
手把手教你用 nodejs 撸一个TCP长连接应用
作者 | 雪卒 (本文来源方凳雅集,经方凳雅集作者授权转载)
本文通过讨论TCP长连接的基本特性和原理,结合TCP应用层协议的设计给出一个基本的nodejs实现,供大家参考与探讨。
起航
最近在整理近一两年来自己写的一些nodejs模块,其中一个是用于编写TCP长连接应用的模块。目前它在线上已经稳定跑了1年多,由于底层是通用的,不包含任何上层逻辑,于是就开源出来了,供大家一起学习和交流。这篇文章就顺便写一写这方面的东西,算是个总结。开源地址为:https://github.com/luckydrq/tcp-net。
连接的“长短”
你可能有疑问,为什么要做TCP长连接应用?我觉得是看场景的,在回答这个问题之前,先解释下什么是“长连接”,什么是“短连接”。以常见的HTTP请求为例,客户端(浏览器)向服务端(网站)请求一个脚本资源,服务端响应HTTP状态码200,并把脚本内容发送给客户端。在这个过程中,客户端和服务端之间会建立一条HTTP连接通道,用于传输数据。我们知道,HTTP是基于TCP实现的7层网络协议,因此严格来说在传输层建立的是一条TCP连接通道。那么这条连接究竟是“长”的还是“短”的呢?
在HTTP/1.0时代,是“短”的。服务端在发送完脚本内容后,就会断开连接,同时告诉客户端“我已经断开了,你也断开吧”(4次挥手从略)。这个过程通常是短暂的,等到下次再请求其他资源的时候,客户端和服务端之间还需要经历建立连接、传输数据、断开连接的过程,如此往复。通俗的表示如下:

在HTTP/1.1时代,通常是“长”的。为什么说“通常”,因为这和一个HTTP Response Header密切相关:Connection: Keep-Alive。当有这个Header的时候,连接就是“长”的,反之就是“短”的。现代的HTTP服务器,在实现HTTP/1.1协议时,通常会在响应里带上这个Header,默认连接是“长”的。那么“长连接”的表现是什么?服务端在发送完脚本内容后,(通过这个Header)告诉客户端“我会等待一段时间,如果在这段时间内你没有请求,我就会断开连接;如果这段时间里你又请求了其他资源,我可以响应你”。假设服务端的等待时间是30s(可自定义设置),那么大致会出现以下情况:

在HTTP/2.0时代,是“长”的。这和HTTP/1.1时代有啥区别呢?HTTP/1.1的长连接模式,称为“请求-响应”模式,也就是只能一个文件一个文件地请求。举个例子,一个HTML页面上需要加载example.com下style.css和index.js,客户端会先请求style.css,等服务端把style.css的内容返回,假设耗时为100ms。接着客户端请求index.js,等index.js的内容返回,假设耗时为150ms。因此,整个请求过程的总耗时为250ms(100+150)。HTTP/2的长连接模式,称为“多请求-多响应”模式,客户端把要请求的清单先一股脑儿地发给服务端,服务端在发送这些文件内容的时候,会对文件进行切块,一块一块地随机返回。注意文件块返回顺序是完全随机的,不会等到把一个文件的块全部返回才返回下一个文件的块,这是保证传输效率高的重要原因。假设带宽无限大,那么整个过程的耗时为150ms(取100与150之间数值大的那个)。这个特性在HTTP/2中称为多路复用(Multiplexing),关于这个特性大家可以进一步了解:
https://stackoverflow.com/questions/36517829/what-does-multiplexing-mean-in-http-2/36519379#36519379
我们用大白话描述下整个过程:

