
Redis秒杀实战:微信抢红包(附源码)
为啥写这个微信抢红包项目呢,公司 0202 年 08 月 22 日,公司周年庆,抢了100多红包?,O(∩_∩)O哈哈~
业务流程分析
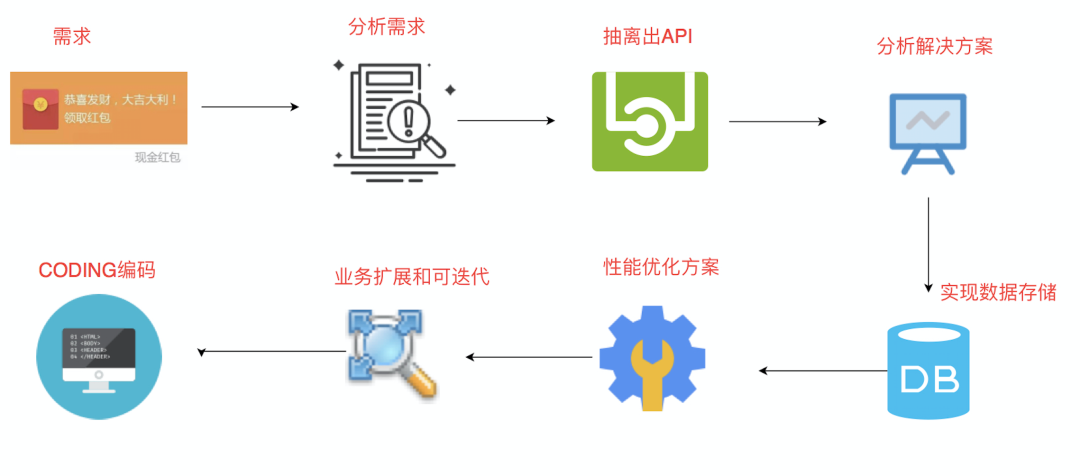
功能拆解
新建红包
在 DB、Redis 分别新增一条记录
抢红包(并发)
「使用技术」
Redis 中数据类型的 String 特性的原子递减(DECR key)和减少指定值(DECRBY key decrement)
「业务」
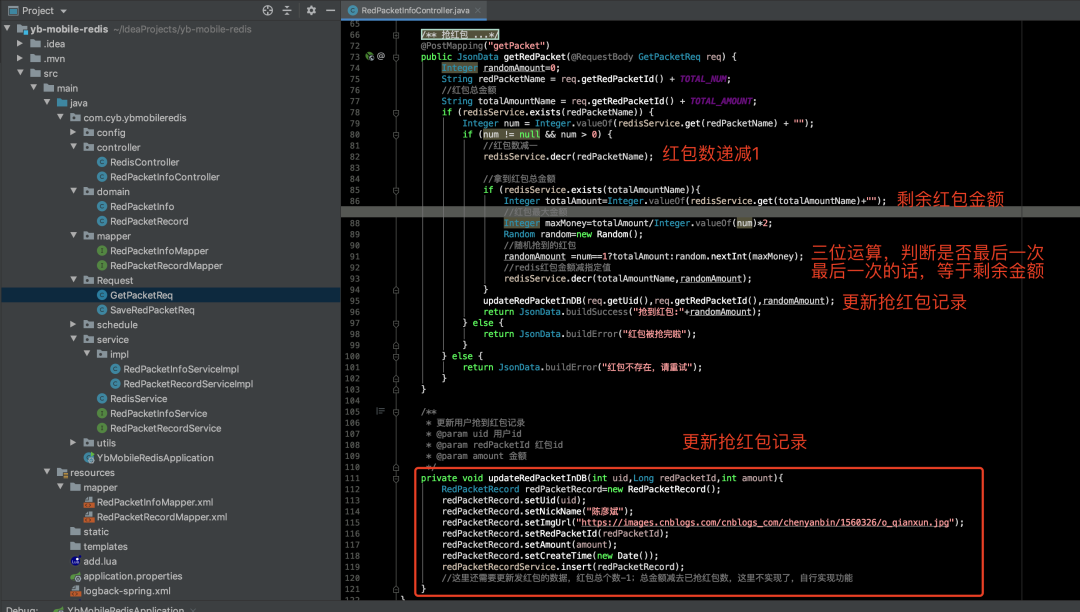
请求 Redis ,当剩余红包个数大于 0,红包个数原子递减,随机获取红包 计算金额,当最后一个红包时,最后一个红包金额=总金额-总已抢红包金额 更新数据库
「查询红包记录」
查询 DB 即可
数据库设计
红包流水表
CREATE TABLE `red_packet_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`red_packet_id` bigint(11) NOT NULL DEFAULT 0 COMMENT '红包id,采⽤
timestamp+5位随机数',
`total_amount` int(11) NOT NULL DEFAULT 0 COMMENT '红包总⾦额,单位分',
`total_packet` int(11) NOT NULL DEFAULT 0 COMMENT '红包总个数',
`remaining_amount` int(11) NOT NULL DEFAULT 0 COMMENT '剩余红包⾦额,单位
分',
