
大语言模型推理的价格战,靠规模取胜?

文经授权转载宝玉老师的个人博客(微博@宝玉xp ),链 接 https://baoyu.io/translations/llm/inference-race-to-the-bottom-make
作者 | Dylan Patel ,Daniel Nishball 责编 | 夏萌出品 | baoyu.io

Mixtral 在 H100, MI300X, H200, A100 上的混合推理成本,及推测性解码
目前除了 OpenAI,还有五家公司的模型在多个基准测试中超越了 GPT-3.5,这些公司包括 Mistral Mixtral、Inflection-2、Anthropic Claude 2、Google Gemini Pro 和 X.AI Grok。更令人惊讶的是,Mistral 和 X.AI 仅靠不到 20 人的团队便取得了这样的成就。此外,我们还预计 Meta、Databricks、01.AI (Yi)、百度和字节跳动很快也会实现超过 GPT-3.5 的性能。当然,这些成绩都是在基准测试中获得的,而且据说有些公司是在评估数据上进行训练的……但不必太过纠结于这个小细节。
对于关注此事的人来说,从现在起短短几个月内,将会有总共 11 家公司加入这一行列。显而易见,GPT-3.5 级别模型的预训练已经变得非常普及。OpenAI 仍然是 GPT-4 的领头羊,但这种领先优势已大幅缩减。尽管我们认为最高端模型将占据大部分长期价值,但次一级别的模型在质量和成本上也将在市场上创造出价值数十亿美元的细分市场,尤其是经过微调之后。
那么,如果这些模型无处不在,哪些公司能从中获利呢?
那些通过完整的软件即服务或社交媒体直接接触客户,从而拥有独特分销渠道的公司将具有优势。那些为他人提供全方位训练或微调服务,帮助他们处理从数据到服务的每个阶段的公司,将具有优势。能够提供数据保护并确保所有模型使用合法的公司,也将具有优势。而那些仅仅提供开放模型服务的公司则不会有竞争优势。
一些显著的优势可以从 Microsoft 的 Azure GPT API 与 OpenAI 的对比中看出。在公共和私有实例的推理量方面,Microsoft 的表现超过了 OpenAI 自身的 API。对于谨慎的企业来说,Microsoft 提供的安全性、数据保障以及服务合同捆绑是非常重要的。此外,这些保护措施还使得滥用行为者更容易逃避责任,正如 ByteDance 使用 Azure GPT-4 来训练他们即将推出的大语言模型 (LLMs) 所示。
