
深入浅出,聊聊实时音视频中的回声消除与降噪

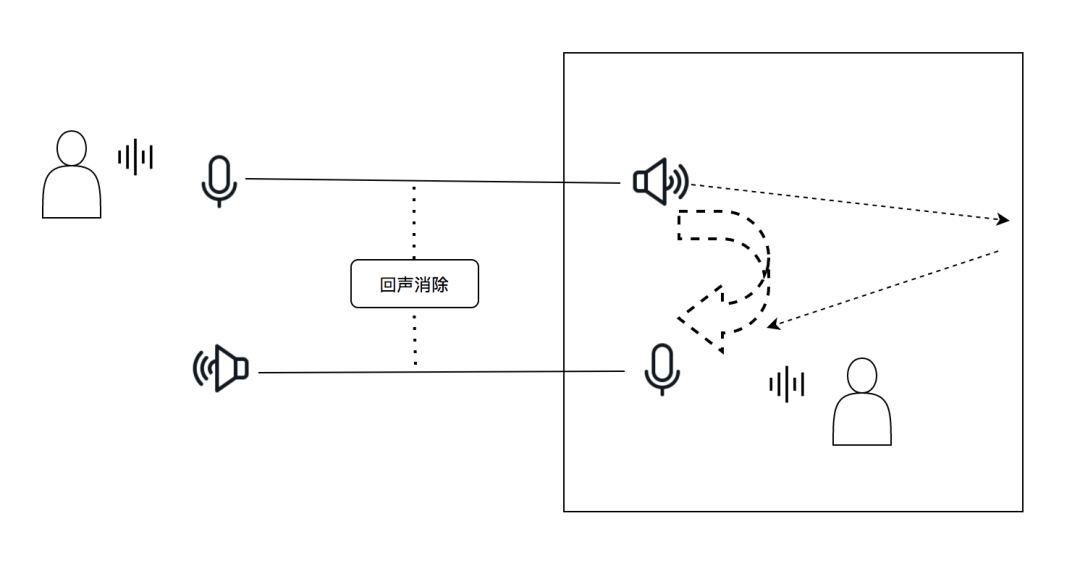
在实时音频互动场景中,回声消除、降噪、自动增益(即 3A 算法)是直接影响音质和体验的重要环节之一。如何降低计算量,提升处理效率,如何兼容更多的设备、环境等,让3A 算法可以适应更多场景等一系列问题是我们做实时音视频开发中必须要解决的难点。
声学环境,包括反射,混响等;
通话设备本身声学设计,包括音腔设计以及器件的非线性失真等;
系统性能,处理器的计算能力以及操作系统线程调度的能力。
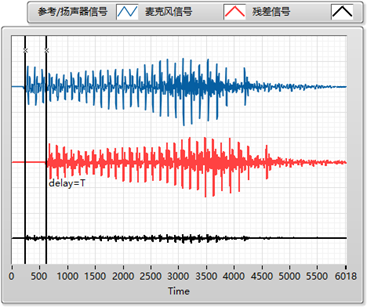
第一步需要找到参考信号/扬声器信号(蓝色折线)跟麦克风信号(红色折线)之间的延迟,也就是图中的 delay=T。
第二步根据参考信号估计出麦克风信号中的线性回声成分,并将其从麦克风信号中减去,得到残差信号(黑色折线)。
第三步通过非线性的处理将残差信号中的残余回声给彻底抑制掉。
延迟估计(Delay Estimation)
线性自适应滤波器(Linear Adaptive Filter)
非线性处理(Nonlinear Processing)
注:双讲是指在交互场景中,互动双方或多方同时讲话,其中一方的声音会受到抑制,从而出现断断续续的情况。这是由于回声消除算法“矫枉过正”,消除了部分不该去除的音频信号。
怎么增强估计算法鲁棒性?
如何降低计算量,又不影响效果?
怎么覆盖更多设备?
等等
另外,在线性自适应滤波器、非线性处理这两个模块中,还会遇到更多问题。
与此同时,在降噪模块中,我们需要考虑如何在不损伤音质的情况下去除噪音。在4 月 7 日晚 8:00,声网Agora 音频体验高级工程师将会在直播课中,为大家逐一分析回声消除与降噪中的难点,以及声网的算法优化实践经验,点击「阅读原文」报名来与他交流吧!
🎙议题:实时场景下的回声消除、信号降噪算法优化实践
🕰直播时间:4月7日(周三) 晚 8:00
👨🏻💻主讲人:姚斯强 声网Agora 音频体验高级工程师
📃演讲内容简介:
1、扫码填写报名表单,报名成功后扫码入群,活动当日会在群里公布直播链接。
2、直播当日会在群里收到直播通知。
| Tips
1. 访问RTC开发者论坛获取技术支持:https://rtcdeveloper.com/
| 关于声网
声网Agora 是实时音视频云行业的开创者,是全球最大的专业服务商,每年为全球超过20万开发者提供年千亿分钟实时音视频服务。开发者只需简单调用 API,30分钟即可在应用内构建多种实时互动场景,实现视频社交、互动直播、语音开黑、互动课堂、AR远程协作、视频客服等。声网的实时互动技术服务覆盖全球各个地区,也在当地提供技术和运营支持,与小米、陌陌、The Meet Group、Hike Messenger、Musical.ly、V-cube、好未来、招商银行、中国移动在线等建立战略合作关系。
点击阅读原文,报名直播