
终于结束了!总结一下这次大赛.

你好呀,我是歪歪。
给大家分享一篇关于性能挑战赛的文章,我看了之后受益匪浅。
阿里云举办的大赛我从 2016 开始关注,每年的赛题我都仔细看了,并思考过解题思路。
虽然每年都是陪跑,但是能读懂排名靠前的参赛选手的比赛思路,也是一件非常有收获的事情。
共勉之。
前言
我参加了阿里云举办的《第三届数据库大赛创新上云性能挑战赛–高性能分析型查询引擎赛道》,传送门:
https://tianchi.aliyun.com/competition/entrance/531895/introduction
截止到 8 月 20 日,终于结束了漫长的赛程。
作为阿里云员工的我,按照赛题规定,只能参加初赛,不能参加复赛,出于不影响比赛的目的,终于等到了比赛完全结束,才动笔写下了这篇参赛总结。
照例先说成绩,这里贴一下排行榜,总共有 1446 只队伍,可以看到不少学生和其他公司的员工都参赛了。
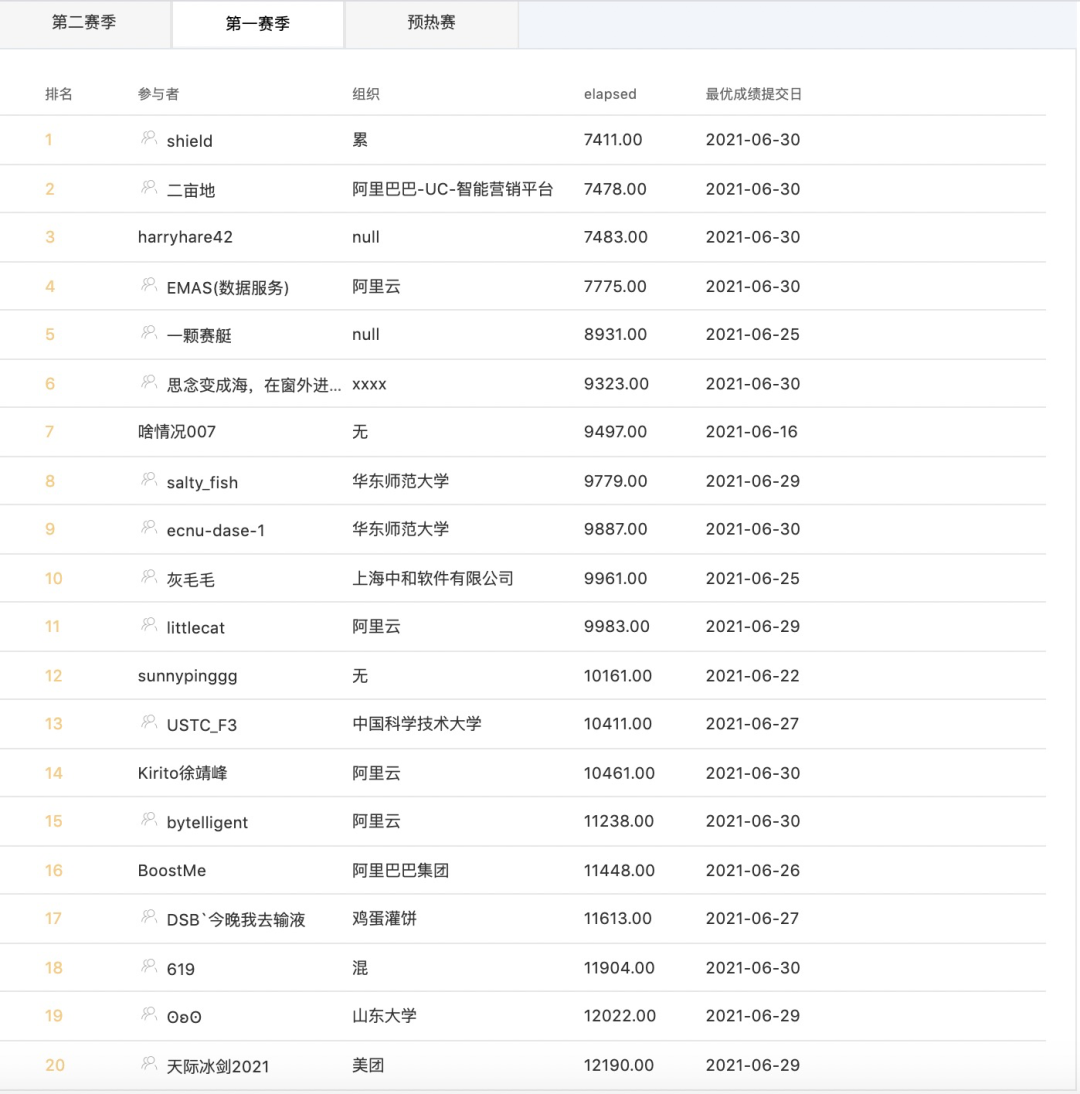
我的成绩是第 14 名,内部排名也是进入了前五。
先简单点评下这次比赛吧。
首先是主办方的出题水平,还是非常高的。
- 全程没有改过赛题描述
- 全程没有清过榜单
- 没有暗改过数据
- 赛题做到了“题面描述简单,实现具有区分度”,让不同水平的参赛者都得到了发挥
- 评测友好,失败不计算提交次数
这些点要大大点一个赞,建议其他比赛的主办方都来参考下,向这次出题的水准看齐。
不好的点,我也吐槽下:
- 内部赛奖励太敷衍了,倒不如送我点公仔来的实在
- 复赛延期了两周,让很多选手的肝有些吃不消
这篇文章我觉得得先明确一个定位,复赛和初赛技术架构相差是很大的,而我没有参加复赛,并没有发言权,所以就不去详细介绍最终的复赛方案了。
我的这篇文章还是以初赛为主,一方面聊的话题也轻松些,另一方面初赛的架构简单一些,可以供那些希望参加性能挑战赛而又苦于没有学习资料的同学、初赛没有找到优化点的同学一些参考。
赛题介绍