事实是,如果你不是市场的领头羊,那么你必须采取低价策略来吸引客户。例如,Google 在其 GPT-3.5 竞争产品 Gemini Pro 上,每分钟提供 60 次免费 API 调用。Google 在这方面并不孤单,事实上,如今几乎所有人都在大语言模型 (LLM) 推理上亏本。
纯粹开放模型的服务已经变得非常普遍。尽管开展这种服务的主要开支很大,但初始的资本需求并不高。有许多次级云服务提供了优惠的定价(这主要是因为他们对投资回报的期望过高),但使用这些服务可能需要承担一定的安全风险。
对公司而言,租赁一些 GPU 并开始利用 vLLM 和 TensorRT-LLM 等库在 Nvidia 和 AMD 的 GPU 上运行开源模型变得轻而易举。PyTorch 在推理 (inference) 性能上也越来越快,因此进入这一领域的门槛正急剧降低。相关的一点是,可以查看 Nvidia 和 AMD 在 LLM 推理性能方面,关于 MI300 与 H100 的激烈公开争论。AMD 对此的回应让 Nvidia 感到相当尴尬,因为 Nvidia 最初发布了一个具有误导性的博客文章。
随着 Mistral 推出的 Mixtral,推理成本出现了一场激烈的价格竞争。这主要是由那些燃烧风险资本、希望通过规模化运营来实现盈利的初创公司所推动。OpenAI 的 GPT-3.5 Turbo 模型的运行成本本质上比 Mixtral 要低很多,OpenAI 之所以能维持较高的利润率,主要得益于他们能够实现非常高的批处理规模。这种高批量处理的能力是其他用户基础较小的竞争者所不具备的。
OpenAI 对每百万输入 Token 的收费为 1.00 美元,每百万输出 Token 的收费为 2.00 美元。尽管运营成本更高,但拥有更高质量模型的 Mistral 为了吸引客户,其定价必须低于 OpenAI。因此,Mistral 对每百万输入 Token 的收费为 0.65 美元,每百万输出 Token 的收费为 1.96 美元。实际上,他们的定价策略是被市场力量所左右的,这种定价更多地受市场驱动,而非 Mistral 运行推理(inference)的成本和目标投资回报率。需要注意的是,下面的性能数据是基于现有模型上自定义推理堆栈所达到的,而非我们与大量部署者讨论过的尚未优化的 TensorRT-LLM 或 vLLM。由于 Mistral 尚未开发出高度优化的自定义推理堆栈,他们的性能甚至低于以下数据。
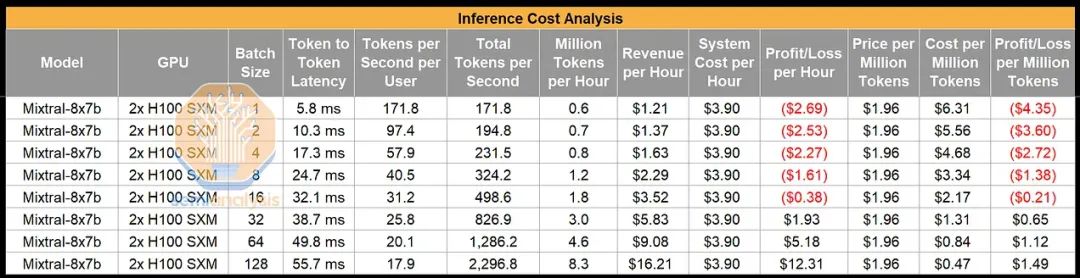
