
【关于 Complex KBQA】 那些你不知道的事 (下)
作者:杨夕
论文:A Survey on Complex Knowledge Base Question Answering:Methods, Challenges and Solutions
面筋地址:https://github.com/km1994/NLP-Interview-Notes
个人笔记:https://github.com/km1994/nlp_paper_study
六、基于语义解析(SP-based)的方法 vs 基于信息检索(IR-based)的方法 的 挑战和解决策略
在论文中,对 基于语义解析(SP-based)的方法 和 基于信息检索(IR-based)的方法 每个模块容易遇到的问题和常用的解决方法做了介绍:
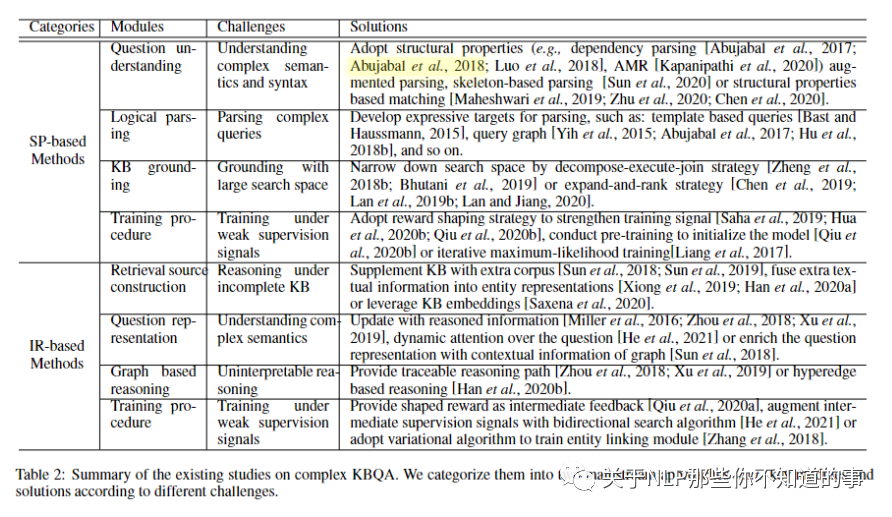
表 2:对复杂 KBQA 的现有研究总结。我们根据不同的挑战将它们分为两种主流方法w.r.t.key模块和解决方案。
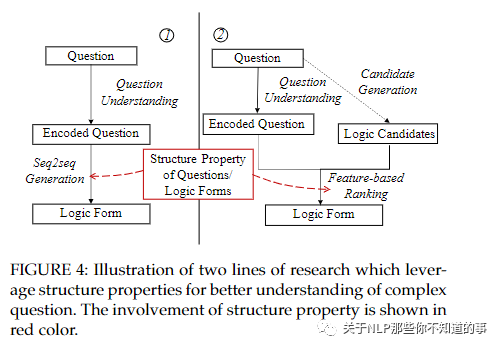
6.1 Understanding Complex Semantics and Syntax
为了更好地理解复杂的自然语言问题,许多现有方法依赖句法解析,例如依赖关系和抽象意义表示 (AMR) ,以提供问题成分和逻辑之间更好的对齐表单元素(例如,实体、关系、实体类型和属性)。这条研究路线在图 4 的左侧进行了说明。
图 4:说明利用结构特性更好地理解复杂问题的两条研究路线。结构性质的参与以红色显示
6.2 Parsing Complex Queries
为了生成可执行的逻辑形式,传统方法首先利用现有的解析器将问题转换为 CCG 派生,然后通过将谓词和参数与知识库中的关系和实体对齐,将其映射到 SPARQL。
例如,问题“谁导演了泰坦尼克号?”可以通过 CCG 解析器解析为 “TARGET(x)∧directed.arg1(e, x)∧directed.arg2(e, T itanic)”。之后,谓词“directed”分别与关系“directedby”对齐,参数“Titanic”与KB中的实体“Titanic”对齐。这样的 CCG 推导可以转移到一个可执行的 SPARQL 查询。
然而,由于本体不匹配问题,这些方法对于复杂问题是次优的。因此,有必要利用知识库的结构进行准确解析,其中解析与知识库的基础一起执行。为了满足复杂问题的组合性,研究人员开发了多种表达逻辑形式作为解析目标。
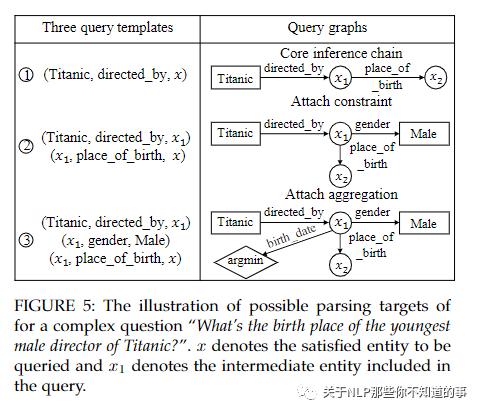
图5:复杂问题“泰坦尼克号最年轻男导演的出生地是什么?”的可能解析目标的说明。x表示要查询的满意实体,x1表示查询中包含的中间实体
从主题实体入手,设计了三个查询模板作为解析目标。我们在图 5 中列出了这三个查询模板。前两个模板返回与主题实体“泰坦尼克号”相距 1 跳和 2 跳的实体。第三个模板返回与主题实体相距两跳并受另一个实体约束的实体.虽然这项工作可以成功解析几种类型的复杂问题,但它存在覆盖范围有限的问题。一项后续研究专注于设计模板来回答时间问题