https://tianchi.aliyun.com/competition/entrance/531895/introduction
题面可以说是非常简单的,其实就是实现一个查询第 N 大的数函数。
它的输入数据一共有两列:

第一行是列名,第二行开始是列的数据。
初赛测试数据:只有一张表 lineitem,只有两列 L_ORDERKEY (bigint), L_PARTKEY (bigint),数据量3亿行,单线程查询 10 次。
如果你还不理解这个题面是什么意思,建议去看下官方提供的评测 demo:
https://code.aliyun.com/analytic_db/2021-tianchi-contest-1
本地就能运行,debug 跑一遍,既能读懂题意,也能得到一个baseline(尽管它不能提交,会爆内存)。
另外需要格外注意的一点,千万不要漏看赛题描述
本题结合英特尔® 傲腾™ 持久内存技术(PMem),探索新介质和新软件系统上极致的持久化和性能
我们的方案一定需要围绕着存储介质的特性去设计,你问我持久内存 PMem 是啥?
老实说,我参赛之前对这个新的技术也是一知半解,但为了成绩,一定需要啃下这个技术,下面我就先介绍下 PMem。
持久内存 PMem 介绍
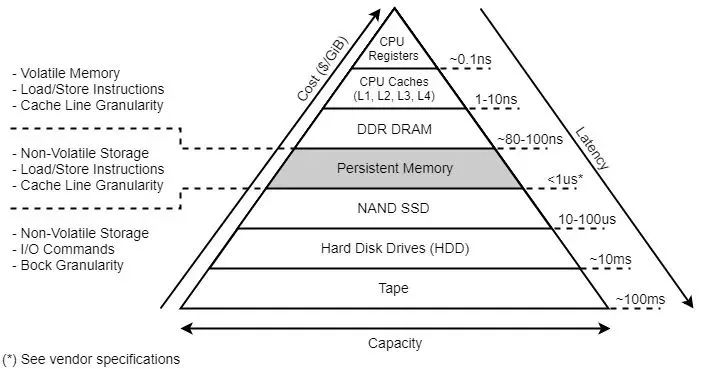
提到内存(DRAM)、固态磁盘(SSD)、机械硬盘(HDD)这些概念,相信大多数人不会感到陌生,都能够道出这几个介质的访问速度差异。而持久内存 PMem 这个概念,相对而言不太为人所知,的确,它是近几年才兴起的一个概念。
持久内存 (PMem) 是驻留在内存总线上的固态高性能按字节寻址的内存设备。PMem 位于内存总线上,支持像 DRAM 一样访问数据,这意味着它具备与 DRAM 相当的速度和延迟,而且兼具 NAND 闪存的非易失性。NVDIMM(非易失性双列直插式内存模块)和 Intel 3D XPoint DIMM(也称为 Optane DC 持久内存模块)是持久内存技术的两个示例。
当我们在讨论这些存储介质时,我们有哪些关注点呢?
