
ScreeC# 纯净 ORM 框架
目录
一、Scree是为了解决什么问题?
二、Scree为了取代数据访问层是如何思考的?做了哪些事情?
三、现在开始使用scree
四、Scree的高阶能力
五、分布式环境下的scree
六、常见问题集锦
前言
2008年初,来上海不久的我,有幸加入了一家在沪上的.net领域还算有一定名气的公司。第一次接触到ORM,那是技术老大自行研发的。其实,它并不仅仅是ORM,而是基于ORM的一整套框架体系。当时的我就被震撼到了,对一套框架来说,核心并不在于代码,而在于它曾经面临什么样的问题,在于它解决问题的思维方式。随着研究和使用的深入,越发觉得它的思想在当时很超前的(这里就不多提了),同时,也发现了它的一些不足和过度设计的问题。于是,我萌生了写一套自己框架的想法。说干就干,这一干,从08年开始断断续续就好几年。迭代了很多版本,逐步完善了很多功能,也删了更多的功能。其后,项目经过几年在磁盘中的封印,又经过几年在实际生产中的应用,又经过N年文档懒癌的治疗,终于下定决心开源出来。我喜欢写代码,特别喜欢逻辑思考的过程,但一点也不喜欢写项目文档,何况还是教别人怎么使用这一堆代码的文档。
项目名scree(小石子)来源于大学期间,远在04年的故事,暂不多提了,说了太多废话,开始进入正题。再家里奶奶般的重复一遍,问题与解决问题的思想才是最重要的。
一、Scree是为了解决什么问题?
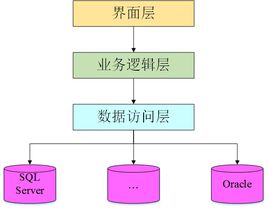
要回答这个问题,不得不提非ORM的开发模式,同时也不得不提三层架构。
{kind=link}
三层与N层这里不展开,需要提及的是三层中的数据访问层不一定就是一层,也可以是两层、三层甚至N层。在非ORM开发模式下,通过在业务逻辑层编写SQL语句(很多时候也以视图或存储过程的形态存在),然后调用数据访问层而达到读写数据的目的。而基于ORM底层框架(这里需要加上底层这个定义,随着技术的发展、系统规模的膨胀三层框架任何一层在横向和纵向都有了大规模的层级扩展),主旨就是为了替换掉数据访问层同时变业务逻辑层的SQL操作方式为对象化操作方式,这也是scree的初衷。
对象化操作的好处就不用多说了,谁用谁知道。ORM的出现,将面向对象语言的系统构建过程全面的对象化了,不再留有SQL时代的缺憾。数据终于全部变成了一个个、一组组的对象,一线开发人员的精气神可以更专注于业务逻辑,更有效率的团队协作、更快速的数据迁移、更灵活的系统扩展成为可能。
二、Scree为了取代数据访问层是如何思考的?做了哪些事情?
1、自动生成表
既然祭出了ORM的旗帜,那么class与表、object与数据行的对应关系维护就是基本需求。先看如下一段代码:
public enum NewsType
{
Military = 0,
World = 1,
Society = 2,
Culture = 3,
Travel = 4,
}
public class News : SRO
{
[StringDataType(IsNullable = false, Length = 50)]
public string Title { get; set; }
[StringDataType(IsMaxLength = true)]
public string Context { get; set; }
public string Author { get; set; }
public NewsType Type { get; set; }
public int ReadingQuantity { get; set; }
static News()
{
TimeStampService.RegisterIdFormat<News>("xw{0:yyMMdd}{1}");
}
}
Scree会自动将继承自SRO的类生成为数据库中同名的表(不支持配置不同的表名,这不是一个技术问题,应该来说最初是有这个设计的,在再三考虑下,取消这个支持。少就是多,在至简的名义追求最大的可用才是最美的。对于很多不支持的功能,不是不能支持,而是经过慎重考虑不予支持,下同,不在赘述)。
仅支持SQL Server,如果确实有其他数据库的需求,请自行修改Scree.DataBase.SQLServer。
支持数据类型为int、bool、string、DateTime、枚举、decimal、long、byte[],分别对应数据库中的int、bit、nvarchar或text、datetime、int、decimal、bigint、image。
可用通过对属性设置Attribute来指定字段类型详细信息,详见Scree.Attributes。
string默认为nvarchar(32),decimal默认为decimal(18,4)。
系统只会自动为新class创建对应的表,如果是字段有修改,则需要人工修改数据库。
SRO基类中提供了5个默认属性Id、CreatedDate、LastAlterDate、Version、IsDeleted,也就是所有scree的数据对象都会自带这5个字段,用途后面还会详解。
2、增删改查
对数据的基本操作,莫过于增删改查,下面演示如何通过操作对象方便的读写对应的数据。
增加
//如果直接new也是可以的,目前是等效的,建议统一使用CreateObject,未来可以利用CreateObject搞一些事情
//News news = new News();