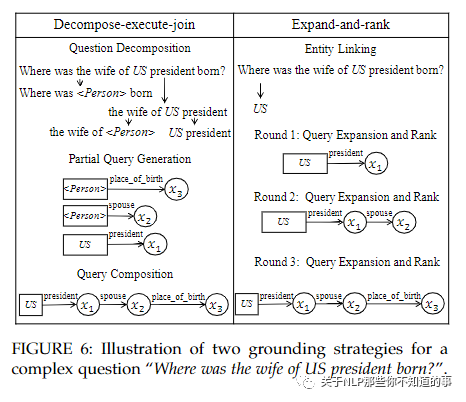
6.4 rounding with Large Search Space
动机:为了获得可执行的逻辑形式,KB 接地模块用 KB 实例化可能的逻辑形式。由于知识库中的一个实体可以链接到数百甚至数千个关系,因此考虑到计算资源和时间复杂度,无法为一个复杂问题探索和构建所有可能的逻辑形式。
方法:
decompose-execute-join:首先将一个复杂的问题分解为多个简单的问题,其中每个简单的问题都被解析成简单的逻辑形式。最终答案是通过部分逻辑形式的合取或组合获得的;
expand-and-rank: 通过以迭代方式扩展逻辑形式来减少搜索空间,作为候选逻辑在第一次迭代时形成,收集了主题实体的 1 跳邻域的所有查询图。根据问题和逻辑形式之间的语义相似性对这些候选进行排名。保留排名靠前的候选者进行进一步扩展,而过滤掉排名靠后的候选者。在接下来的迭代中,对beam中排名靠前的每个查询图进行扩展,从而产生一组新的更复杂的候选查询图。这个过程将重复,直到获得最佳查询图。
6.5 Training under Weak Supervision Signals
动机:为了应对训练数据有限或不足的问题,基于强化学习 (RL) 的优化已被用于最大化预期奖励。在这种情况下,基于 SP 的方法只能在完整解析的逻辑形式执行后才能收到反馈,这导致了严重的稀疏正奖励和虚假推理问题。
解决方法:采用了奖励塑造策略来进行解析评估。
七、方法总结
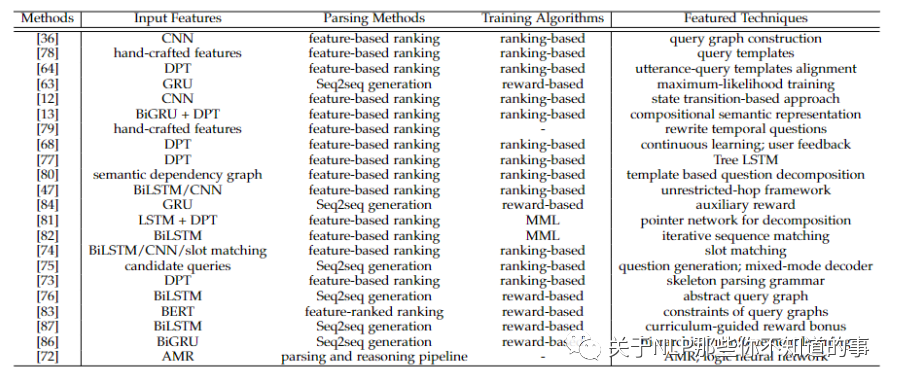
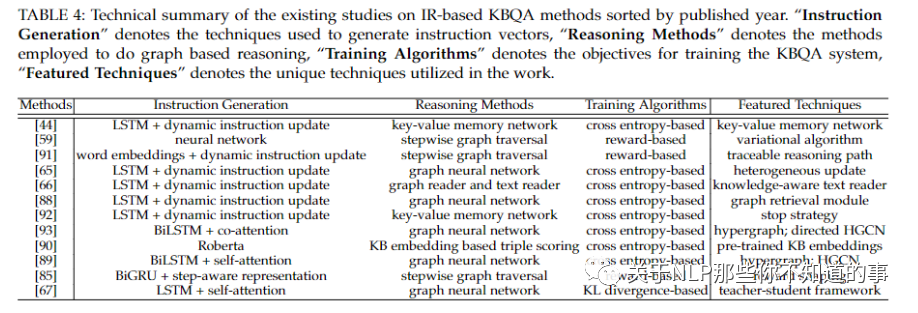
八、未来研究热点
8.1 不断进化的知识图谱问答系统
动机:下线数据 和 线上数据 的不对齐性。
解决方法:
采用继续学习 (continuous learning) 方法。当 KBQA 遇到无法处理问题时, 先将其和系统中已有的训练问题进行相似度计算,获取最相似问题的解析式,让用户从中选出有效的解析式加入到训练数据中。对于用户提出没见过的问题或者包含歧义的问题时,系统推送一些候选的问题供用户选择。
8.2 鲁棒的知识图谱问答系统
动机:现有标注数据不足
解决方法:
利用元学习 训练 KBQA;
利用无监督的双语词典归纳技术对低资源 (low-resource) 数据进行数据增强
8.3 更加一般定义的知识图谱
动机:除了显性地在任务中构建知识图谱,有部分工作将其他任务看作隐性的知识图谱。
解决方法:
将Bert等预训练语言模型作为辅助知识库,来提升KBQA 识别和推理性能。
8.4 对话型知识图谱问答
动机:对话型的知识图谱问答中引入知识图谱知识,来提升对话准确率。
参考
A Survey on Complex Knowledge Base Question Answering:Methods, Challenges and Solutions
複雜知識庫問答:方法、挑戰與解決方案綜述
可能是目前最全面的知识库复杂问答综述解读
[读综述] 关于知识图谱问答的神经网络方法的介绍
KBQA知识库问答论文分享