
R-wordcloud: 词云图

好几位读者来信说,《R语言数据可视化之美》(增强版)的词云图的代码有问题,我今天更新了一轮,这主要原因在R语言及其包的更新,导致源代码有可能运行错误。R语言的优势在于其开源,有世界的专家学者一起开发新的包,以及其R语言本身不断更新迭代增强;这也是它的问题,因为很多时候不同包由于版本问题,会导致老版本的程序运行有误。
R中的wordcloud包提供了绘制词云图的函数:wordcloud()、comparison.cloud()和commonality. cloud()。其中,用wordcloud(words,freq)函数绘制词云图时,只需要提供文本(words)和对应的频率(frequency);comparison.cloud(term.matrix)和cpommonality.cloud(term.matrix)可以绘制对比词云图,term. matrix是一个行名,代表文本,每列数值代表文本对应的频数的矩阵。图3-9-3 单篇文章的词云图和图3-9-4两篇文章的词云图的具体代码如下所示。
library(tm)library(wordcloud)Paper1<-paste(scan("Paper1.txt", what = character(0),sep = ""), collapse = " ") #读入TXT 文档1Paper2<-paste(scan("Paper2.txt", what = character(0),sep = ""), collapse = " ") #读入TXT 文档2tmpText<- data.frame(c(Paper1, Paper2),row.names=c("Text1","Text2"))df_title <- data.frame(doc_id=row.names(tmpText),text=tmpText$c.Paper1..Paper2.)ds <- DataframeSource(df_title)#创建一个数据框格式的数据源,首列是文档id(doc_id),第二列是文档内容corp <- VCorpus(ds)#加载文档集中的文本并生成语料库文件corp<- tm_map(corp,removePunctuation) #清除语料库内的标点符号corp <- tm_map(corp,PlainTextDocument) #转换为纯文本corp <- tm_map(corp,removeNumbers) #清除数字符号corp <- tm_map(corp, function(x){removeWords(x,stopwords())}) #过滤停止词库term.matrix <- TermDocumentMatrix(corp)#利用TermDocumentMatrix()函数将处理后的语料库进行断字处理,生成词频权重矩阵term.matrix <- as.matrix(term.matrix) #频率colnames(term.matrix) <- c("Paper1","paper2")df<-data.frame(term.matrix)write.csv(df,'term_matrix.csv') #导出两篇文章的频率分析结果
导出的文本频率分析结果'term_matrix.csv'如图3-9-2所示,其中文本为索引行名,然后每列对应每篇文章的文本频率,然后我们使用一下语句就可以展示单篇和两篇文章的词云图:
df<-read.csv('term_matrix.csv',header=TRUE,row.names=1)#图3-9-3(a): 单篇文章Paper1数据的展示wordcloud(row.names(df) , df$Paper1 , min.freq=10,col=brewer.pal(8, "Dark2"), rot.per=0.3 )#图3-9-3(b): 单篇文章Paper2数据的展示wordcloud(row.names(df) , df$Paper2 , min.freq=10,col=brewer.pal(8, "Dark2"), rot.per=0.3 )#两篇文章数据的对比#图3-9-4(a):两篇文章的独有部分comparison.cloud(df,max.words=300,random.order=FALSE,colors=c("#00B2FF", "red"))#图3-9-4(b):两篇文章的共有部分commonality.cloud(df,max.words=100,random.order=FALSE,color="#E7298A")
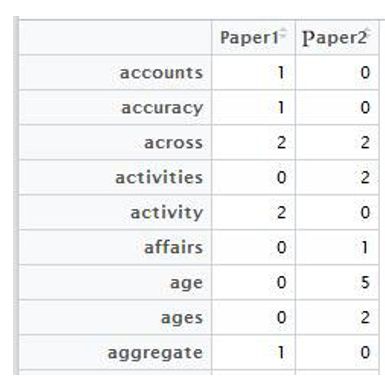
图3-9-2 词的频率数据
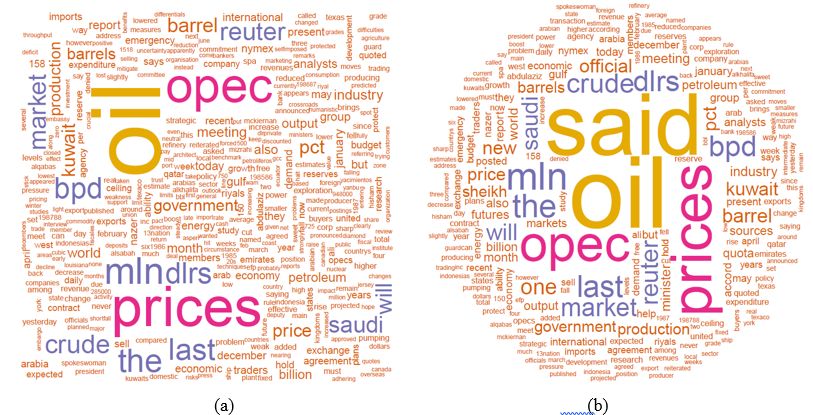
图3-9-3 单篇文章的词云图
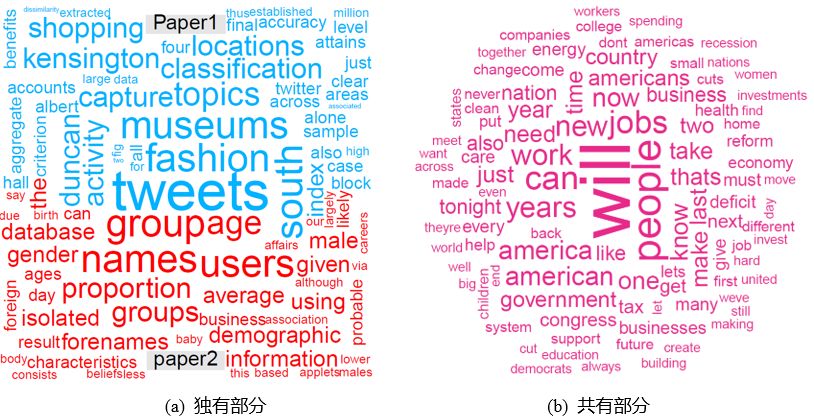
图3-9-4 两篇文章的词云图
【本文内容摘自《R语言数据可视化之美》】
如需联系EasyShu团队
请加微信:EasyCharts
微信公众号【EasyShu】博文代码集合地址
https://github.com/Easy-Shu/EasyShu-WeChat
《R语言数据可视化之美》增强版

增强版配套源代码下载地址
Github
https://github.com/Easy-Shu/Beautiful-Visualization-with-R
百度云下载
https://pan.baidu.com/s/1ZBKQCXW9TDnpM_GKRolZ0w
提取码:jpou