Resolver 准备好。
运用前面所学的知识,我们可以很快的编写出一个简单的 Schema 提供查询演员信息和电影信息的接口。
type Movie {
name: String!
desc: String!
ratings: String!
score: Float!
cover: String!
actors: [Actor]
}
type Actor {
name: String!
desc: String!
dob: String!
photo: String!
movies: [Movie]
}
type Query {
movie(name: String!): [Movie]
actor(name: String!): [Actor]
}
接下来,分别编写解析 Query 下 movie和actor字段的 Resolver 函数。
const MovieModel = think.mongoose('movie');
const ActorModel = think.mongoose('actor');
module.exports = {
Query: {
movie(prev, args, context) {
return MovieModel.find({ name: args.name })
.sort({ _id: -1 })
.exec();
},
actor(prev, args, context) {
return ActorModel.find({ name: args.name })
.sort({ _id: -1})
.exec();
}
}
}
为了能够和 Schema 正确关联,Resolver 函数的结构需要与 Schema 的结构保持一致。
到达这一步,有没有发现什么不对呢?

回忆前面的数据模型定义,里面的 movies 和 actors 字段是一组另一个集合中数据的引用,目的是方便建立电影和演员信息之间的关系以及维护,在 Resolver 运行之后,movies 和 actors 字段得到的是一组 id,不符合 Schema 的定义,此时 GraphQL 会抛出错误。
那么这个问题怎么解决呢?前面讲到 Resolver 的时候说到,每个字段都可以对应一个 Resolver 函数,我们分别对 movies 和 actors 字段设置 Resolver 函数,将上一个 Resolver 解析出来的 id 查询一遍得出结果,最终返回的数据就能符合 Schema 的定义了。
const MovieModel = think.mongoose('movie');
const ActorModel = think.mongoose('actor');
module.exports = {
Query: {
movie(prev, args, context) {
return MovieModel.find({ name: args.name })
.sort({ _id: -1 })
.exec();
},
actor(prev, args, context) {
return ActorModel.find({ name: args.name })
.sort({ _id: -1})
.exec();
}
},
Actor: {
movies(prev, args, context) {
return Promise.all(
prev.movies.map(_id => MovieModel.findOne({ _id }).exec())
);
}
},
Movie: {
actors(prev, args, context) {
return Promise.all(
prev.actors.map(_id => ActorModel.findOne({ _id }).exec())
);
}
}
}
其中用到的 prev 参数就是上一个 Resolver 解析出的数据。
组合成 GraphQLSchema 实例
有了 Schema 和 Resolver 之后,我们终于可以把它们变成一个 GraphQLSchema 实例了。
调用 graphql-tools 中的 makeEcecutableSchema 进行组合好,放在 options 里面稍后使用。
此时我们的中间长这样:
const { makeExecutableSchema } = require('graphql-tools');
const Resolvers = require('./resolvers'); // 我们刚写的 Resolver
const Schema = require('./schema'); // 我们刚写的 Schema
module.exports = {
match: '/graphql',
handle: () => {},
options: {
schema: makeExecutableSchema({
typeDefs: Schema,
resolvers: Resolvers
})
}
}
编写 handler

有请apollo-server-core 里面的runHttpQuery出场!
const { runHttpQuery } = require('apollo-server-core');
参照 apollo-server-koa,快速构建出 ThinkJS 版的 apollo-server 中间件。
const { runHttpQuery } = require('apollo-server-core');
module.exports = (options = {}) => {
return ctx => {
return runHttpQuery([ctx], {
method: ctx.request.method,
options,
query:
ctx.request.method === 'POST'
? ctx.post()
: ctx.param()
}).then(
rsp => {
ctx.set('Content-Type', 'application/json');
ctx.body = rsp;
},
err => {
if (err.name !== 'HttpQueryError') throw err;
err.headers &&
Object.keys(err.headers).forEach(header => {
ctx.set(header, err.headers[header]);
});
ctx.status = err.statusCode;
ctx.body = err.message;
}
);
};
};

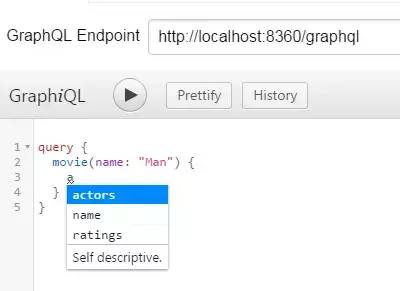
接下来引用到我们中间件的handle配置中,完美,大功告成,用 ThinkJS 搭建的 GraphQL 服务器就此告一段落,npm start 运行起来之后,用 GraphiQL “播放”一下你的请求体(记得自己先往数据库灌数据)。
GraphQL 的优缺点
优点
所见即所得:所写请求体即为最终数据结构
减少网络请求:复杂数据的获取也可以一次请求完成
Schema 即文档:定义的 Schema 也规定了请求的规则
类型检查:严格的类型检查能够消除一定的认为失误
缺点
增加了服务端实现的复杂度:一些业务可能无法迁移使用 GraphQL,虽然可以使用中间件的方式将原业务的请求进行代理,这无疑也将增加复杂度和资源的消耗
完整源代码可以在这里 (https://github.com/NimitzDEV/graphpql-in-thinkjs)找到,中间件可以在这里(https://github.com/NimitzDEV/think-graphql-middleware)找到