`remaining_packet` int(11) NOT NULL DEFAULT 0 COMMENT '剩余红包个数',
`uid` int(20) NOT NULL DEFAULT 0 COMMENT '新建红包⽤户的⽤户标识',
`create_time` timestamp COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE
CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='红包信息
表,新建⼀个红包插⼊⼀条记录';
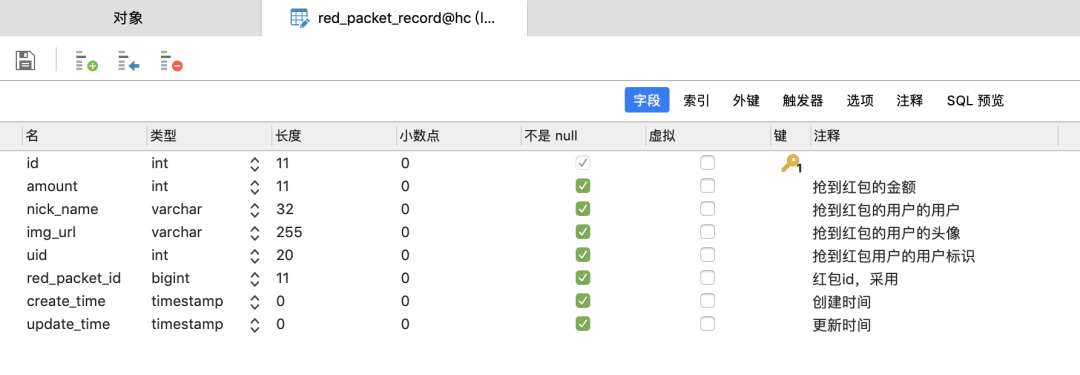
红包记录表
CREATE TABLE `red_packet_record` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`amount` int(11) NOT NULL DEFAULT '0' COMMENT '抢到红包的⾦额',
`nick_name` varchar(32) NOT NULL DEFAULT '0' COMMENT '抢到红包的⽤户的⽤户
名',
`img_url` varchar(255) NOT NULL DEFAULT '0' COMMENT '抢到红包的⽤户的头像',
`uid` int(20) NOT NULL DEFAULT '0' COMMENT '抢到红包⽤户的⽤户标识',
`red_packet_id` bigint(11) NOT NULL DEFAULT '0' COMMENT '红包id,采⽤
timestamp+5位随机数',
`create_time` timestamp COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE
CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='抢红包记
录表,抢⼀个红包插⼊⼀条记录';

发红包 API
发红包接口开发
新增一条红包记录 往 mysql 里面添加一条红包记录 往 redis 里面添加一条红包数量记录 往redis里面添加一条红包金额记录
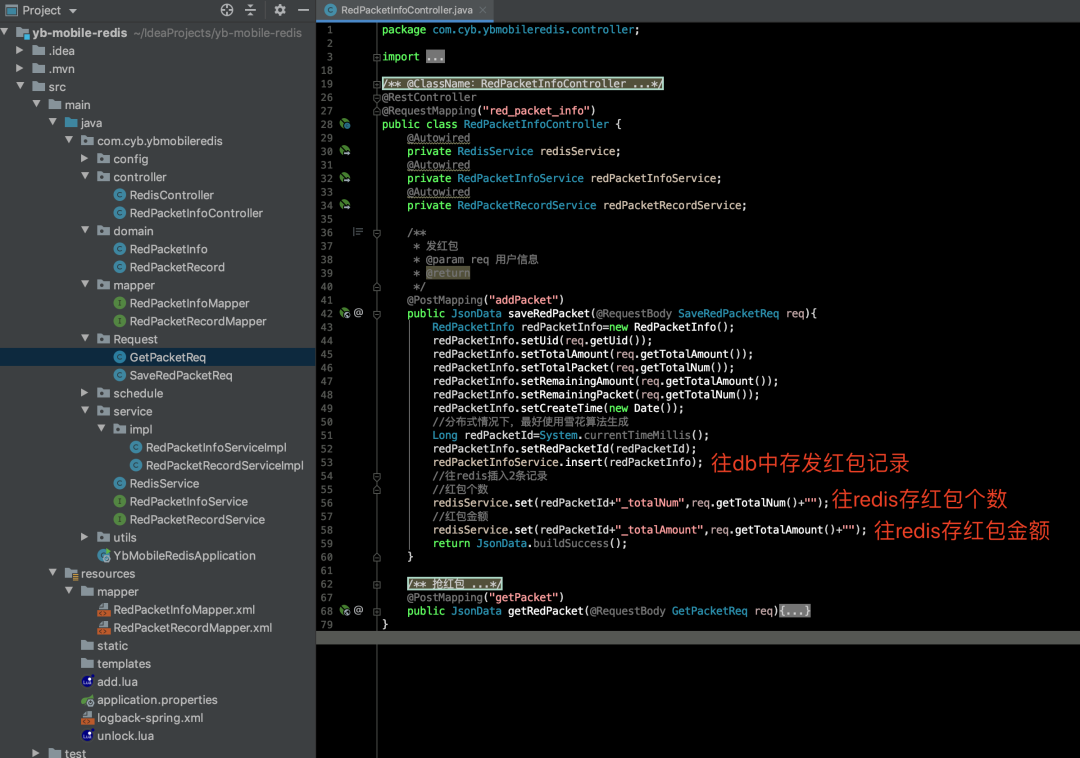
❝往db中就单纯存入一条记录,Service层和Mapper层,就简单的一条sql语句,主要是提供思路,下面会附案例源码,不要慌
❞
抢红包 API
抢红包功能属于原子减操作 当大小小于 0 时原子减失败 当红包个数为0时,后面进来的用户全部抢红包失败,并不会进入拆红包环节 抢红包功能设计 将红包ID的请求放入请求队列中,如果发现超过红包的个数,直接返回 注意事项 抢到红包不一定能拆成功
抢红包算法拆解
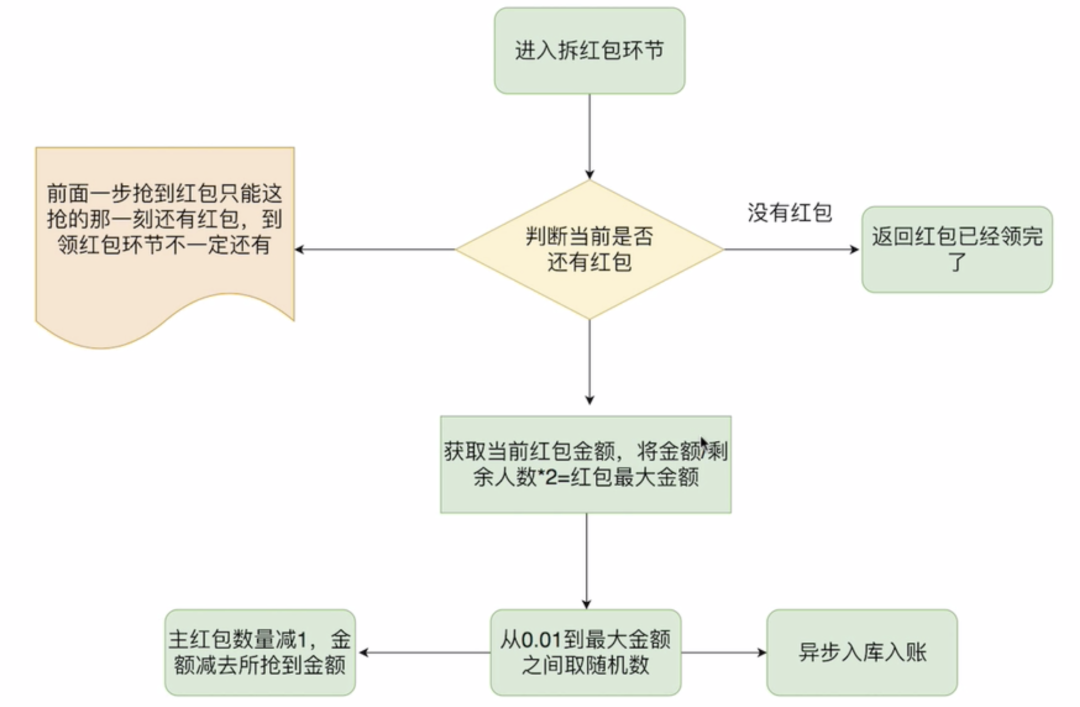
通过上图算法得出,靠前面的人,手气最佳几率小,手气最佳,往往在后面
发 100 元,共 10 个红包,那么平均值是 10 元一个,那么发出来的红包金额在 0.01~20 元之间波动 当前面 4 个红包总共被领了 30 元时,剩下 70 元,总共 6 个红包,那么这 6 个红包的金额在 0.01~23.3 元之间波动
抢红包接口开发
「测试」
「发红包」
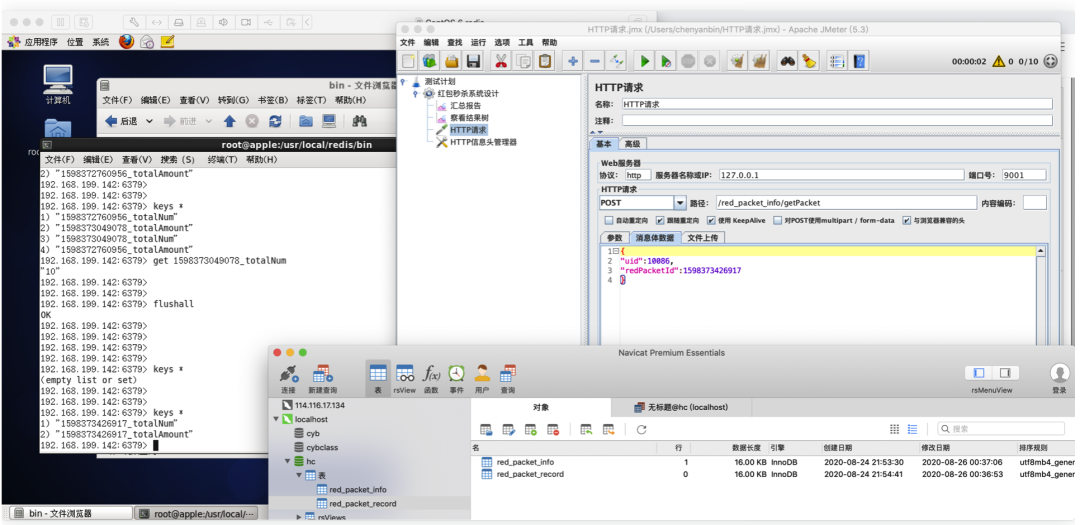
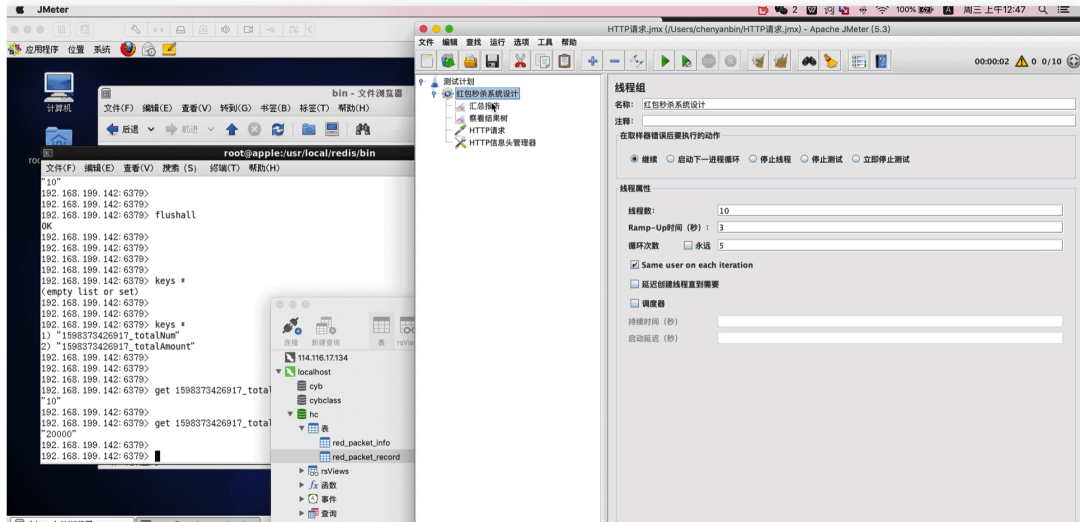
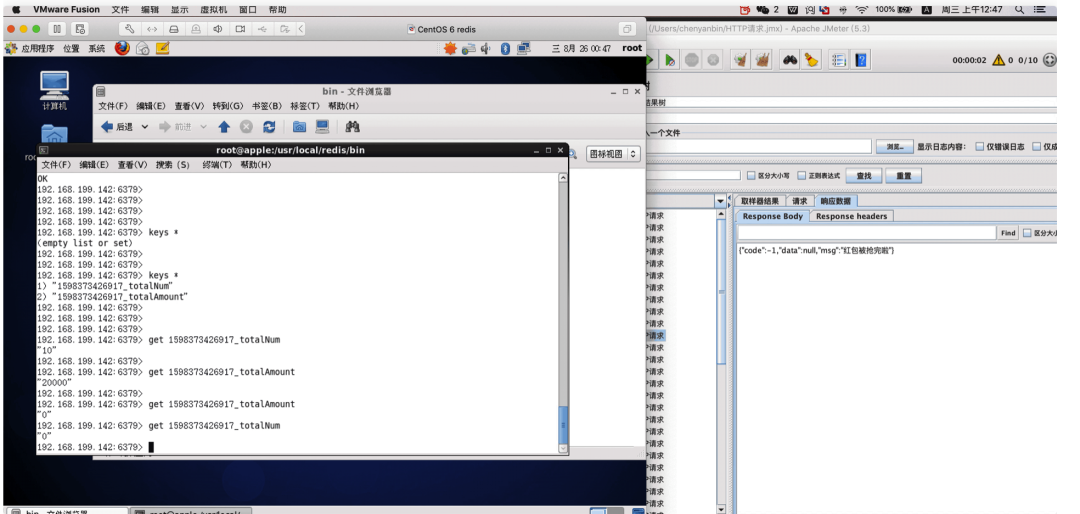
