
就是快!BetterTransformer:实现Transformer的快速推理
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
Transformers 在 NLP 方面实现了最先进的性能,并且在无数其他任务中变得流行。它们的计算成本很高,这一直是它们广泛生产的障碍。从 PyTorch 1.12 开始,BetterTransformer 为 Transformer Encoder Inference 实现了一个向后兼容的 torch.nn.TransformerEncoder 快速路径,并且不需要模型作者修改他们的模型。对于许多常见的执行场景,BetterTransformer 的改进速度和吞吐量可以超过 2 倍。要使用 BetterTransformer,请安装 PyTorch 1.12 并立即开始使用带有 PyTorch API 的高质量、高性能 Transformer 模型。

在这篇博文中,我们分享了以下主题——性能改进、向后兼容性和利用 FastPath。在下面了解有关这些主题的更多信息。
性能改进
BetterTransformer 在 CPU 和 GPU 上使用MultiHeadAttention 和 TransformerEncoderLayer的加速原生实现来启动。这些快速路径集成在标准 PyTorch Transformer API 中,并将加速 TransformerEncoder、TransformerEncoderLayer 和 MultiHeadAttention这些nn模块。这些新模块实现了两种类型的优化:(1) 融合内核结合了通常用于实现 Transformer 的多个单独的运算符以提供更有效的实现,以及 (2) 利用输入中的稀疏性来避免对填充令牌执行不必要的操作。在用于自然语言处理的许多 Transformer 模型中,填充标记通常占输入批次的很大一部分。
向后兼容
有利的是,无需更改模型即可从 BetterTransformer 提供的性能提升中受益。为了从快速路径执行中受益,输入和操作条件必须满足一些访问条件(见下文)。虽然 Transformer API 的内部实现发生了变化,但 PyTorch 1.12 保持与先前版本中的 Transformer 模块的严格兼容性,使 PyTorch 用户能够使用使用先前 PyTorch 版本创建和训练的模型,同时受益于 BetterTransformer 的改进。
除了启用 PyTorch nn.Modules 之外,BetterTransformer 还为 PyTorch 库提供了改进。性能优势将通过两种不同的启用路径获得:
透明加速:PyTorch nn.Modules 的当前用户(例如 MultiHeadAttention 以及更高级别的 Transformer 组件)将自动受益于新 nn.Modules 改进的性能。torchvision 库中使用的视觉转换器 (ViT) 实现就是一个例子(代码链接:https://github.com/pytorch/vision/blob/main/torchvision/models/vision_transformer.py#L103)。
Torchtext 库加速:作为该项目的一部分,我们优化了 Torchtext 以构建在 PyTorch 核心 API 上,以从 BetterTransformer 增强功能中受益,同时保持与以前的库版本和使用以前的 Torchtext 版本训练的模型的严格和透明的兼容性。在 Torchtext 中使用 PyTorch Transformer 还可以确保 Torchtext 将从 PyTorch Transformer 实现的预期未来增强中受益。