本节开头的金字塔图片的三条边直观地诠释了众多存储介质在造价、访问延时、容量三方面的对比。我下面从访问延时、造价和持久化特性三个方面做一下对比。
访问延时
内存 DRAM 的访问延时在 80~100ns,固态硬盘 SSD 的访问延时在 10~100us,而持久内存介于两者之间,比内存慢 10 倍,比固态硬盘快 10~100 倍。
造价
目前为止,将 PMem 技术正式商用的公司,貌似只有 Intel,也就是本次比赛的赞助商。
Intel optane DC persistent memory 是 Intel 推出的基于 3D Xpoint 技术的持久内存产品,其代号为 Apace Pass (AEP)。
所以大家今后如果看到其他人提到 AEP,基本心理就有数了,说的就是 PMem 这个存储介质。
在某电商平台看看这东西怎么卖的:
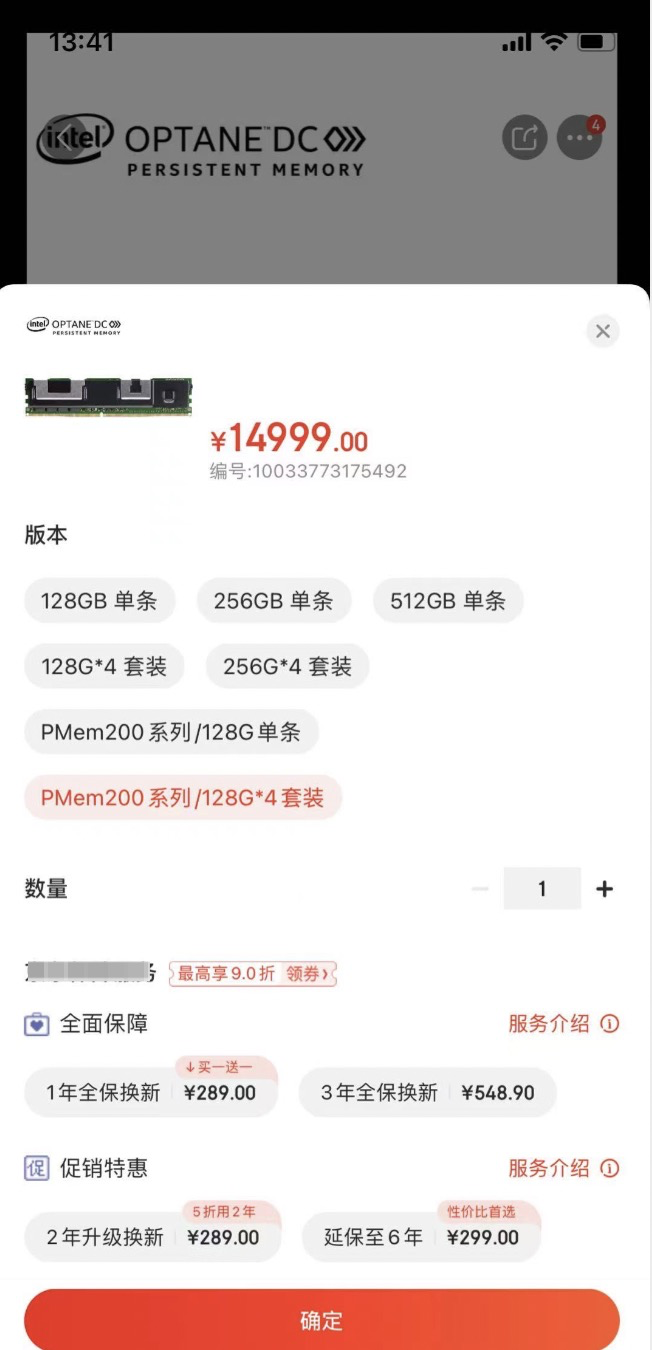
好家伙,128 * 4 条,卖 15000,折合下来,一根 PMem 就要 3000~4000。
同时我们也注意到,傲腾系列的 PMem 产品最高规格也就只有 512G,基本佐证了金字塔中的 Capacity 这一维度,属于内存嫌大,磁盘嫌小的一个数值。
持久化
这东西咱们的电脑可以装吗?