模拟高并发抢红包(Jmeter压测工具)
因为我发了 10 个红包,金额是 20000,使用压测工具,模拟50个请求,只允许前10个请求能抢到红包,并且金额等于20000。
布隆过滤器
介绍
布隆过滤器是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
优点
相比于其他的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数。另外三列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
缺点
但是布隆过滤器的缺点和有点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
布隆过滤器有什么用
黑客流量攻击:故意访问不存在的数据,导致查程序不断访问DB的数据 黑客安全阻截:当黑客访问不存在的缓存时迅速返回避免缓存及DB挂掉 网页爬虫对 URL 的去重,避免爬取相同的URL地址 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮件是否垃圾邮件(同理,垃圾短信) 缓存击穿,将已存在的缓存放到布隆中,当黑客访问不存在的缓存时迅速返回避免缓存及 DB 挂掉
布隆过滤器实现会员转盘抽奖
需求
一个抽奖程序,只针对会员用户有效
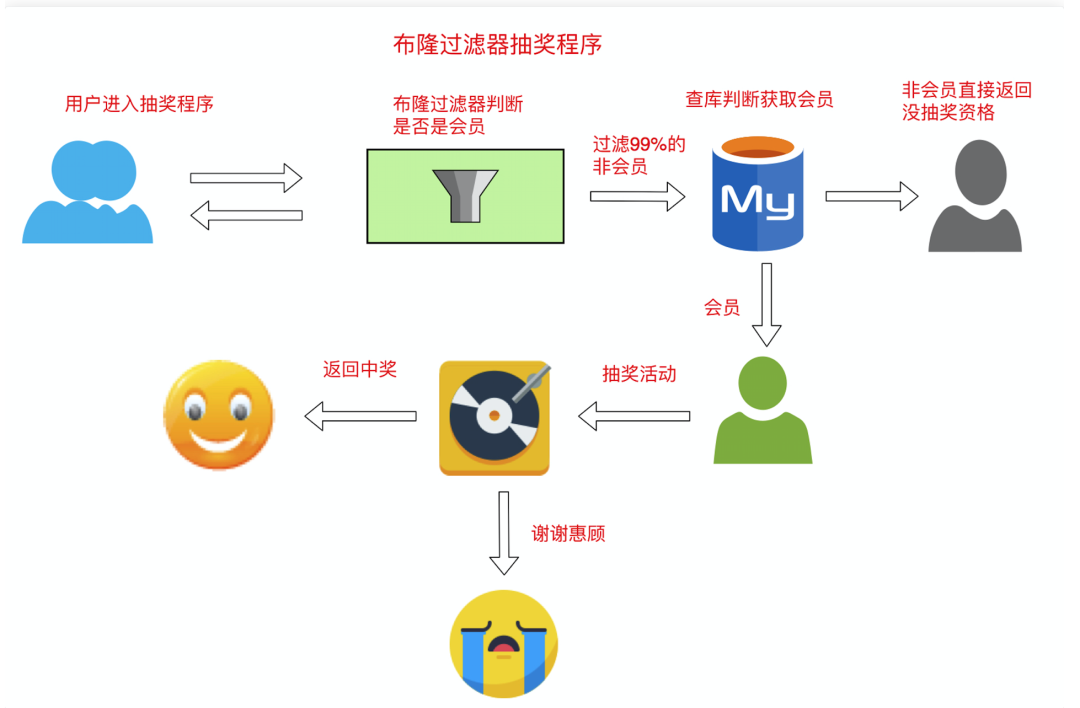
通过google布隆过滤器存储会员数据
程序启动时将数据放入内存中 google自动创建布隆过滤器 用户ID进来之后判断是否是会员
代码实现
引入依赖
com.google.guava
guava
29.0-jre