利用快速路径
BetterTransformer 是 PyTorch Transformer API 的快速路径。快速路径是适用于常见 Transformer 用例的 CPU 和 GPU 关键 Transformer 功能的本机专用实现。
要利用输入稀疏性(即填充)来加速模型(参见图 2),请在实例化 TransformerEncoder 时设置关键字参数 enable_nested_tensor=True 并在推理期间传入 src_key_padding_mask 参数(表示填充标记)。这要求填充掩码是连续的,这是典型的情况。
目前,BetterTransformer 加速仅适用于推理中使用的变压器编码器模型。要从快速路径执行中受益,模型必须由以下任何组件组成:TransformerEncoder、TransformerEncoderLayer 或 MultiheadAttention (MHA)。快速路径执行也受制于一些标准。最重要的是,模型必须在推理模式下执行,并在不收集梯度磁带信息的输入张量上运行(例如,使用 torch.no_grad 运行)。可以分别在 nn.MultiHeadAttention 和 nn.TransformerEncoder 的这些链接中找到完整的条件列表。如果不满足标准,控制将流向具有相同 API 但缺乏快速路径性能提升的旧版 PyTorch 1.11 Transformer 实现。
使用 PyTorch MultiheadAttention 模块的其他转换器模型(例如解码器模型)将受益于 BetterTransformer 快速路径。计划的未来工作是将端到端 BetterTransformer 快速路径扩展到基于 TransformerDecoder 的模型,以支持流行的 seq2seq 和仅解码器(例如 OPT)模型架构,并用于训练。
加速效果
下图显示了具有小规模和大规模输入的基于 BERT 的模型所取得的性能:
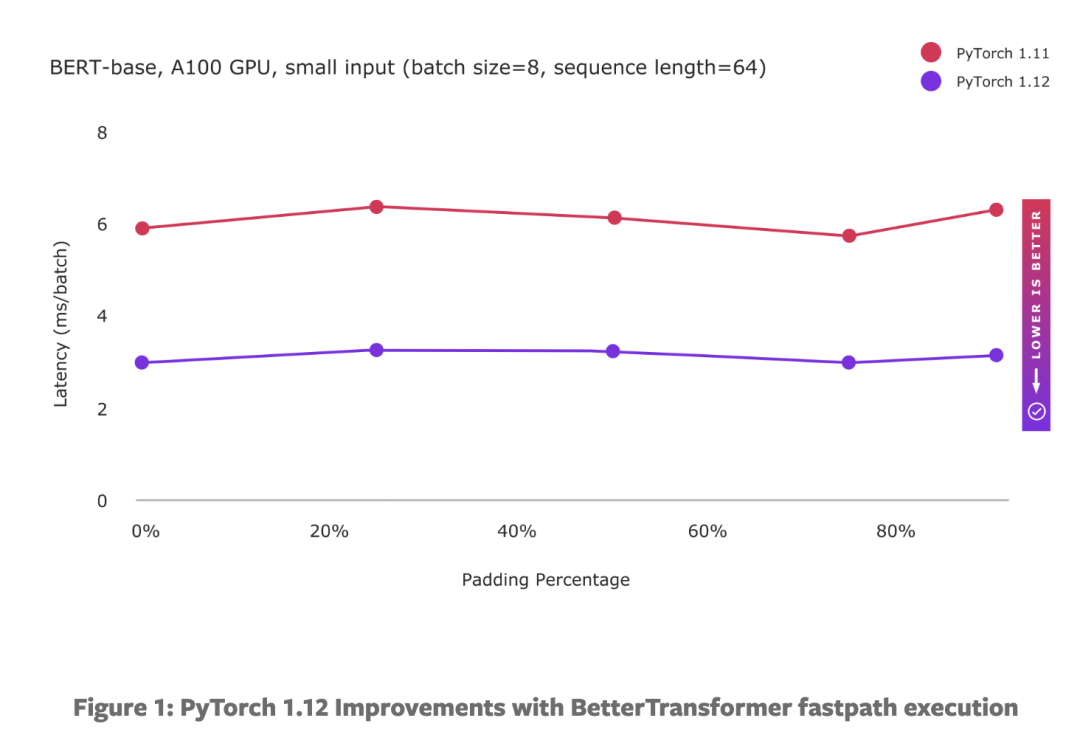
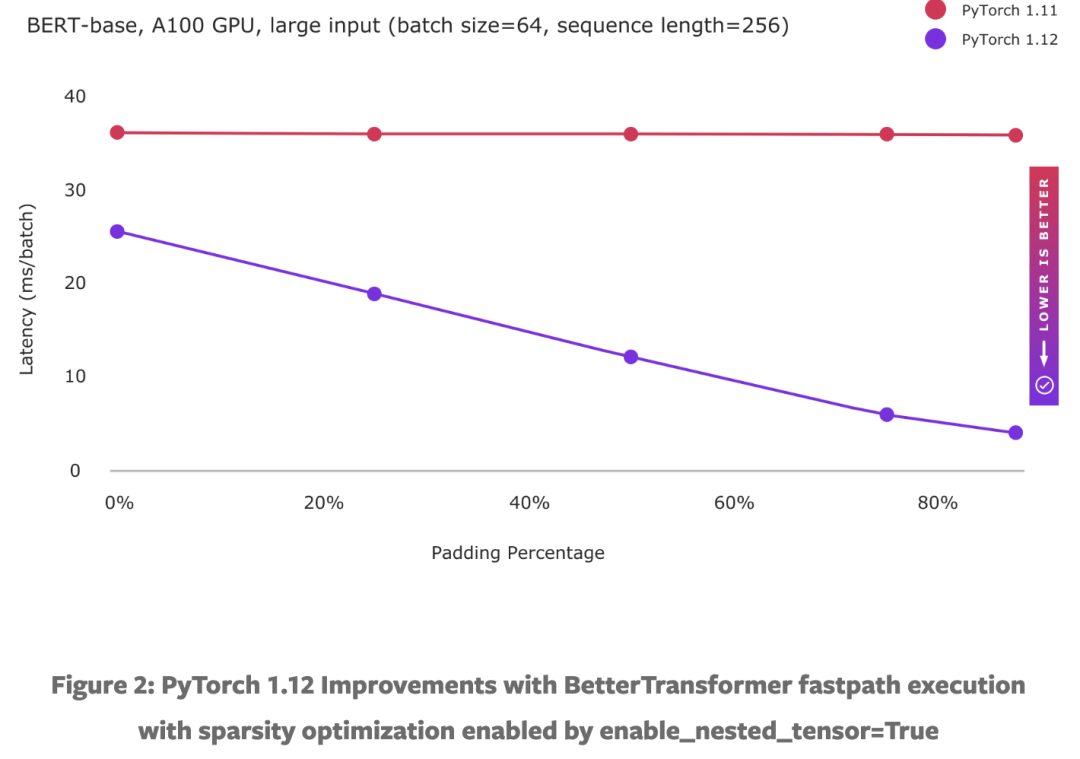
BetterTransformer 包括两种类型的优化:(1) 融合内核在单个内核中更有效地实现多个操作,以及 (2) 通过避免对填充令牌进行不必要的处理来利用稀疏性。小输入大小的增强性能主要受益于融合内核实现,并且无论填充量如何都显示出持续的性能改进。虽然大输入仍然受益于融合内核,但计算繁重的处理限制了融合内核可能获得的好处,因为基线性能已经接近理论峰值。然而,随着我们增加填充量,性能会显着提高,因为可以通过利用 NLP 工作负载中填充引入的稀疏性来避免越来越多的计算量。
未来规划
作为我们正在进行的 PyTorch BetterTransformer 工作的一部分,我们正在努力将 BetterTransformer 改进扩展到 Transformer 解码器。我们的目标是从推理扩展到训练。
我们正在合作在 FairSeq、MetaSeq 和 HuggingFace 等其他库上启用 BetterTransformer,以使所有基于 Transformer 的 PyTorch 模型受益。作为本博客系列的一部分,我们将在更大的 PyTorch 生态系统中提供有关 BetterTransformer 加速进展的未来更新。
本文翻译自:https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