当然可以,直接插在内存条上就成。
我们都知道内存是易失性的存储,磁盘是持久化的存储,而介于两者之间的持久内存,持久化特性是什么样的呢?
这一点,不能望文生义地认为 PMem 就是持久化的,而是要看其工作模式:
Memory Mode 和 AppDirect Mode。
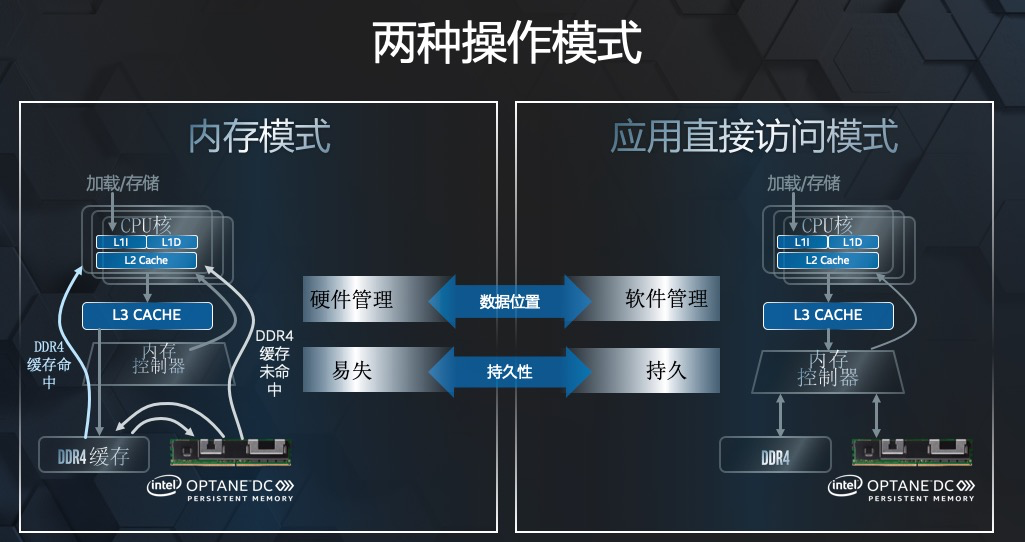
本文就不过多展开介绍了这两种模式了。
简单来说,PMem 工作在 Memory Mode 时,是易失性的,这时候,你需要使用专门的一套系统指令去进行存取。
PMem 工作在 AppDirect Mode 时,可以直接把 PMem 当成一块磁盘来用,PMem 背后适配了一整套文件系统的指令,使得常规的文件操作可以完全兼容的跑在 PMem 之上。
我花了这么大的篇幅介绍 PMem,仍然只介绍了 PMem 特性非常小的一部分,最多让大家知道 PMem 是个啥,至于怎么利用好这块盘,我后边会花专门的一篇文章去介绍。
回到赛题,尽管 intel 提供了一套 PMem 专用的 API:
https://github.com/pmem/pmemkv-java
但由于比赛限定了不能引入三方类库。

所以等于直接告诉了参赛选手,PMem 这块盘是工作在 AppDirect Mode 之下的,大家可以完全把它当成一块磁盘去存取。
这个时候,选手们就需要围绕 PMem 的特性,去设计存储引擎的架构,可能你在固态硬盘、常规文件操作中的一些认知会被颠覆。
这很正常,毕竟 PMem 的出现,就是为了颠覆传统存储架构而生的。
在不能直接操作 PMem 的情况下选手们需要设计 PMem 友好的架构。
赛题剖析
此次的数据输入方式和之前的比赛有很大的不同,选手们需要自行去解析文件,获得输入数据,同时进行处理,如何高效的处理文件是很大的一块优化点。
初赛一共 3 亿行数据,一共 2 列,内存一共 4 G,稍微计算下就会发现,全部存储在内存中是存不下的(不考虑压缩),所以需要用到 PMem 充当存储引擎。