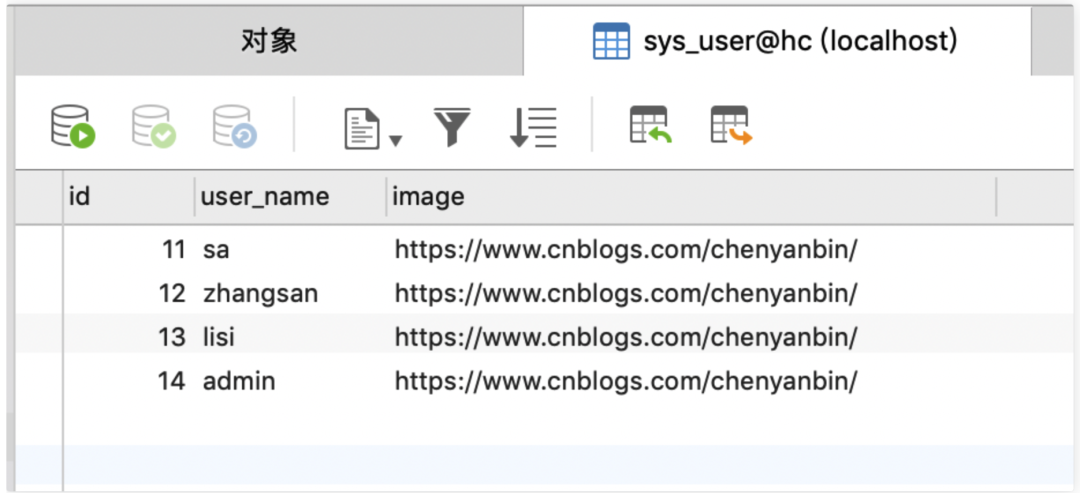
数据库会员表
CREATE TABLE `sys_user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`user_name` varchar(11) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '⽤户名',
`image` varchar(11) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '⽤户头像',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8;
初始化布隆过滤器
dao 层和 dao 映射文件,就单纯的一个 sql 查询,看核心方法,下面会附源码滴,不要慌好嘛
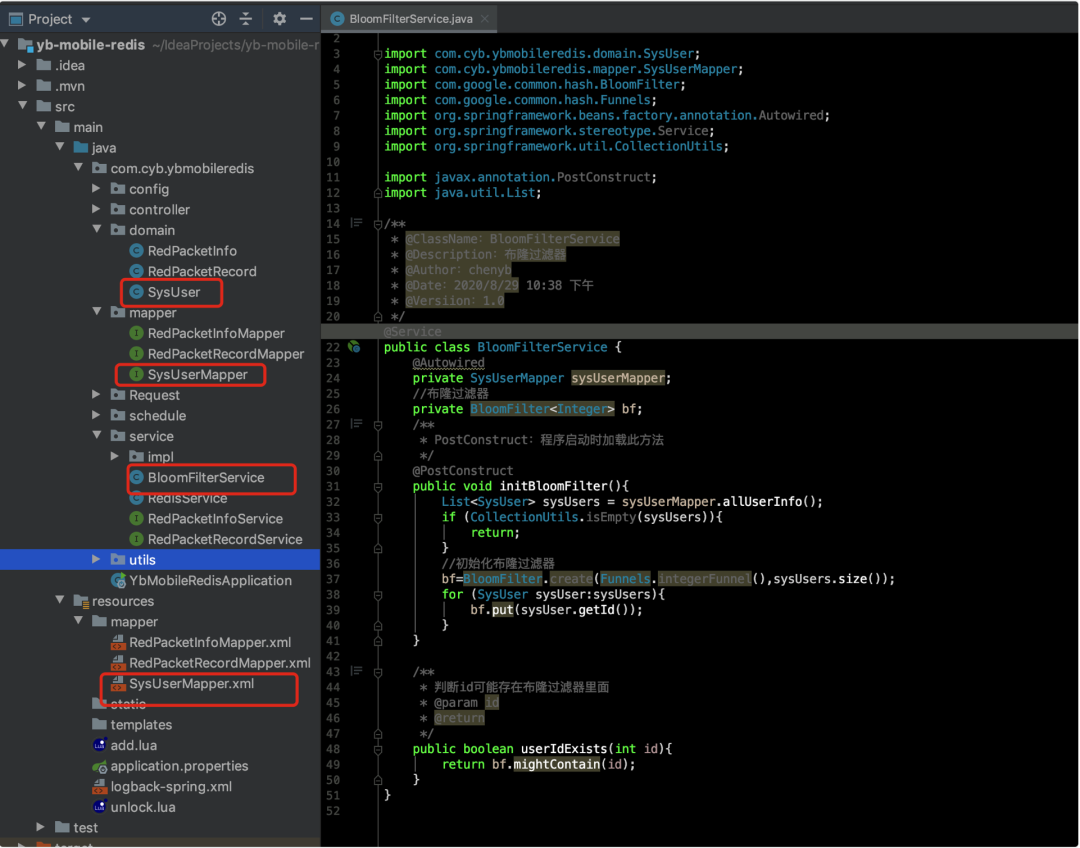
控制层
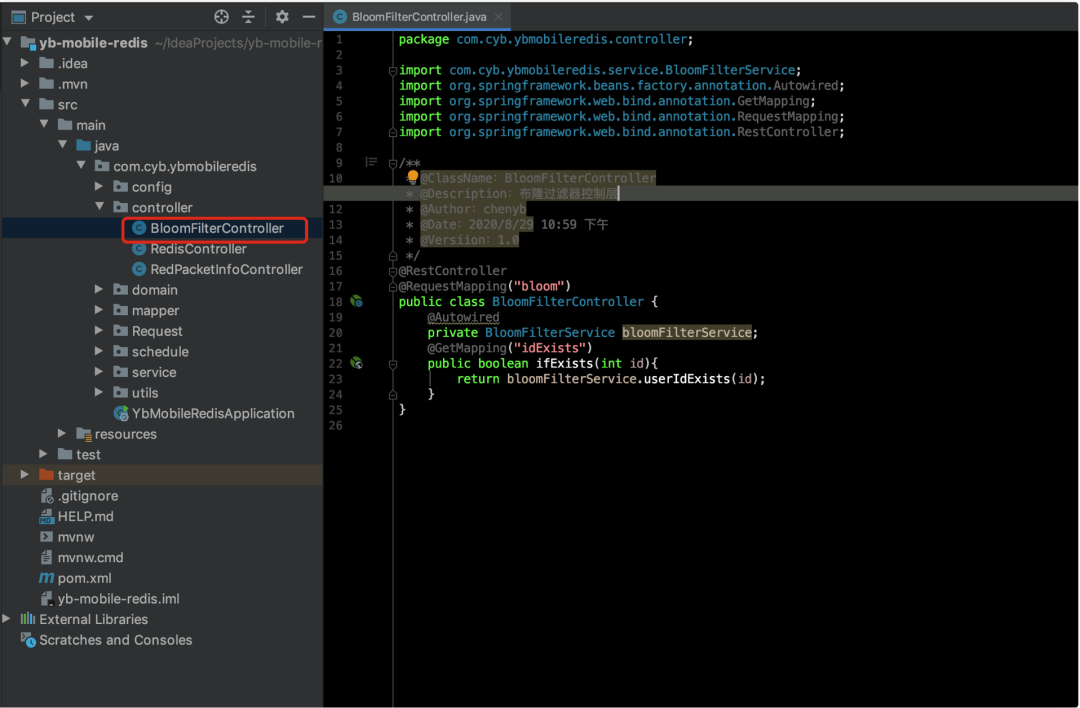
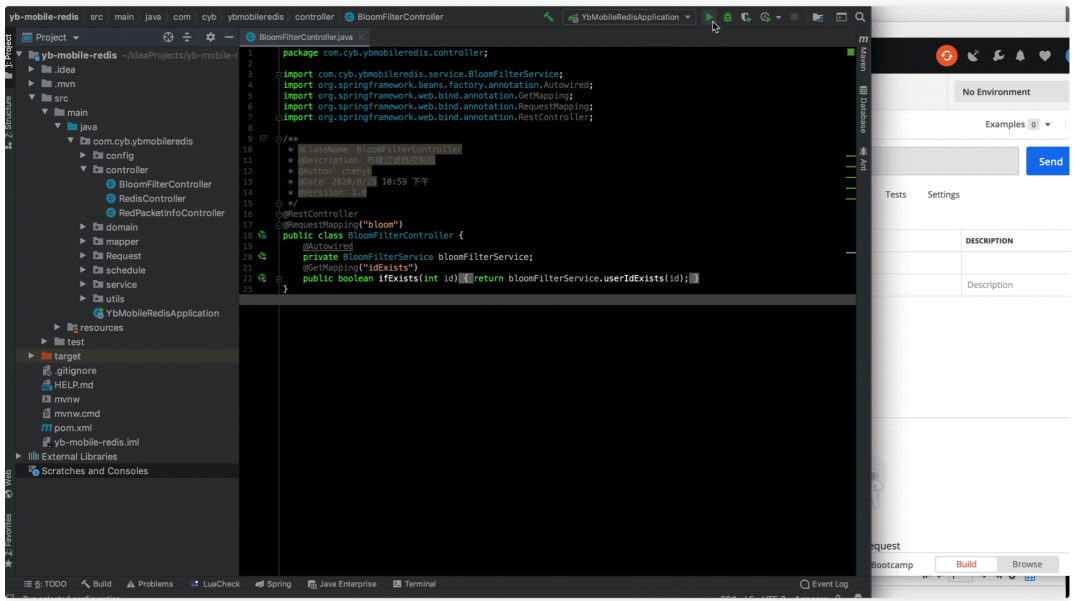
测试
缺点
内存级别产部 重启即失效 本地内存无法用在分布式场景 不支持大数据量存储
Redis布隆过滤器
优点
可扩展性 Bloom 过滤器 不存在重启即失效或定时任务维护的成本
缺点
需要网络IO,性能比基于内存的过滤器低
布隆过滤器安装
「下载」
github:https://github.com/RedisBloom/RedisBloom
链接: https://pan.baidu.com/s/16DlKLm8WGFzGkoPpy8y4Aw 密码: 25w1