News news = PersisterService.CreateObject<News>();
news.Title = "新闻标题";
news.Context = "新闻内容";
PersisterService.SaveObject(news);
查询
News obj = PersisterService.LoadObject<News>("新闻Id"); 修改
News obj = PersisterService.LoadObject<News>("新闻Id", LoadType.DataBaseDirect);
news.Title = "新的标题";
news.Context = "新的内容";
PersisterService.SaveObject(news); 删除,仅支持逻辑删除,不会做物理删除,可以理解为删除本身也就是一种修改。逻辑删除的数据,通过框架查询时会自动屏蔽掉。
News obj = PersisterService.LoadObject<News>("新闻Id", LoadType.DataBaseDirect);
news.IsDeleted = true;
PersisterService.SaveObject(news); 本质上,增删改查只有两个动作:读和写。在scree中,单个对象读使用LoadObject,写使用SaveObject。在实际业务处理中,如果Load的对象是要用于修改后Save的,LoadObject的参数应该使用LoadType.DataBaseDirect(不从缓存加载的模式)。
3、读取一组对象
使用LoadObjects,可精确查找、可模糊查找、可排序。
internal static News[] GetNewsByType(NewsType type, LoadType loadType)
{
List<IMyDbParameter> prams = new List<IMyDbParameter>();
prams.Add(DbParameterProxy.Create("Type", SqlDbType.Int, (int)type));
News[] objs = PersisterService.LoadObjects<News>("[Type]=@Type", prams.ToArray(), loadType);
return objs;
}
internal static News[] GetNewsByAuthor(string author, LoadType loadType)
{
List<IMyDbParameter> prams = new List<IMyDbParameter>();
prams.Add(DbParameterProxy.Create("Author", SqlDbType.NVarChar, "%" + author + "%"));
News[] objs = PersisterService.LoadObjects<News>("[Author] like @Author order by ReadingQuantity desc",
prams.ToArray(), loadType);
return objs;
}
4、保存一组对象
默认为事务性保存。
News news = PersisterService.CreateObject<News>();
news.Title = "新闻标题";
news.Context = "新闻内容";
string remark = "增加新闻";
SystemLog systemLog = LogService.CreateSystemLog(SystemLogType.AddNews, typeof(News), news.Id, remark);
PersisterService.SaveObject(new SRO[] { news, systemLog });
5、自定义对象Id
新创建的对象,默认Id是Guid。
private string _id = Guid.NewGuid().ToString().Replace("-", ""); 也可以自定义具有业务意义的Id(建议Id全局唯一。注意,是全局唯一,而不是单类型唯一)。Scree提供时间戳服务,可以确保Id全局唯一。
自定义Id需要两步,首先注册Id的格式(这种注册格式大家应该很熟悉,就是格式化字符串的写法),引用时间戳服务提供的变量。
public class News : SRO
{
static News()
{
TimeStampService.RegisterIdFormat<News>("xw{0:yyMMdd}{1}");
}
}
然后,给新创建的对象Id赋值(注意:Id是只读属性,只能使用SetId方法对新创建的对象赋值一次)。
News news = PersisterService.CreateObject<News>();
news.SetId(TimeStampService.GetOneId<News>());
RegisterIdFormat以及GetOneId高级使用可以详见代码注释。
6、对象与数据的映射原理
先说读,前面提到读使用LoadObject
在框架内部,通过条件自动拼接出select的sql语句,从DB拉取到数据后对对象属性进行反射,逐一赋值。
