
好未来NLP算法工程师面试题9道|含解析
12本七月在线内部电子书在文末,自取~
公众号福利
👉回复【100题】领取《名企AI面试100题》PDF
👉回复【干货资料】领取NLP、CV、ML等AI方向干货资料

 问题1:lora的矩阵怎么初始化?为什么要初始化为全0?
问题1:lora的矩阵怎么初始化?为什么要初始化为全0? 矩阵B被初始化为0,而矩阵A正常高斯初始化
如果B,A全都初始化为0,那么缺点与深度网络全0初始化一样,很容易导致梯度消失(因为此时初始所有神经元的功能都是等价的)。
如果B,A全部高斯初始化,那么在网络训练刚开始就会有概率为得到一个过大的偏移值Δ W 从而引入太多噪声,导致难以收敛。
因此,一部分初始为0,一部分正常初始化是为了在训练开始时维持网络的原有输出(初始偏移为0),但同时也保证在真正开始学习后能够更好的收敛。
问题2:gpt源码past_key_value是干啥的?
在GPT(Generative Pre-trained Transformer)中,past_key_value是用于存储先前层的注意力权重的结构。在进行推理时,过去的注意力权重可以被重复使用,避免重复计算,提高效率。
问题3:gpt onebyone 每一层怎么输入输出
在GPT One-by-One中,每一层的输入是上一层的输出。具体而言,输入是一个序列的嵌入表示(通常是词嵌入),并通过自注意力机制和前馈神经网络进行处理,得到输出序列的表示。
问题4:模型输出的分布比较稀疏,怎么处理?
可以采用一些方法来处理模型输出的分布稀疏,例如使用softmax函数的温度参数调节来平滑输出分布,或者引入正则化技术,如Dropout,以减少模型对特定类别的过度依赖。
问题5:决策树是如何做回归的
决策树回归通过在数据空间中递归划分,每个叶子节点都对应一个具体的回归值。在训练过程中,决策树根据输入特征的不同划分数据,使每个叶子节点尽可能纯净(样本值相似)。叶子节点的回归值可以是该节点内所有训练样本的平均值。
问题6:kl散度的公式和kl散度与交叉熵的区别
KL(Kullback-Leibler)散度衡量了两个概率分布之间的差异。其公式为:
KL散度指的是相对熵,KL散度是两个概率分布P和Q差别的非对称性的度量。KL散度越小表示两个分布越接近。也就是说KL散度是不对称的,且KL散度的值是非负数。(也就是熵和交叉熵的差)
问题7:tfidf公式


, 分母之所以要加 1, 是为了避免分母为 0 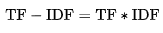
问题8:除了cosin还有哪些算相似度的方法
除了余弦相似度(cosine similarity)之外,常见的相似度计算方法还包括欧氏距离、曼哈顿距离、Jaccard相似度、皮尔逊相关系数等。
问题9:cart树的分裂准则是啥
CART(Classification and Regression Trees)树的分裂准则通常采用基尼不纯度(Gini impurity)或均方误差(Mean Squared Error,MSE)。在分类问题中,CART树寻找能最小化基尼不纯度的特征和阈值进行分裂;在回归问题中,它寻找能最小化均方误差的分裂方式。分裂过程持续递归,直到满足停止条件。
免费送
↓以下12本书电子版免费领,直接送↓


扫码回复【999】免费领12本电子书
(或 找七月在线其他老师领取 )
 点击“ 阅读原文 ”抢宠粉 福利 ~
点击“ 阅读原文 ”抢宠粉 福利 ~