
LAC中文词法分析解决方案
中文词法分析(LAC)
中文分词(Word Segmentation)是将连续的自然语言文本,切分出具有语义合理性和完整性的词汇序列的过程。因为在汉语中,词是承担语义的最基本单位,切词是文本分类、情感分析、信息检索等众多自然语言处理任务的基础。 词性标注(Part-of-speech Tagging)是为自然语言文本中的每一个词汇赋予一个词性的过程,这里的词性包括名词、动词、形容词、副词等等。 命名实体识别(Named Entity Recognition,NER)又称作“专名识别”,是指识别自然语言文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。 我们将这三个任务统一成一个联合任务,称为词法分析任务,基于深度神经网络,利用海量标注语料进行训练,提供了一个端到端的解决方案。
我们把这个联合的中文词法分析解决方案命名为 LAC 。LAC 既可以认为是 Lexical Analysis of Chinese 的首字母缩写,也可以认为是 LAC Analyzes Chinese 的递归缩写。
特别注意:本项目依赖Paddle v0.14.0版本。如果您的Paddle安装版本低于此要求,请按照安装文档中的说明更新Paddle安装版本。
项目结构
.
├── AUTHORS # 贡献者列表
├── CMakeLists.txt # cmake配置文件
├── conf # 运行本例所需的模型及字典文件
├── data # 运行本例所需要的数据依赖
├── include # 头文件
├── LICENSE # 许可证信息
├── python # 训练使用的python文件
├── README.md # 本文档
├── src # 源码
├── technical-report # 技术报告
└── test # Demo程序
引用
如果您的学术工作成果中使用了LAC,请您增加下述引用。我们非常欣慰LAC能够对您的学术工作带来帮助。
@article{jiao2018LAC,
title={Chinese Lexical Analysis with Deep Bi-GRU-CRF Network},
author={Jiao, Zhenyu and Sun, Shuqi and Sun, Ke},
journal={arXiv preprint arXiv:1807.01882},
year={2018},
url={https://arxiv.org/abs/1807.01882}
}
模型
词法分析任务的输入是一个字符串(我们后面使用『句子』来指代它),而输出是句子中的词边界和词性、实体类别。序列标注是词法分析的经典建模方式。我们使用基于GRU的网络结构学习特征,将学习到的特征接入CRF解码层完成序列标注。CRF解码层本质上是将传统CRF中的线性模型换成了非线性神经网络,基于句子级别的似然概率,因而能够更好的解决标记偏置问题。模型要点如下,具体细节请参考python/train.py代码。
输入采用one-hot方式表示,每个字以一个id表示
one-hot序列通过字表,转换为实向量表示的字向量序列;
字向量序列作为双向GRU的输入,学习输入序列的特征表示,得到新的特性表示序列,我们堆叠了两层双向GRU以增加学习能力;
CRF以GRU学习到的特征为输入,以标记序列为监督信号,实现序列标注。
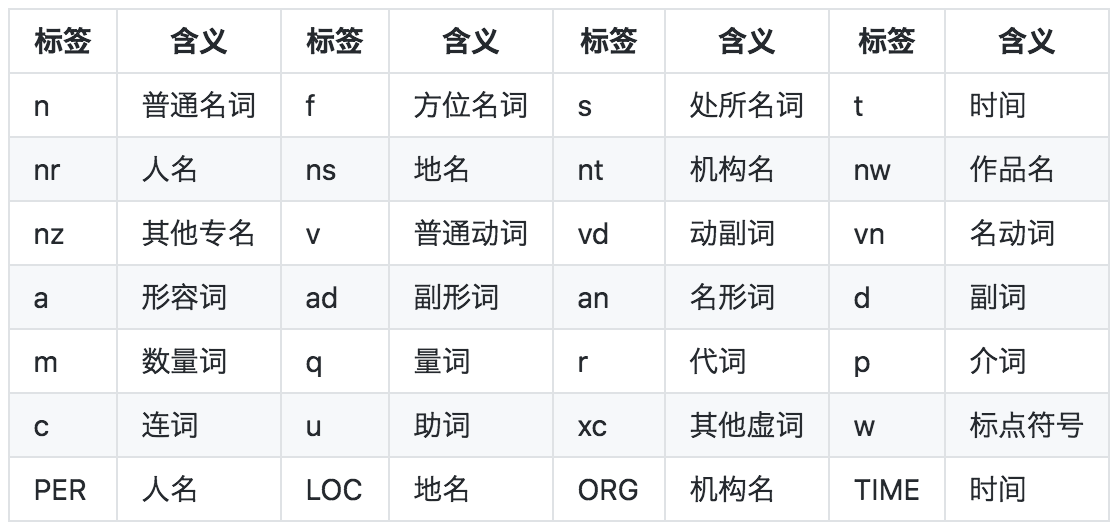
词性和专名类别标签集合如下表,其中词性标签24个(小写字母),专名类别标签4个(大写字母)。这里需要说明的是,人名、地名、机名和时间四个类别,在上表中存在两套标签(PER / LOC / ORG / TIME 和 nr / ns / nt / t),被标注为第二套标签的词,是模型判断为低置信度的人名、地名、机构名和时间词。开发者可以基于这两套标签,在四个类别的准确、召回之间做出自己的权衡。
数据
训练使用的数据可以由用户根据实际的应用场景,自己组织数据。数据由两列组成,以制表符分隔,第一列是utf8编码的中文文本,第二列是对应每个字的标注,以空格分隔。我们采用IOB2标注体系,即以X-B作为类型为X的词的开始,以X-I作为类型为X的词的持续,以O表示不关注的字(实际上,在词性、专名联合标注中,不存在O)。示例如下:
在抗日战争时期,朝鲜族人民先后有十几万人参加抗日战斗 p-B vn-B vn-I n-B n-I n-B n-I w-B nz-B nz-I nz-I n-B n-I d-B d-I v-B m-B m-I m-I n-B v-B v-I vn-B vn-I vn-B vn-I
我们随同代码一并发布了完全版的模型和相关的依赖数据。但是,由于模型的训练数据过于庞大,我们没有发布训练数据,仅在
data目录下的train_data和test_data文件中放置少数样本用以示例输入数据格式。模型依赖数据包括:
输入文本的词典,在
conf目录下,对应word.dic对输入文本中特殊字符进行转换的字典,在
conf目录下,对应q2b.dic标记标签的词典,在
conf目录下,对应tag.dic
在训练和预测阶段,我们都需要进行原始数据的预处理,具体处理工作包括:
在训练阶段,这些工作由python/train.py调用python/reader.py完成;在预测阶段,由C++代码完成。
从原始数据文件中抽取出句子和标签,构造句子序列和标签序列
将句子序列中的特殊字符进行转换
依据词典获取词对应的整数索引