再说写,写统一使用SaveObject
Scree通过SRO基类的IsNew属性维护对象的新老状态。新创建的对象IsNew=true,而通过LoadObject拉取到的对象IsNew=false,框架通过判断IsNew,分别拼接出insert或update的sql。如果是一组对象同时save,则是循环前述过程。
7、对象版本
Scree通过SRO基类的Version属性提供对象版本维护的能力。这项能力非常重要,建议无论是否使用ORM,无论使用什么样的框架与开发模式,都应该对对象(或者说行数据)增加版本号。
每一个新创建的对象其Version默认为0(第一次insert进入数据库中,Version维持为0)
对象每一次update操作后,其Version自动+1
对象update sql会自动加上当前Version的where条件,以保证不会出现数据污染
8、CreatedDate与LastAlterDate
CreatedDate是对象第一次创建的时间,永不再变化。LastAlterDate是对象最后一次被修改的时间,每一次update都会改变。
9、充血模型与贫血模型
推荐使用贫血模型。这方面的争论太多了,个人认为理论和工程是两码事,让理论的归理论,工程的归工程吧。简单、层次结构清楚、工程师易于理解和使用在工程实际中太重要了。
三、现在开始使用scree
启动scree框架,只需要一行代码,在Global.asax中
protected void Application_Start(object sender, EventArgs e)
{
ServiceRoot.Init();
}
在Test文件夹中,提供了两个示例项目:
SimpleExample,简单示例,一般小型应用(单服务器或少量服务器或单表数据量在百万内),使用基本用法即可满足需求了
AdvancedExample,高级示例
启动scree框架之前,需要有两个步骤,下面以SimpleExample为例。
1、引用程序集
Scree.Attributes
Scree.Cache
Scree.Common
Scree.Core.IoC
Scree.DataBase
Scree.Lock
Scree.Log
Scree.Persister
Scree.Syn
2、添加配置文件
在应用程序的根目录新建名为config的文件夹,并添加文件
log4net.config
mapping.config
root.config
storage.config
配置文件的内容可以详见示例项目。
示例项目中dbbak文件夹中是对应的数据库备份,初次观摩scree框架,建议直接使用备份数据库,以利于快速上手。
四、Scree的高阶能力
1、视图支持
虽然,我一般不建议使用视图,但某些情境下,视图确实还有积极的意义。在这里,可以通过一个窍门的方式来读取视图的数据,把视图当成一张表即可。前面说到,Scree会自动将继承自SRO的类映射成DB中同名的表。例如对于视图vwNewsForUser,可以定义类型:
public class vwNewsForUser : SRO
{
}
读取视图的数据同样可以使用到LoadObject或LoadObjects,也就是说在读上面等同于数据对象。
vwNewsForUser obj = PersisterService.LoadObject<vwNewsForUser>("视图数据Id"); 显然,视图中必须存在SRO基类默认的5个字段。不过,这并不是问题,视图总归是从数据对象表之间关联而来,必然会有一张表是关联关系中的核心表,视图5个字段就使用该对象的即可。
2、缓存
框架为对象或对象数组提供本地缓存功能,只需要配置即可。
第一步,root.config中需要配置启用缓存服务,如下:
<Service type="Scree.Cache.ICacheService, Scree.Cache" driver="Scree.Cache.CacheService, Scree.Cache"/>
第二步,在cache.config中配置指定类型的缓存参数,单个对象或一组对象都可以,示例如下:
<Type name="MyApp.Models.User" second="40" isfix="true" size="300"/>
<Type name="Scree.Cache.ArrayCache`1[[MyApp.Models.User, MyApp.Models, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null]]"
second="60" size="300" />
LoadObject或LoadObjects均有LoadType的参数,默认优先读取缓存数据。框架未提供分布式缓存注入功能,如果需要使用MC或Redis等,需自行修改Scree.Cache.CacheService。
3、BeforeSave和AfterSave
对于单个对象,在持久化之前和之后均可以搞一些事情。
public class SystemLog : SRO
{
protected override void BeforeSave()
{
//可以在这里搞一些事情
}
protected override void AfterSave()
{
//可以在这里搞一些事情
}
}