我们稍后将详细探讨这些数字,但总体来说,即使在极为乐观的情况下,假设两个 H100 GPU 以 BF16 格式持续全天候运行,每小时成本为 1.95 美元,Mistral 仍然只是勉强维持运营,并且使用了相当大的批量处理(batch size)。当然,您可以直接测试 API,会发现他们的 Token 处理速度相当快,这意味着他们并未使用如此大的批量处理。因此,他们的 API 很可能是以亏损为代价的市场引导策略,这在逻辑上是必要的,因为要想在有强大现有竞争者的市场中吸引客户,就必须采取这种策略。Mistral 的中期目标可能是希望通过增加交易量,最终在硬件和软件成本降低后实现盈利。
Mistral 不愿落后,各方都急于以更低的价格提供 Mixtral 模型的推理服务。每隔几小时,就有新公司宣布其定价。首先是 Together,提出每百万 Token 输出收费 0.60 美元,不收输入成本。紧随其后的是 Perplexity,定价为 0.14 美元输入/0.56 美元输出,然后是 Anyscale 提出 0.50 美元输出。最后 Deepinfra 出价 0.27 美元输出……我们本以为这就是极限了……但随后 OpenRouter 免费提供了此服务!需要指出的是,他们宣称的每秒 Token 数量实际上是无法实现的,并且施加了极其严格的速率限制,以至于几乎无法进行测试。
所有这些推理服务目前都处于亏损状态。
需要注意的是,2x H100 实际上并不是运行 Mixtral 模型推理的最佳选择。实际上,由于 2x A100 80GB 在每美元带宽上大约高出 32%(假设内存带宽利用率相似),它更具成本效益。A100 显著较低的浮点运算性能(FLOPS)对推理性能的影响也不大。值得注意的是,在目前这样崩溃的定价水平下,即使是 2xA100 也无法实现盈利。在本报告的后续部分,我们还将展示 H200 和 MI300X 在推理方面带来的巨大优势。
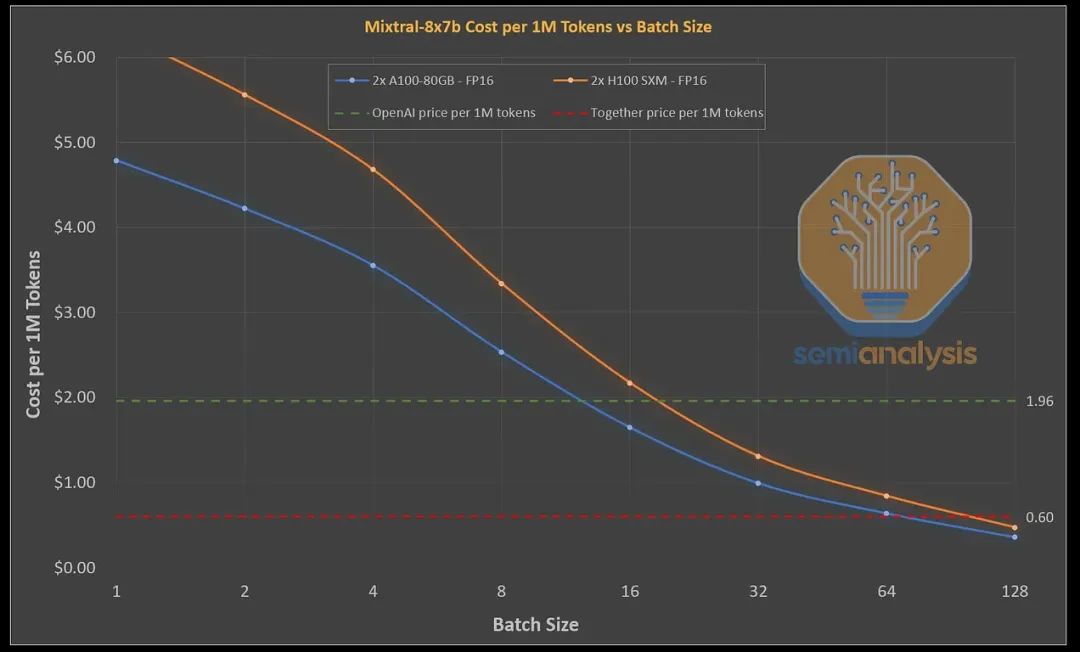
因为 Mixtral 是一种集成了多个专家系统的模型,所以当你增加处理批次的大小时,它的工作方式会发生显著变化。在只处理单个数据批次的情况下,每次前向传播只会激活模型中很小一部分的参数,这让模型即使在较低的带宽和每个 Token 的浮点运算次数 (FLOPS) 下也能展现出强大的处理能力。但这种理想情况只有在你处理的数据批次大小为 1 且拥有足够的内存容量来容纳整个模型时才能实现。
随着处理批次大小的增加,模型中更多的专家系统将被启用,这就要求在每次前向传播时,整个模型的所有参数都需要被读取。同时,每个解码的 Token 仍然只会经过两个专家系统的处理。因此,像 Mixtral 和 GPT-4 这样的基于专家系统的模型 (MoE 模型) 相比于密集型模型来说,对带宽的需求更高。