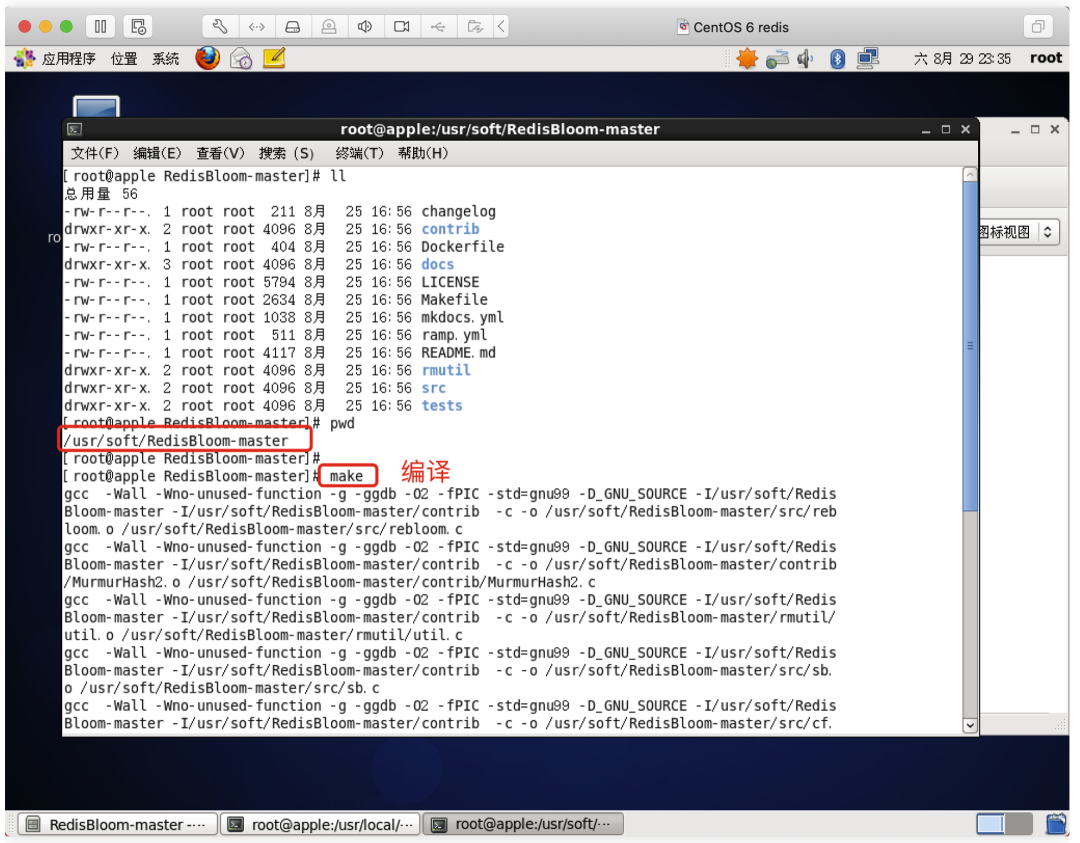
「编译」
make
「将 Rebloom 加载到 Redis 中」
先把 Redis 给停掉!!!在 redis.conf 里面添加一行命令->加载模块
loadmodule /usr/soft/RedisBloom-2.2.4/redisbloom.so

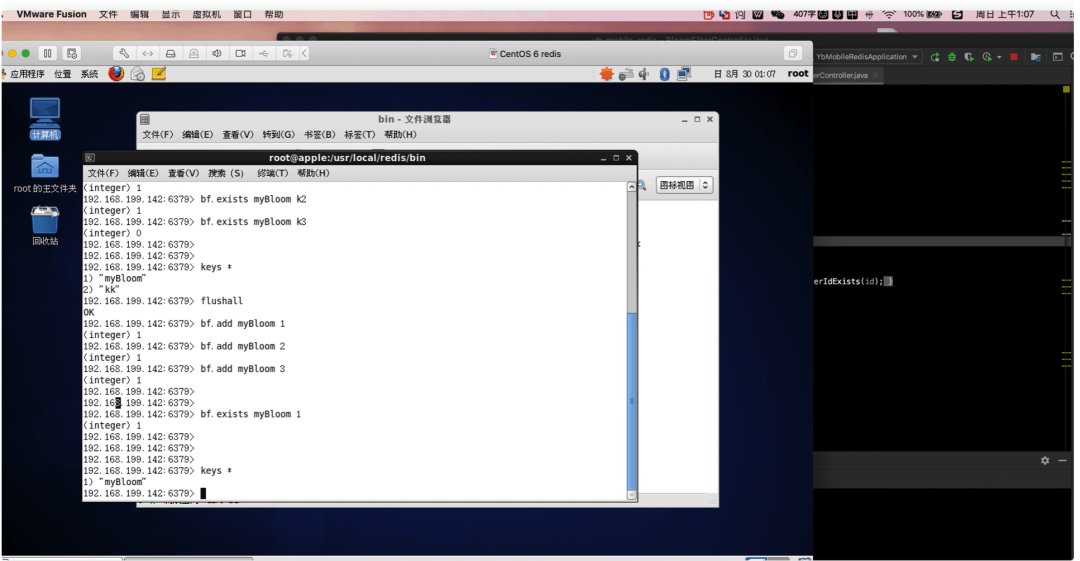
「测试布隆过滤器」
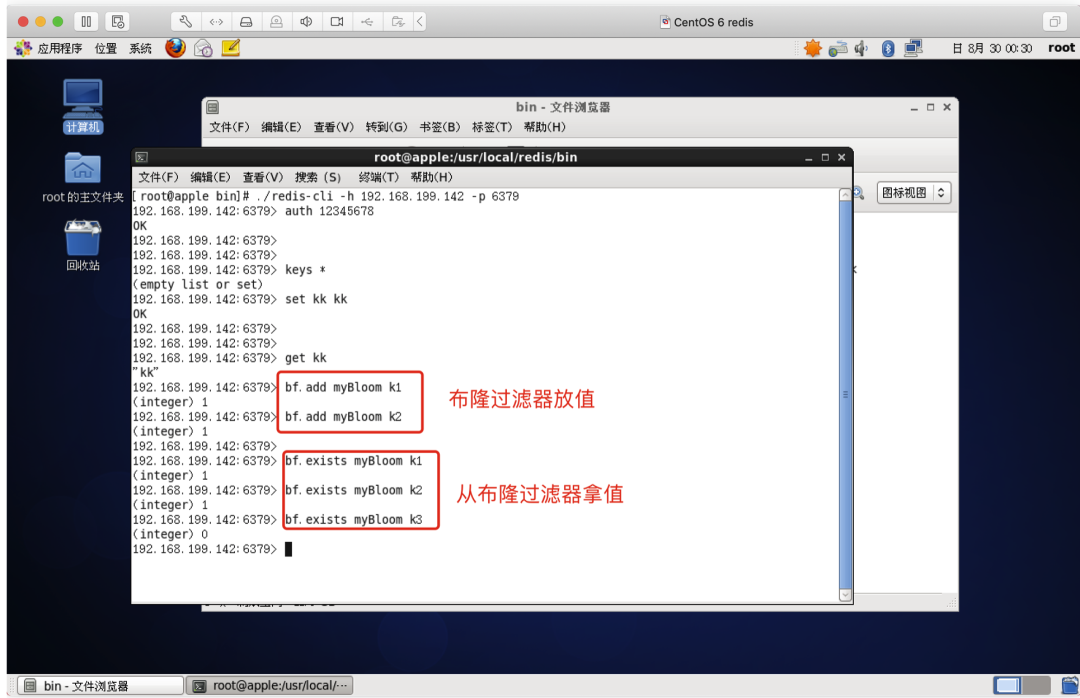
SpringBoot 整合 Redis 布隆过滤器
编写两个lua脚本
添加数据到指定名称的布隆过滤器 从指定名称的布隆过滤器获取key是否存在的脚本
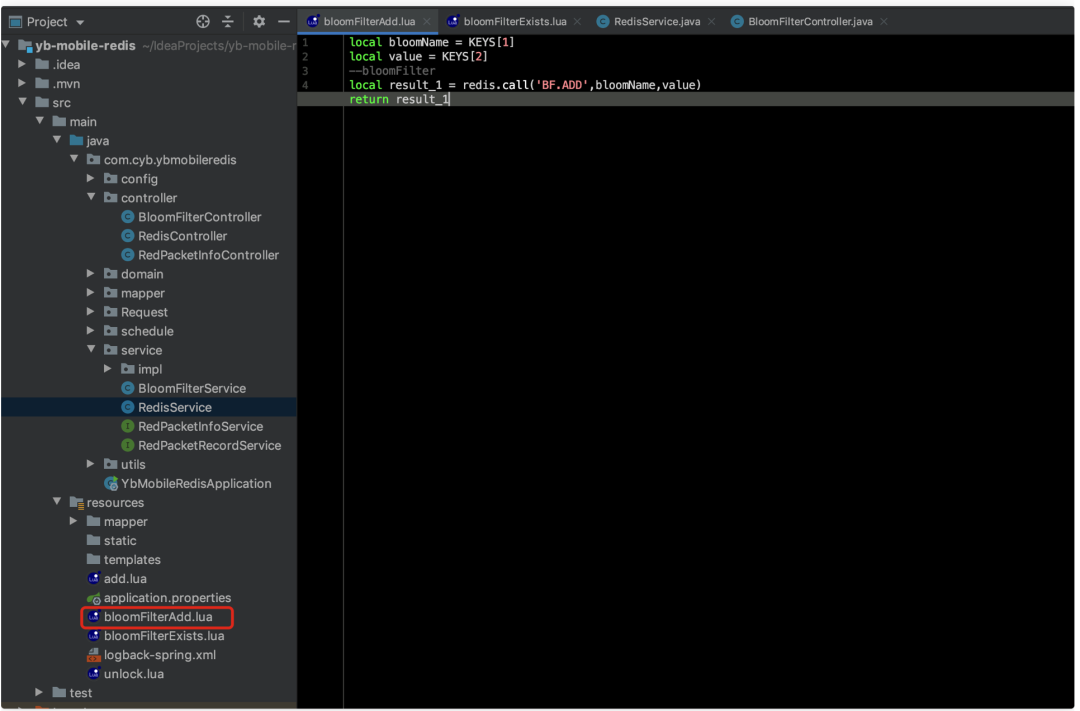
local bloomName = KEYS[1]
local value = KEYS[2]
--bloomFilter
local result_1 = redis.call('BF.ADD',bloomName,value)
return result_1
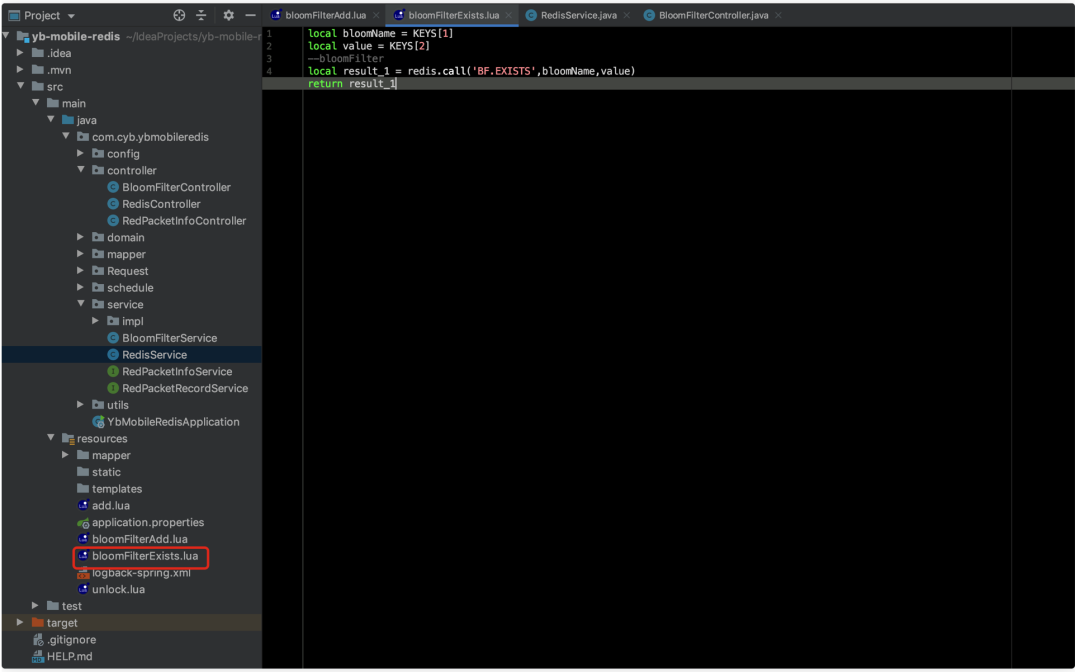
local bloomName = KEYS[1]
local value = KEYS[2]
--bloomFilter
local result_1 = redis.call('BF.EXISTS',bloomName,value)
return result_1
在 RedisService.java 中添加 2 个方法
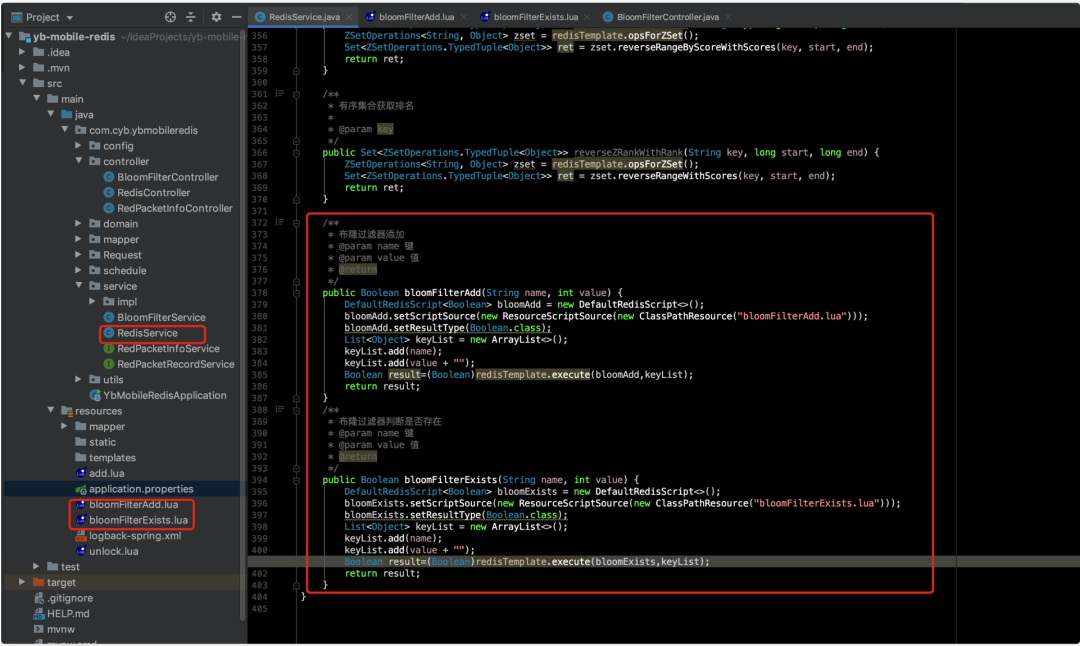
验证
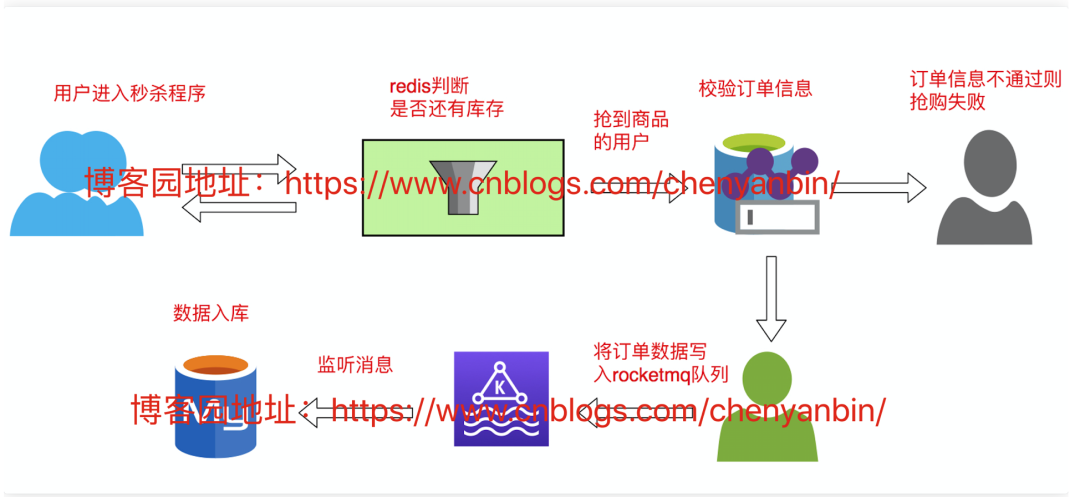