在调用PersisterService.SaveObject持久化单个(或一组对象)的之前和之后也可以搞一些事情。PersisterService提供了注入接口。
public delegate void BeforeSave(SRO[] objs);
public delegate void AfterSave(SRO[] objs);
void RegisterBeforeSaveMothed(BeforeSave beforeSave);
void RegisterAfterSaveMothed(AfterSave afterSave);
4、分库
storage.config用于配置每一个数据库的连接信息,例如:
<StorageContext name="current">
<DataSource>127.0.0.1</DataSource>
<Catalog>AdvancedExample</Catalog>
<UId>dbname</UId>
<Pwd>dbpassword</Pwd>
<Enabled>true</Enabled>
<Timeout>60</Timeout>
<MinPoolSize>1</MinPoolSize>
<MaxPoolSize>100</MaxPoolSize>
</StorageContext>
<StorageContext name="userdb">
<DataSource>127.0.0.1</DataSource>
<Catalog>AdvancedExample-User</Catalog>
<UId>dbname</UId>
<Pwd>dbpassword</Pwd>
<Enabled>true</Enabled>
<Timeout>60</Timeout>
<MinPoolSize>1</MinPoolSize>
<MaxPoolSize>100</MaxPoolSize>
</StorageContext>
mapping.config用于配置指定对象会对应到哪一个数据库,例如:
<Type name="MyApp.Models.User" default="current">
<StorageContext name="UserSubById" >userdb</StorageContext>
<StorageContext name="UserSubByHour" >userdb</StorageContext>
</Type>
上述配置表示对象User的默认库(default)是storage.config中名为current的数据库;其存储别名(alias)为UserSubById或UserSubByHour对应的库是storage.config中名为userdb的数据库。
备注:mapping.config未指定的类型其默认库是storage.config中名为current的数据库,尚若没有名为current的配置,则默认库就是storage.config中的第一个数据库。
5、分表
随着单表数据量增大,分表是通常的解法。前面说过BeforeSave可以搞一些事情,下面就是一个例子。
public class User : SRO
{
protected override void BeforeSave()
{
this.RegisterStorageBehavior(null);
this.RegisterStorageBehavior("UserSubById", "UserById" + Id.Substring(Id.Length - 1));
this.RegisterStorageBehavior("UserSubByHour", "UserByHour" + CreatedDate.Hour.ToString());
}
}
框架提供了便捷的存储行为注册接口。
this.RegisterStorageBehavior("UserSubById", "UserById" + Id.Substring(Id.Length - 1)); RegisterStorageBehavior方法的第一个参数是存储别名(alias),对应的第4条分库中指定的数据库;第二个参数是在该库中分表后的表名。上述例子是通过Id最后一位做散射,从前面的Id定义可知,Id的最后一位是0-9的数字,这就意味着User对象的Id散射分表有10个,从UserById0至UserById9。
this.RegisterStorageBehavior("UserSubByHour", "UserByHour" + CreatedDate.Hour.ToString()); 同理,User根据对象生成时间的小时数做散射,可以得到24个表,从UserByHour0至UserByHour23,使用alias为UserSubByHour,从分库配置上来看,同样存储在名为AdvancedExample-User的数据库中。
this.RegisterStorageBehavior(null);
alias为null且未指定表名,这样,User对象将会有一份总表数据,存储在名为AdvancedExample的数据库中。
该示例中,User对象将产生三份完全一样的数据。以上仅为示例,大家可以根据自己的业务需要定制对象存储行为。
备注:分表是不会自动生成的,需要人工创建。
6、SRO对象更多技能
CurrentAlias
因为对象存在分库,故某一个对象可能会从不同的库中读取而来,对象的CurrentAlias属性就是代表对象来源的存储别名。