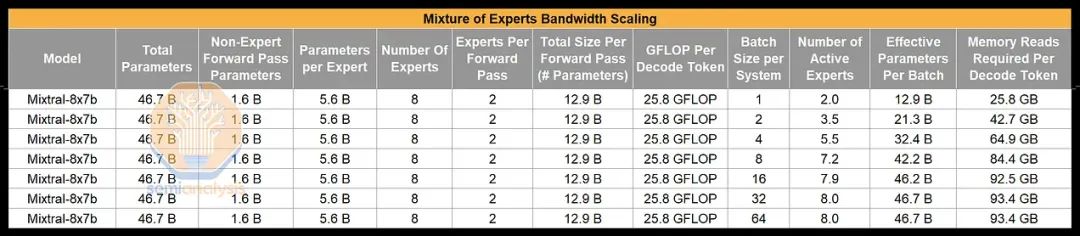
这对于大语言模型 (LLM) 的推理过程有着重大的影响,因为与密集型模型相比,成本的缩放方式大相径庭。简而言之,对于 MoE 模型,虽然提高处理批次的大小仍然可以减少成本,但由于需要更多的内存带宽,其成本降低的幅度不及密集型模型那么显著。这也是为什么基础模型不能无限增加更多专家系统的主要原因之一。在大规模推理成本方面,理想情况是使用高批次大小进行处理,但与密集型模型相比,MoE 模型从中获得的好处并不那么显著。
Given Together 在上述竞争中显然拥有最佳的推理引擎,尤其是在可靠性、首个 Token 生成时间、每秒生成 Token 数量、无人为设定的低速率限制方面表现突出,而且他们坚决不会像其他提供商那样在用户不知情的情况下隐秘地改变模型的量化方式,因此我们决定深入探讨他们的解决方案,将其作为基准产品进行评估。
我们在过去几天对他们的测试平台和 API 进行了分析。在设置温度为 0 并使用非常规律的长序列时,我们达到了每个序列大约 170 个 Token 每秒的处理峰值。而在处理同样长度但难度更高、温度设为 2 的查询时,我们的处理速度只能达到每秒大约 80 个 Token。
请注意,实际上,由于 Together 服务于众多用户且批处理规模相当大,所以前面提到的数据实际上比看起来要差。上文提及的每秒 Token 数量是在展示理想情况下的小批量处理场景。我们的研究显示,相比使用基于 H100 的系统,Together 使用 2xA100 80GB 系统会更合适。温度和性能测试也表明,Together 采用了一种名为“推测性解码”的技术。

推测性解码 / Medusa
关于推测性解码,我们之前已经有了更详尽的说明。简单来说,推测性解码是指在一个大型且运行较慢的模型前,先运行一个小型且快速的初稿模型。这个初稿模型会向更大、更慢的审阅模型提供多种预测,帮助它提前生成多个 Token。大模型随后会一次性检查这些提前生成的预测,而不是像平常那样逐个生成 Token。审阅模型可能会采纳初稿模型的建议,一次生成多个 Token,或者拒绝这些建议,按照常规方式逐个生成 Token。
推测性解码的主要目的是减少生成每个 Token 所需的内存带宽。遗憾的是,类似推测性解码的技术在诸如 Mixtral 这样的混合专家模型上并不能显著提升性能。这是因为随着批处理规模的扩大,你需要的内存带宽也会增加,因为初稿模型的不同建议需要发送到不同的专家那里。同样,混合专家模型上的预填充 Token 相对于密集型模型来说成本更高。