秒杀
秒杀业务流程图
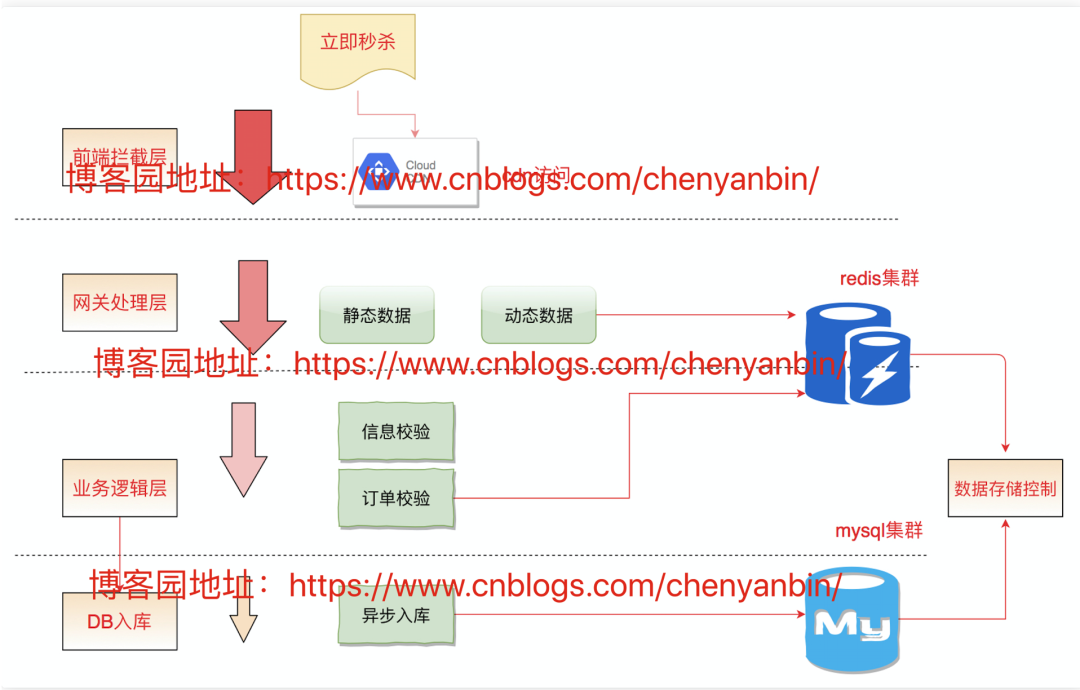
数据落地存储方案
通过分布式redis减库存 DB存最终订单信息数据
API性能调优
性能瓶颈在高并发秒杀 技术难题在于超卖问题
实现步骤
提前将秒杀数据缓存到 redis
set skuId_start_1 0_1554045087 --秒杀标识
set skuId_access_1 12000 --允许抢购数
set skuId_count_1 0 --抢购计数
set skuId_booked_1 0 --真实秒杀数
秒杀开始前,skuId_start为0,代表活动未开始 当skuId_start改为1时,活动开始,开始秒杀叭 当接受下单数达到sku_count*1.2后,继续拦截所有请求,商品剩余数量为0(为啥接受抢购数为1万2呢,看业务流程图,涉及到“校验订单信息”,一般设置的值要比总数多一点,多多少自己定)
利用 Redis 缓存加速增库存数
"skuId_booked":10000 //从0开始累加,秒杀的个数只能加到1万
将用户订单数据写入 MQ(异步方式)。
另外一台服务器监听 mq,将订单信息写入到 DB。
好了,以上就是完整的开发步骤,下面我们开始编写代码
代码实战
网关浏览拦截层
1、先判断秒杀是否已经开始
2、利用 Redis 缓存 incr 拦截流量
用 incr 方法原子加 通过原子加帕努单当前 skuId_access 是否达到最大值
订单信息校验层
1、校验当前用户是否已经买过这个商品
需要存储用户的uid 存数据库效率太低 存Redis value方式数据太大 存布隆过滤器性能高且数据量小(推荐)
2、校验通过直接返回抢购成功
开发lua脚本实现库存扣除