CurrentTableName
同理,因为对象存在分表,CurrentTableName代表对象来源的表名。
SaveMode
public enum SROSaveMode
{
//新创建或者新Load
Init = 0,
//新创建的对象已经第一次持久化
Insert = 1,
//已有对象的再次持久化
Update = 2,
//已有对象通过SaveObject试图持久化,但是对象在业务处理过程中并没有被修改过
NoChange = 3,
}
表示对象最近一次持久化的模式,借由这个属性以及前述的AfterSave,也可以视业务的需要搞一些事情。
GetOriginalValue
对象在被Load出来后,经过业务逻辑处理,一部分属性会被修改,通过GetOriginalValue可以获得属性被修改前的原始值。其实,在框架内部也是通过对象的当前值与原始值的比对,生成update的sql语句的。前述的SROSaveMode.NoChange也是基于此。
7、自定义服务
框架提供了自定义服务的注入功能,系统启动时会自动加载。以自定义的InitService服务为例。
InitService需要继承ServiceBase,并根据需要重写Init()和Run()方法以搞一些事情。Run()会在所有服务Init()完成之后执行。
在root.config中,注入服务
<Service type="MyApp.Services.InitService, MyApp.Services" driver="MyApp.Services.InitService, MyApp.Services"/>
8、对象自动快照
快照,大家应该都不陌生,是数据的一个副本,用于数据备份与恢复。我有一个大胆的想法:让系统数据可以还原到任意时刻的状态。要想做到这一点,首先必须把期初数据以及之后所有数据变更都记录下来,逆向操作就可以还原到任一时刻数据状态。当然这只是理论上的,工程实际中,计算和存储成本还是相当巨大的,甚至是不可为的。不过从小处来说,如果能把数据变更都记录下来,对于我们排查系统问题却是实实在在的武器。以往,我们会在业务逻辑处理中以各种方式记录大量的日志,但这些日志往往都是片段性的、局部的,查问题的时候总是感觉日志信息不够,何况这些日志大多是记录操作行为而不是数据本身的。
下面简单介绍下,如何自动记录对象的快照。
PersisterService.RegisterAfterSaveMothed(SROLogging);
通过第7项注入服务,在启动时为Save后注册持久化后的行为。
前面说过,RegisterAfterSaveMothed会在对象持久化之后,也就是调用SaveObject方法之后会执行,通过这个注入点,可以获得刚持久化之后获得对象引用做一些事情。
private static void SROLogging(SRO[] objs)
{
if (objs == null)
{
return;
}
Thread t = new Thread(SROLoggingThreadMothed);
t.Start(objs);
}
private static void SROLoggingThreadMothed(object o)
{
try
{
SRO[] objs = (SRO[])o;
LogService.SROLogging(objs);
}
catch (Exception ex)
{
LogProxy.Error(ex, false);
}
}
internal static void SROLogging(SRO[] objs)
{
try
{
List<SRO> list = new List<SRO>();
SROLog log;
foreach (SRO obj in objs)
{
if (obj == null || obj.SaveMode == SROSaveMode.Init || obj.SaveMode == SROSaveMode.NoChange
|| !(obj is INeedFullLogging))
{
continue;
}
log = new SROLog();
log.ObjectId = obj.Id;
log.ObjectType = obj.GetType().FullName;
log.ObjectJson = JsonConvert.SerializeObject(obj);
log.HostName = Tools.GetHostName();
list.Add(log);
}
if (list.Count > 0)
{
PersisterService.SaveObject(list.ToArray());
}
}
catch (Exception ex)
{
LogProxy.Error(ex, false);
}
}
通过上述简单的一些处理,所有继承接口INeedFullLogging的SRO对象,任一次持久化均会自动创建数据副本,存储于SROLog的表中(当然也可以分库分表,不再赘述)。由此,对象的所有版本变更均会记录在案,对于bug排查是非常有利的。
以上只是抛砖引玉,涉及更多窍门,留待大家挖掘。
五、分布式环境下的scree
1、同步
同步主要是为本地缓存而生的。