回到之前提到的温度问题。LLM 的温度实际上是一个控制创造性或随机性的滑块。我们之所以测试了高低不同的温度,是因为在低温度下,初稿模型更有可能正确生成审阅模型会接受的 Token。但在高温度下,审阅模型的反应更加无规律,因此初稿模型很难提前准确预测 Token。调整温度是衡量模型实际每秒 Token 生成速率的众多方法之一,如果不这样做,像推测性解码这样的技术会干扰任何逆向工程或性能分析的尝试。

量化技术
量化技术的应用能显著提升模型运行的速度和成本效率。但如果处理不当,量化可能会严重降低模型质量。一般来说,对模型进行量化处理后,需要进行精细的微调 (fine-tune)。然而,目前市场上一些低成本的供应商并未进行这一必要的微调步骤,他们往往半途而废地进行量化,忽视了模型的准确性。这些低价供应商的模型,与 16 位 Mixtral 模型相比,生成的输出质量远不如后者。
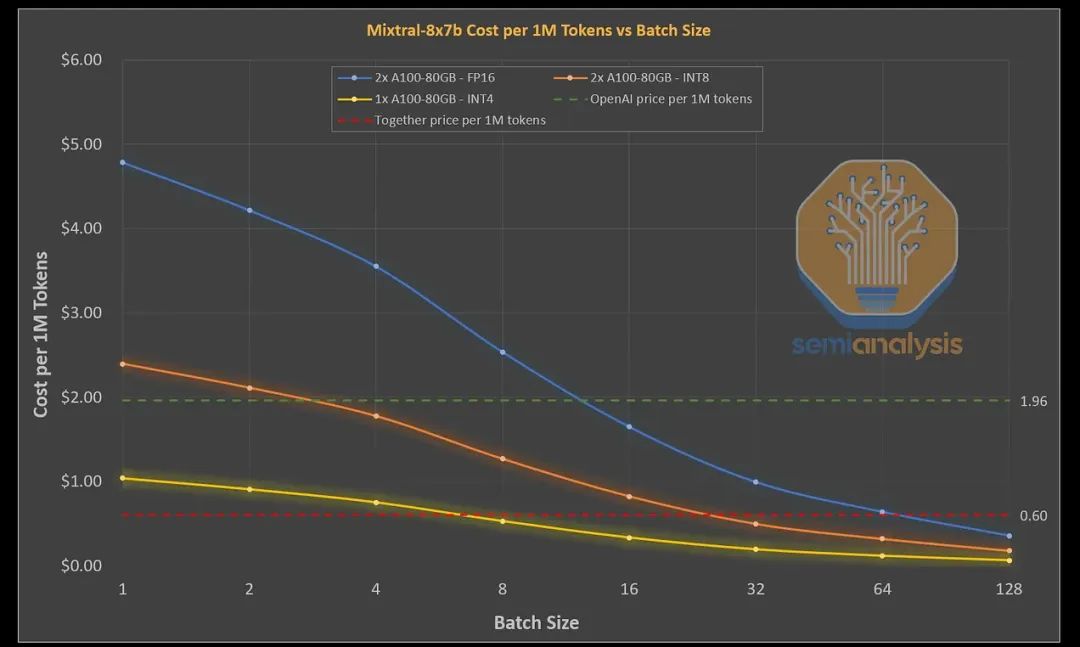
我们相信,研究人员可以在不损害模型质量的前提下,使用 FP8 格式进行模型推理。但我们认为,对于这些大型模型来说,使用 INT4 格式进行推理将是不可行的。此外,使用 FP8 格式的推理仍然需要两个 H100 或 A100 GPU,因为处理的 Token 数量每秒远低于大多数聊天应用所需的 40-50+ 用户水平,并且需要考虑到 KVCache 的大小限制。

H200 & MI300X 性能分析
即将推出的 H200 和 MI300X 将带来变革。它们分别配备了 141GB 和 196GB 的内存,以及比 H100 和 A100 更高的内存带宽。在我们的模型中,与市面上的 A100 和 H100 相比,H200 和 MI300X 的每 Token 成本更具优势。我们发现,摒弃张量并行性(目前 Nvidia 的 NCCL 实现在全归约方面表现很差)将带来巨大的好处。
接下来,我们将展示这些系统在成本效益方面的性能。请注意,这些系统目前仍处于初步部署阶段。我们预计,就像一些主要提供商使用基于 H100 系统的高度优化的自定义推理堆栈一样。目前,Nvidia 的闭源 TensorRT-LLM 和 AMD 的相对开放的 vLLM 集成策略并未直接提供此类优化,但我们预期这会随着时间的推移而改变。
▶ M3 MacBook Pro 能提效?程序员、产品经理自证后,CTO:你赢了,新电脑在路上了
▶ Pascal 之父、图灵奖得主 Niklaus Wirth 逝世!发明多款编程语言,首提「算法+数据结构=程序」
▶ 取代iOS,鸿蒙将成为中国第二大智能手机操作系统;Vision Pro或将本月底上架;VCoder:大语言模型的眼睛|极客头条
