
BoilerpipeHTML 正文内容提取库
Boilerpipe 是一个能从 HTML 中剔除广告和其他附加信息,提取出目标信息(如正文内容、发布时间)的 Java 库。其算法的基本思想是通过训练获得一个分类器来提取出我们需要的信息。
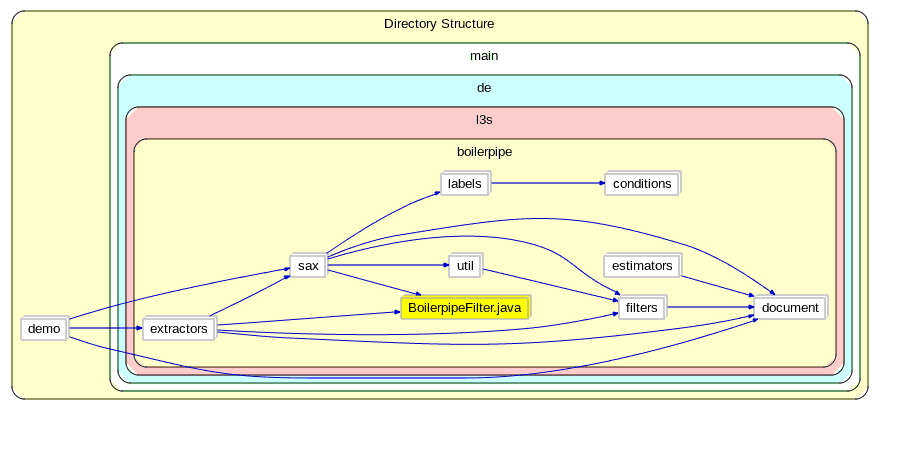
Boilerpipe 的包结构:
boilerpipe,根目录
document,文档包,定义了 boilerpipe 所处理文档数据类型,主要包括 TextDocument 和 TextBlock 。一个 TextDocument 即一个网页,由多个 TextBlock 构成。
lables,标签,每个 TextBlock 都有一个 lable 字段,表示该 TextBlock 的属性(如是不是正文)。
filters,过滤器,定义了多个过滤器,过滤器的作用即对 TextBlock 进行过滤,使用机器学习、统计、启发式方法等数据挖掘算法判断哪些 TextBlock 是所需要的(正文段),给 TextBlock 加上 lable ,去除无关的 TextBlock 。
sax,SAX 解析器,定义了从各种来源获取并解析网页的方法。
extractors,提取器,提取流程的入口。每个 extractor 都定义了自己的提取方法,通过调用不同的 filter 达到不同的处理效果。
conditions,条件判断,判断一个 TextBlock 是否满足特定的条件。
estimators,评估器,评估一个 extractor 对特定 document 的提取效果。
调用关系图示:
介绍内容摘自:CSDN
评论