
【Python私活案例】100元,PDF爬虫+解析+解析数据+存储Excel文件
使用Python提取pdf信息的那些事
我一直都是一个pdf电子书和pdf格式控的宅男,没想到这辈子居然和老朋友以这种方式见面了。还记得上次专注的看pdf文件实在《明朝那些事》,于是有了今天的Python版的提取pdf信息的那些事。
1.需求
这次是要提取两个合同pdf文件中的相关信息,具体要求是先要读取excel文件,并将其中的两种类型的pdf合同连接读取出来,进行逐一的下载,这就是提取pdf文件的链接excel:
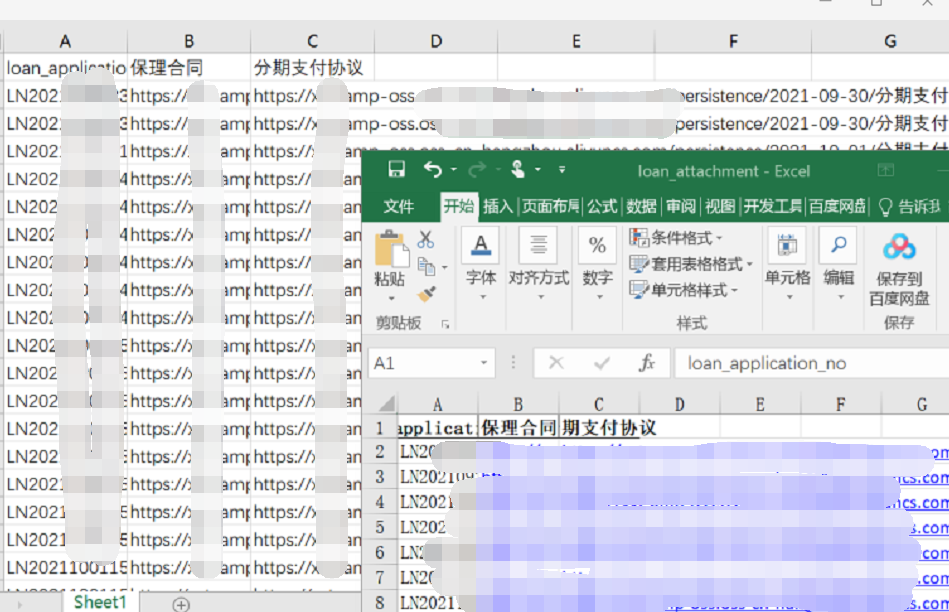
2.代码
我使用了requests库来进行了简单的pdf文件提取,因为他的链接不做验证,直接提取,连header都省了,这个还挺好的。
# 保存pdf文件
os.makedirs('./baoli/',exist_ok=True)
os.makedirs('./fenqi/',exist_ok=True)
for i in df.index:
baoli_url = df.loc[i,'保理合同']#.split('pdf?')[0].__add__('pdf')
fenqi_url = df.loc[i,'分期支付协议']#.split('pdf?')[0].__add__('pdf')
baoli_name = df.loc[i,'保理合同'].split('.pdf?')[0].replace('/','-').split('-')[-1].__add__('.pdf')
fenqi_name = df.loc[i,'分期支付协议'].split('.pdf?')[0].replace('/','-').split('-')[-1].__add__('.pdf')
loan_application_no = df.loc[i,'loan_application_no']
baoli_name = str(loan_application_no)+'_'+baoli_name
fenqi_name = str(loan_application_no)+'_'+fenqi_name
print(baoli_url)
print(fenqi_url)
res1 = requests.get(baoli_url)
res2 = requests.get(fenqi_url)
with open('./baoli/'+baoli_name,'wb') as file:
file.write(res1.content)
with open('./fenqi/'+fenqi_name,'wb') as file:
file.write(res2.content)
这里我把下载好的文档自动归类为两类合同的不同文件夹中,方便他们查找,然后我是用的他们的一个业务字段命名的文件名,这样居然在后续的使用中,成为了唯一能够传递这个字段的方法!!
然后就是对第一类合同信息的提取,这里我把关键字段做了脱敏处理,这年头干啥都要小心小心再小心,不然罗翔老师的视频不是白看了!?