查询的需求是查找到第 N 大的数,所以我们的架构一定是需要做到整体有序,允许局部无序。
赛题数据的说明尤为重要:
测试数据随机,均匀分布。
看过我之前文章的读者,应当敏锐地注意到了均匀分布这个关键词,这意味着我们又可以使用数据的头 n 位来分区了。
这里先给出初赛的最终架构,明确下如何串联各个流程:
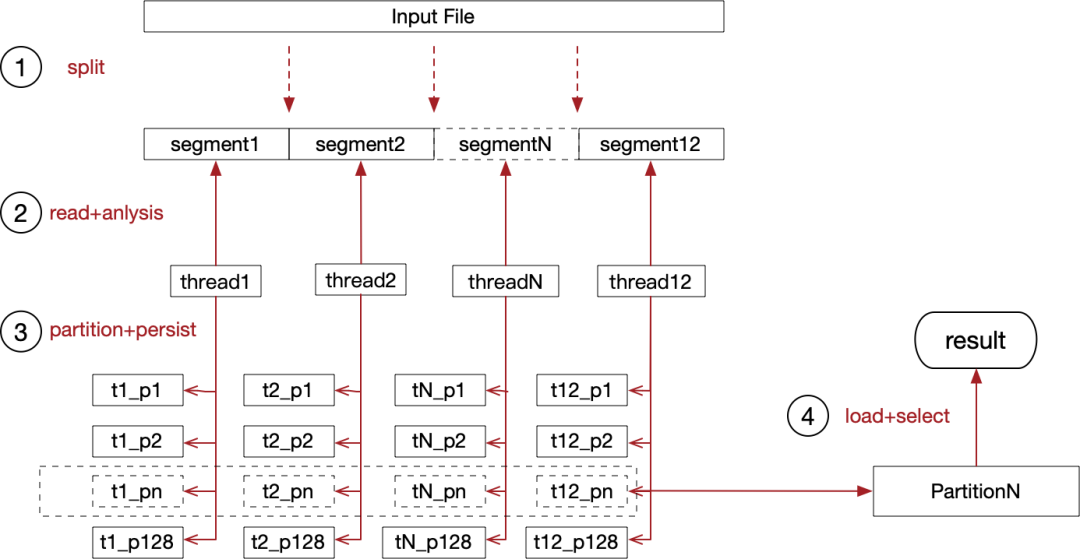
把大象放进冰箱总共需要三步,这道题目仅仅多了一步。
第一步:将输入文件从逻辑上分成 12 等分,这样 12 个线程可以并发读取输入文件。可以借助预处理程序,找到等分的边界。
第二步:每个线程都需要读取各自的文件分片,将读取到的文件流在内存中解析成 long,并且需要根据逗号、换行符来区分出两列数据。
第三步:读取到 long 之后,需要根据头 n 位进行分区,例如选择头 8 位,可以获得 2^(8-1) 即 128 个分区,因为比赛中的数据都是正数,所以减了一个符号位。这样分区之后,可以保证分区之间有序,分区内部无序。
第四步:获取第 N 大的数字时,可以直接根据分区内的数据量,直接定位到最终在哪个分区,这样就可以确保只加载一部分数据到内存中。t1_pn ~ t12_pn 在逻辑上组成了 partitionN,将 partitionN 的数据加载进内存之后,这道题就变成:查询无序数组中第 N 大数的问题了。
实现细节
以下的实现细节,我会给出实现难度,以供大家参考,打分标准:编码实现难度,容不容易想到等综合评分。
多线程按分区读文件(难度:2 颗星)
输入文件按行来分隔数据,第一时间联想到的就是 JDK 提供的 java.io.BufferedReader#readLine() 方法。
但稍微懂点文件 IO 基础的读者都应该意识到,文件 IO 要想快,一定得顺序按块读,所以 readLine 这种方法,想都不用想,必定是低效的。
那有人问了,博主,你给解释解释,什么叫按块读?