本地缓存与数据库中的数据不免的存在差异。如果全部使用的分布式缓存且同一对象只有一份缓存副本,那么是不需要同步的。一般的,既然使用了缓存,数据差异的问题就是必然的、可预见的而且在业务处理过程中也应该有所考虑和应对的。缓存某种意义上也是一把双刃剑,从性能角度,缓存自然是越多越好,越久越好。随之而来的就是数据差异会越来越大,越来越广,以至于在业务处理中不免要分神去考虑应对策略。
以电商常见的商品库存信息为例。一般商品详情的PV会在整个系统中位列前茅,商品信息自然会做缓存,而且要尽量长。但商品的库存却一直在变化中,买家看到商品库存明明还有很多,但是一旦去下单就发现库存没了,这样体验就很不好。当然,实际中也可以单独对库存进行处理,但是价格、标题等等也同样可能会变化。自营B2C的可能还好控制一些,C2C的变化就更复杂,这就是前述的分神问题,各种对象都可能需要缓存,要考虑的就多了。
同步机制
Ⅰ、对象被修改并持久化后,会将同步数据包(包含对象类型、Id、Version)异步发送给同步服务器。
Ⅱ、应用服务器定期从同步服务器拉取同步数据包。
Ⅲ、对象Load时,如果是从缓存加载的,则需判断同步数据包,若对象被修改过且Version比当前的缓存数据Version高,则需要再次从DB拉取。
Ⅳ、框架提供了懒惰和非懒惰两种拉取数据的模式,默认为非懒惰模式,详见synclient.config配置。
框架默认只支持了单台同步服务器,虽然这是一问题,但并不至于致命。对于大部分系统来说,这已经足够满足需求,本着求简(或者说不干扰大多数人)的原则,框架本身就不再深入了。如果确实有必要拓展同步服务器的话,架构师在此基础上自行做一些扩展即可,并不是什么难事。
开始使用同步服务
Ⅰ、创建Scree.SynServerService服务(这就是同步的服务端,可以部署单独的服务器上,也可跟应用服务部署在一起),建议设为自动启动。
Ⅱ、客户端引用Scree.Syn.Client,并在config添加synclient.config。
Ⅲ、客户端的root.config中添加服务注册。
<Service type="Scree.Syn.Client.ISynClientService, Scree.Syn.Client"
driver="Scree.Syn.Client.SynClientService, Scree.Syn.Client"/>
2、分布式锁
对于分布式锁,其实我是纠结的。这是一把双刃剑,特别担心被滥用,而往往担心什么,什么就一定会发生。
public static ILockService LockService
{
get
{
return ServiceRoot.GetService<ILockService>();
}
}
ILockItem[] items = new ILockItem[] {
LockService.CreateLockItem<User>("UserId_1"),
LockService.CreateLockItem<User>("UserId_2"),
LockService.CreateLockItem<SystemLog>("LogId_1")
};
string lockId;
bool isLockGetted = LockService.GetLock(items, out lockId);
if (isLockGetted)
{
try
{
//业务逻辑
}
finally
{
LockService.ReleaseLock(lockId);
}
}
从LockService.GetLock的参数可知,这是一个数组,也就是说你可以同时锁定多个对象。同一段业务逻辑涉及多个核心对象变更,就需要同时锁一组对象。
前面说了,框架的持久化默认是事务性的且对象本身有Version控制,正常是不会出现脏写的。但在并发比较大的情况下,把所有数据版本控制压力转移给DB,不仅显的太晚(到真正持久化时才发现数据是脏的,虽然保证了数据安全,但已经影响到了业务操作的顺利进行),另外对DB来说也是负担,可以考虑通过分布式锁在业务层面控制。
分布式锁使用场景就不举例了,示例项目中也没有,你真正需要的时候自然会想到,不需要的时候不知道也好。
开始使用分布式锁服务
Ⅰ、创建Scree.LockServerService服务(这就是锁的服务端,可以部署单独的服务器上,也可跟应用服务部署在一起),建议设为自动启动。
Ⅱ、客户端引用Scree.Lock.Client,并在config添加lockclient.config。
Ⅲ、客户端的root.config中添加服务注册。
<Service type="Scree.Lock.ILockService, Scree.Lock" driver="Scree.Lock.Client.LockService, Scree.Lock.Client"/>
六、常见问题集锦
1、为什么没有自动创建表
确保storage.config中数据配置是正确的。
检查mapping.config中autocreatetable属性值是否为true。
检查TableCreated.config是否已经存在该类型,此文件内容会自动生成,用于记录数据库中对应表是否已经存在。如果想重新生成表,请删除表的同时删除对应的配置项,然后重启应用即可。
检查对应类的程序集名称是否已经配置在mapping.config中的Assembly节点。
如果存在分库的,检查表是否生成到了其他库,如果是,检查表的mapping配置。
分表是不会自动创建的。