这里我主要用了PyPDF2这个类库提取pdf信息,将里面我要提取的对应字段拿到,然后把他们存储到一个临时列表,这样的操作应用到所有的同类pdf文件,然后将这种临时列表全部存储到一个最终的结果列表中,这个结果列表事先已经存储好了要生成的dataframe的项字段列,因此最后可以直接通过dataframe的构造方法,生成datarame对象,进而直接写入excel
from PyPDF2 import PdfFileReader
from pathlib import Path
baoli_path = Path('./baoli/')
baoli_list = baoli_path.glob('*.pdf')
baoli = [['XXXXX','ZZZZZ','YYYYY','TTTTT','YYYYY']]
for i in baoli_list:
path = f'./baoli/{i.name}'
baoli_reader = PdfFileReader(path)
baoli_fields = baoli_reader.getFields()
temp = [i.stem.split('_')[0]]
for field in baoli_fields:
if field == 'contractNo':
contract_no = list(baoli_fields[field].values())[-1]
temp.append(contract_no)
# print(contract_no)
elif field == 'signDate':
sign_date = list(baoli_fields[field].values())[-1]
temp.append(sign_date)
# print(sign_date)
elif field == 'signContractNo':
sign_contract_no = list(baoli_fields[field].values())[-1]
temp.append(sign_contract_no)
# print(sign_contract_no)
temp.append('《分期支付协议》')
baoli.append(temp)
print(baoli)
紧接着就是第二段代码,逻辑和上面的一模一样,但是工作量却远远超出了第一个,主要是在pdf文件中要逐个去匹配对应的字段名,这里的字段多达10几个
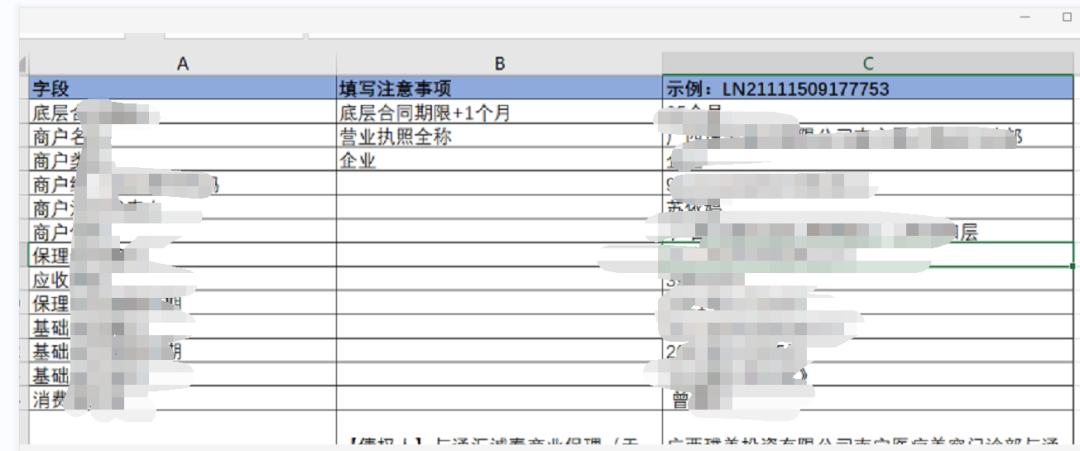
同时,我需要一一验证这些字段对应的pdf的英文代码是什么,从而确认提取的信息是否准确,然后才能正确的取数:
# 提取分期协议信息
fenqi_path = Path('./fenqi/')
fenqi_list = fenqi_path.glob('*.pdf')
fenqi = [['基础合同编号','商户住所',
'商户统一社会信用代码','商户法定代表人',
'底层合同期限','应收账款','商户名称','消费者姓名',
'服务费用',
'基础合同签署日期']]
for j in fenqi_list:
path = f'./fenqi/{j.name}'
fenqi_reader = PdfFileReader(path)
fenqi_fields = fenqi_reader.getFields()
temp = []
date = []
for field in fenqi_fields:
if field == 'contractNo':
f_contract_no = list(fenqi_fields[field].values())[-1]
temp.append(f_contract_no)
# print(f_contract_no)
elif field == 'merchantCreditCode':
f_merchant_credit_code = list(fenqi_fields[field].values())[-1]
temp.append(f_merchant_credit_code)
# print(f_merchant_credit_code)
elif field == 'merchantAddress':
f_merchant_address = list(fenqi_fields[field].values())[-1]
temp.append(f_merchant_address)
# print(f_merchant_address)
elif field == 'legalPerson':
legalPerson = list(fenqi_fields[field].values())[-1]
temp.append(legalPerson)
# print(legalPerson)
elif field == 'merchantName':
merchantName = list(fenqi_fields[field].values())[-1]
temp.append(merchantName)
# print(merchantName)
elif field == 'userName':
userName = list(fenqi_fields[field].values())[-1]
temp.append(userName)
# print(userName)
elif field == 'money':
money = list(fenqi_fields[field].values())[-1]
temp.append(money)
# print(money)
elif field == 'periods':
periods = int(list(fenqi_fields[field].values())[-1])+1
temp.append(periods)
# print(periods)
elif field == 'serviceMoeny':
serviceMoeny = list(fenqi_fields[field].values())[-1]
temp.append(serviceMoeny)
# print(serviceMoeny)
elif field == 'yyyy':
year = list(fenqi_fields[field].values())[-1]
if year:
date.append(year)
else:
date.append('年为空')
# print(year)
elif field == 'mm':
month = list(fenqi_fields[field].values())[-1]
if month:
date.append(month)
else:
date.append("月为空")
# print(month)
elif field == 'dd':
day = list(fenqi_fields[field].values())[-1]
if day:
date.append(day)
else:
date.append("天为空")
date = date[0]+'年'+date[1]+'月'+date[2]+'日'
temp.append(date)
fenqi.append(temp)
print(fenqi)
接下来在做了些生成excel文件的格式整理:
#调整格式
import xlwings as xw
app = xw.App(visible=False,add_book=False)
workbook = app.books.open(r'final.xlsx')
worksheet = workbook.sheets['总表']
worksheet.autofit()
workbook.save()
workbook.close()
app.quit()
于是,花了几个小时时间终于完成了所有的工作,但是第二天,诡异的事情发生了,在pdf匹配字段中,这些字段在代码里面都算局部变量,但是只有两个变量报错, 说这个变量不存在,而它们的作用域和其他的变量是一摸一样的,我感觉好奇怪,最后我不得已,将代码里的临时列表temp,提升为内层for循环的全局变量,然后错误就消失了,此外,我还添加了年月日的空值判断,因为她说她的数据集中的日期会有读取不正常的情况,所以我就做了这个样的判断,帮她把所有的问题都搞定了,看到她开心的状态,我觉得我也很有成就感,希望大家一切都顺利!
最后,推荐蚂蚁老师的Pandas入门课程,极佳的实战课
扫码:Pandas入门到实战课

点击阅读原文,也能到达目的地