最简单的做法是按照固定 4kb 的 buffer 来读取文件,在内存中,自行判断逗号、换行符来区分两列数据,不断移动这个 4kb 的块,这就是按块读了。
if (readBufferArray[i] == '\n') {
}
if(readBufferArray[i] == ',') {
}
光是按块读还不够,为了充分发挥 IO 特性,还可以用上多线程,按照上图中的第一步,我的方案将文件分成了 12 份,这样 12 个线程可以齐头并进地进行读取和解析。
经过测试,多线程比单线程要快 70 多秒,所以没有使用多线程的选手,名次肯定不会高,这是一个通用优化点。
Long 转换(难度:1 颗星)
将文件中的字节读取到内存中,一定会经过 byte[] 到 long 的转换过程,千万不要小看这个环节,这可是众多选手分数的分水岭。
先来看下 demo 中给出的方案:
String[] columns = reader.readLine().split(",");
Long.parseLong(row[i]);
这里面存在两个问题
- 1.先转 String,再转成 Long,多了一次无效转换
- 2.Long.parseLong 方法比较低效,有很多无用判断
我贴一下我方案的伪代码:
long val = 0;
for (int i = 0; i < size; i++) {
val = val * 10 + (readBuffer[i] - '0');
}
直接从字节数组中解析出 Long。
解析出 Long 主要还是为了落盘的时候进行数据对齐,主流方案应该都会解析。
按头 n 位分桶落盘(难度:1 颗星)
在读取到一个 Long 之后,我们可以按照数据的头 n 位,将其写入对应的分区文件中。
这其实也是一个通用的优化点,我在《华为云 TaurusDB 性能挑战赛赛题总结》也介绍过,分区之后,可以保证分区之间有序,即 partition1 中的任意数据一定小于 partition2 中的任意数据。
分区之间无序,主要是为了可以实现分区文件的顺序写。
至于 n 具体是多少,取决于我们想分多个区。
分区太多,会导致整体写入速度下降;分区太少,读取阶段加载的数据会过多,甚至可能导致内存放不下。
每个写线程维护自己的分区文件(难度:3 颗星)
在赛题剖析里面,我给出了我最终方案的流程图,里面有一个细节,每个读取线程从 1/12 个文件分片中读取解析到的 Long 数值,写入了自己线程编号对应的文件中,进行落盘。
并没有采用写入同一个分区文件这样的设计。对比下两种做法的利弊:
- 写线程写入同一个分区文件。好处是读取阶段不需要聚合多份分区文件,坏处是多个线程写入同一个分区需要加锁,会导致竞争。
- 写线程写入自己的分区文件。好处是不需要加锁写,坏处是读取阶段需要聚合读取。
也好理解,两个方案的优劣正好相反,稍微分析一下,由于初赛的查询只有 10 次,所以聚合的开销不会太大,再加上,我们本来就希望读取能做到并发,聚合没有那么可怕。反而是写入时加锁导致的冲突,会严重浪费 CPU。
该优化点,帮助我的方案从 80s 缩短到 50s。
分支预测优化(难度:4 颗星)
这次比赛因为有了 PMem,导致瓶颈根本不出在 IO 上。
以往比赛中,大家都是想尽一切方法,把 CPU 让给 IO。
而这次比赛,PMem 直接起飞了,导致大家需要考虑,怎么优化 CPU。
而 JVM 虚拟机的一系列机制中,就有很多注意事项,是跟 CPU 优化相关的。
在解析 Long 时,我们需要从 4kb 的读缓冲区中解析出 Long 数值,由于文件中的数值是以不定长的字节数组形式出现的,我们只能通过判断逗号、换行符来解析出数值,所以难免会写出这样的代码:
int blockReadPosition = 0;
for (int i = 0; i < size; i++) {
if (readBufferArray[i] == '\n') {
partRaceEngine.add(threadNo, val);
val = 0;
blockReadPosition = i + 1;
} else if(readBufferArray[i] == ',') {
orderRaceEngine.add(threadNo, val);
val = 0;
blockReadPosition = i + 1;
} else {
val = val * 10 + (readBufferArray[i] - '0');
}
}
思考下,这段代码会有什么逻辑问题吗?