1、库存扣除成功,获取当前最新库存
2、如果库存大于0,即马上进行库存扣除,并且访问抢购成功给用户
3、考虑原子性问题
保证原子性的方式,采用 lua 脚本 采用lua脚本方式保证原子性带来缺点,性能有所下降 不保证原子性缺点,放入请求量可能大于预期 当前扣除库存场景必须保证原子性,否则会导致超卖
4、返回抢购结果
抢购成功 库存没了,抢购失败
控制层

Service 层
布隆过滤器

初始化redis缓存
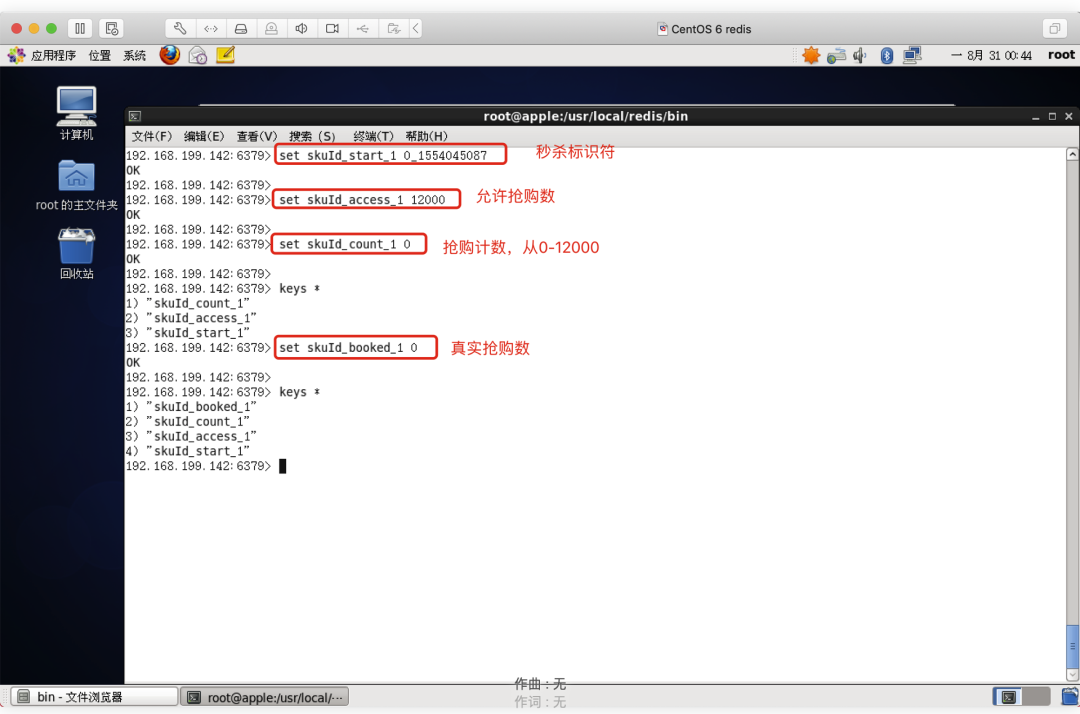
set skuId_start_1 0_1554045087 --秒杀标识
set skuId_access_1 12000 --允许抢购数
set skuId_count_1 0 --抢购计数
set skuId_booked_1 0 --真实秒杀数
秒杀验证
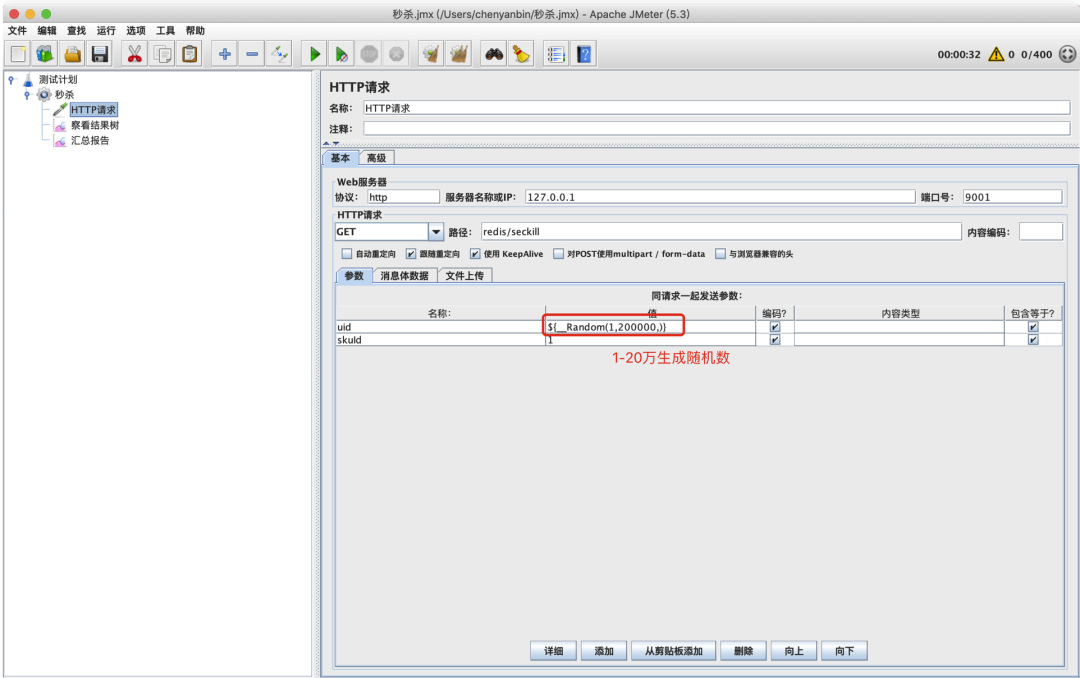
jmeter 配置
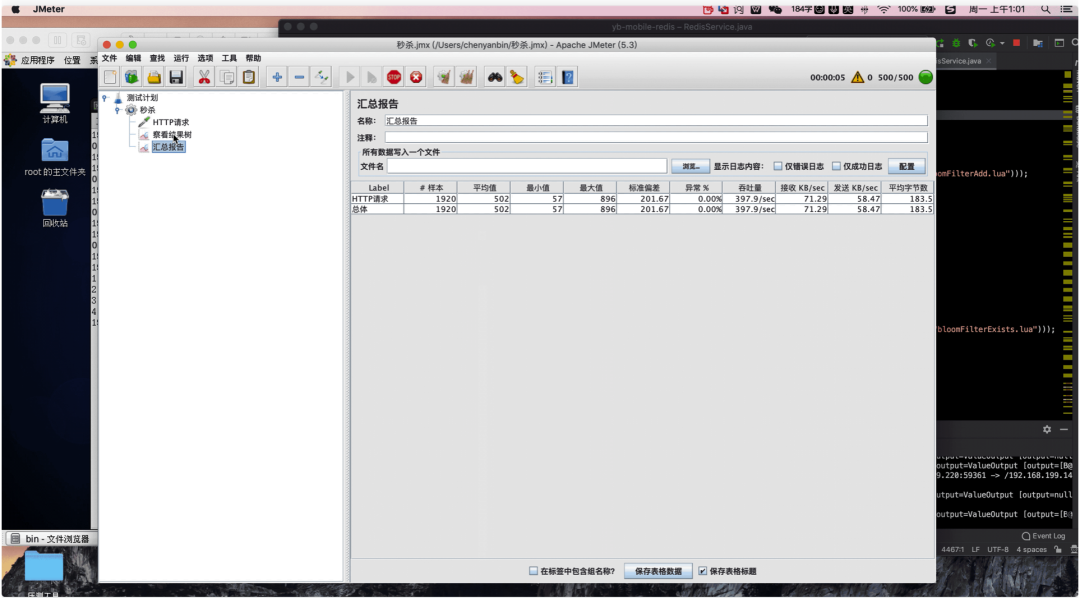
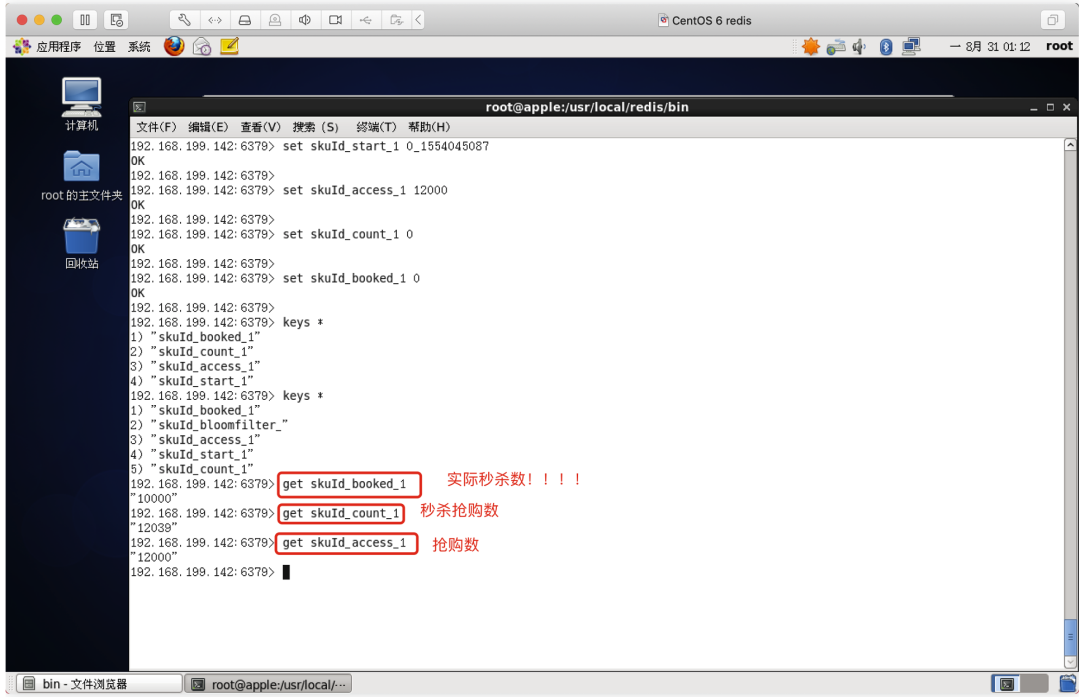
压测秒杀验证原子性

项目下载
链接: https://pan.baidu.com/s/1hZUPRAljkqO05fYluqJBhQ 密码: 1iwr
尾声
演示的时候,我使用的 Redis 单机的,吞吐量不是很大,感兴趣的,可以自己搭建个 Redis 主从复制+哨兵+集群,然后再测试。
最近比较忙,没时间完善微信抢红包秒杀的原子性。下面那个完整案例抢库存的,亲自使用 Jmeter 压测几次,是原子性的,可以拿来借鉴,感兴趣的同学,可以借鉴下面抢库存的代码,把微信抢红包的功能在完善下,我就不修改啦。