当然没有,相信很多选手也会这么判断。
但不妨分析下,输入文件大概有 10G 左右,所有的字节都会经过 if 判断一次,而实际上,大多数的字符并不是 \n 和 , 。
这会导致 CPU 被浪费在分支预测上。
我的优化思路也很简单,直接用循环,干掉 if/else 判断
for (int i = 0; i < size; i++) {
byte temp = readBufferArray[i];
do {
val = val * 10 + (temp - '0');
temp = readBufferArray[++i];
} while (temp != ',');
orderRaceEngine.add(threadNo, val);
val = 0;
// skip ,
i++;
temp = readBufferArray[i];
do {
val = val * 10 + (temp - '0');
temp = readBufferArray[++i];
} while (temp != '\n');
partRaceEngine.add(threadNo, val);
val = 0;
// skip \n
}
readPosition += size;
一般来说,再没有办法去掉 if/else 的前提下,我们可以遵循的一个最佳实践是,将容易命中的条件放到最前面。
该优化帮助我从 48s 优化到了 24s。
另外,也可以利用数据特性,因为大多数数据是 19 位的数字,可以直接判断第 20 位是不是 , 或者 \n 从而减少分支预测的次数。
quickSelect(难度:4 颗星)
在查询阶段,查询一个分区内第 N 大的数,最简单的思路是排序之后直接返回,a[N],受到评测 demo 的影响,很多选手可能忽略了可以使用 quickSelect 算法。
Quick Select 你可能没听过,但快速排序(Quick Sort)你肯定有所耳闻,其实他们两个算法的作者都是 Hoare,并且思想也非常接近:
选取一个基准元素 pivot,将数组切分(partition)为两个子数组,比 pivot 大的扔左子数组,比 pivot 小的扔右子数组,然后递推地切分子数组。
Quick Select 不同于 Quick Sort 之处在于其没有对每个子数组做切分,而是对目标子数组做切分。
其次,Quick Select 与Quick Sort 一样,是一个不稳定的算法。
pivot 选取直接影响了算法的好坏,最坏情况下的时间复杂度达到了 O(n2)。
Quick Select 的 Java 实现如下:
public static long quickSelect(long[] nums, int start, int end, int k) {
if (start == end) {
return nums[start];
}
int left = start;
int right = end;
long pivot = nums[(start + end) / 2];
while (left <= right) {
while (left <= right && nums[left] > pivot) {
left++;
}
while (left <= right && nums[right] < pivot) {
right--;
}
if (left <= right) {
long temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
left++;
right--;
}
}
if (start + k - 1 <= right) {
return quickSelect(nums, start, right, k);
}
if (start + k - 1 >= left) {
return quickSelect(nums, left, end, k - (left - start));
}
return nums[right + 1];
}
该优化帮我从 24s 优化到 17s。
查询阶段多线程读分区(难度:2 颗星)
前文提到了为了避免写入阶段的冲突,每个线程维护了自己的分区文件,在查询时,则需要聚合多个线程的数据。
这个时候不要忘记也可以多线程读取,因为初赛的评测程序是单线程测评的,IO 无法打满,需要我们控制多线程,充分利用 IO。
该优化帮我从 17s 优化到了 15s。
循环展开(难度:4 颗星)
尽管得知我们可以知道字节数组的长度,从而用循环来解析出 Long,但根据 JMH 的优化项来看,手动展开循环,可以让程序更加地快,例如像下面这样。

这样的优化大概仅仅能提升 1s~2s,甚至不到,但越是到前排,1~2s 的优化就越会显得弥足珍贵。
总结
还有很多之前我提到过的一些通用优化技巧,例如顺序读写、读写缓冲、对象复用等等,就不在这里继续赘述了,尽管 PMem 和固态硬盘这两种介质有一定的差异,但这些优化技巧依旧是通用的。
因为这次比赛,IO 的速度实在是太快了,导致优化的方向变成如何优化 CPU,合理分配 CPU,让 CPU 更多地分配给瓶颈操作,这是其他比赛中没有过的经历。
还有一些点是通过调参来实现的,例如文件分片数,读写缓冲区的大小,读写的线程数等等,也会导致成绩相差非常大,这就需要不断地肝,不断地 benchmark 了。
不光是成功的优化点值得分享,也拿一个失败的优化分享一下,例如,将一半的数据存储在内存中,最终发现,申请内存的时间,倒不如拿去进行文件 IO,最终放弃了,可以见得在合理的架构设计下,PMem 的表现的确彪悍,不输于内存存取。
这次 ADB 的性能挑战赛,虽然只参加了初赛,但收获的技能点还是不少的。
印象最深的便是 PMem 这块盘的表现和我理解中的 SSD 还是有一定差距的,导致之前的一些经验不能直接在这场比赛中运用。
我也大概了解了很多复赛前排选手使用到了很多的奇技淫巧,每一个看似奇葩的优化点背后,可能都蕴含着该选手对操作系统、文件系统、编程语言等方面超出常人的认知,值得喝彩。
感到遗憾的地方还是有的。
这次比赛只能让 PMem 工作在 APP Direct 模式下,没有能够真正做到颠覆性。
如果有一场比赛,能够支持 Memory Mode,那我应该能收获到对持久内存更加深刻的认知。
我一直反复安利我的读者尽可能地参加各类性能挑战赛,特别是在校生、实习生或者刚进入职场的新人,这种比赛是实践的最好机会,看书不是。
好了,最后,我将我的代码开源在了 github:
https://github.com/lexburner/2021-tianchi-adb-race
我是 why,你也可以叫我小歪,一个主要写代码,经常写文章,偶尔拍视频的程序猿。
欢迎关注我呀。