使用场景
上一节我们讨论了连接的长短以及长连接在使用上的不同模式。相比短连接,长连接的优点是显而易见的,比如它省去了多次建立连接的成本,保证了传输速度(TCP慢启动),提升了性能也节约了资源。但同时它也是一把双刃剑,使用不慎会有很大问题,为什么这么说,我先挖个坑,后面再填。那么长连接用在哪些场景呢?你的第一反应可能是利用WebSocket实现网页聊天室,这是一个很常见的场景。我工作的场景是发生在服务器之间的长连接通信,我们做了个实时日志服务,浏览器端也是利用WebSocket从服务端获取日志,但前端部分不是重点,重点是日志服务是怎么构建的,它的架构大致如下:
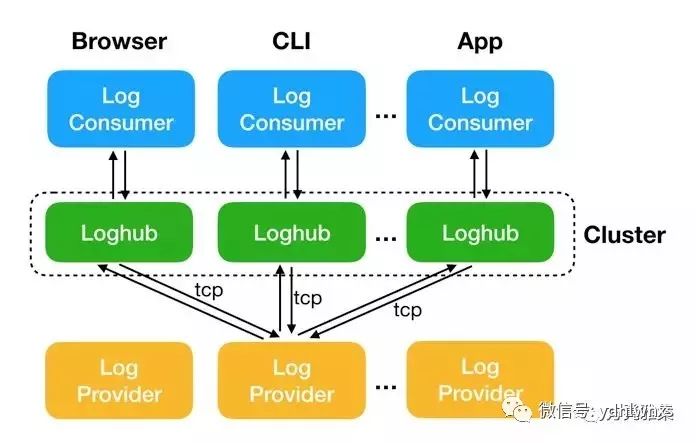
上图的Loghub就是实时日志服务,它的主要作用是存储日志(缓存和持久化)并提供实时访问。日志来源于各种各样的系统(平台),这些生产日志的系统称为Log Provider,通过TCP长连接把日志数据传输给Loghub。最终我们需要在各个端上查看这些日志,这是一个消费行为,这些端称为Log Consumer。好了,细节就不多作讨论了,但是要注意一下日志的两个特点:异步、分阶段输出。异步比较好理解,比如生产者要记录某一个任务的日志,但是这个任务本身就是异步的,要等完成后才知道是否成功,因此日志的生产也得是异步的。分阶段输出,指的是在执行任务的过程中,经过一些关键节点需要记录下信息(方便跟踪进度和排查问题),这些信息会立刻生产出来,不会等到任务结束。在这个场景里,长连接方案是非常合适的,因为不需要频繁地创建和销毁连接,对于提升系统吞吐量有很大的帮助。
心跳
那么长连接究竟有没有缺点?当然有,不然前面那个坑岂不是白埋了:D。我们知道一个TCP连接可以用四元组来表示:源IP(source_ip)、源端口(source_port)、对端IP(destination_ip)、对端端口(destination_port)。在很久很久以前,TCP连接都是长的。它工作的景象是这样的:
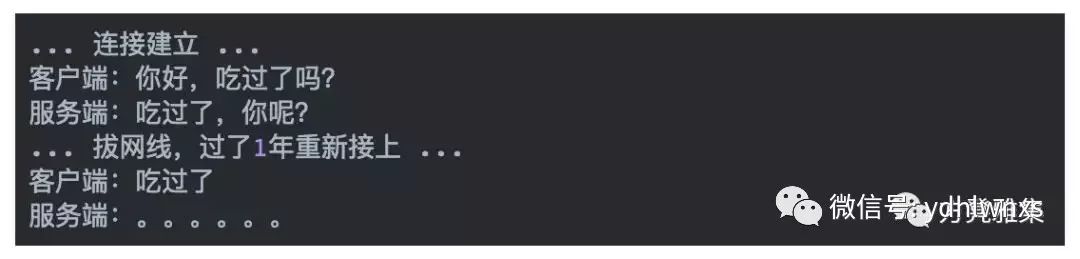
客户端与服务端一旦成功建立连接,只要没有显式断开,连接就一直存在。这是很有问题的,从上面夸张的例子中可以看到,1年之后才得到客户端的回复是很崩溃的,并且在这1年里连接信息一直保存在服务端,占用着服务器资源。如果所有的客户端都这样做,过不了多久服务器就会因资源耗尽而宕机,这是不能容忍的。为了解决这个问题,我们需要一种“心跳机制”,即每过一段时间,通信一方向另一方发送一个特殊格式的数据包(心跳包),接收方在收到这个包后,立刻发送一个响应包作为“回应”,表示“我还活着,请不要断开连接”。如果发送方没有收到回应,则启动一个后续策略,这个策略是可定制的,比如,尝试一定次数仍然失败后断开连接,或者直接断开连接。
TCP keep-alive
其实,操作系统考虑到了这一点,它为TCP连接提供了一种系统层面的心跳机制。以Linux系统为例,提供了以下的参数:

tcp_keepalive_time:心跳检测周期,默认2小时。
tcp_keepalive_intvl:当探测没有被确认时,重新发送探测的频度,默认75秒。
tcp_keepalive_probes:在连接失效之前,连续发送探针的个数,默认9个。
注意,对于不同的操作系统,参数名和默认值会有区别,但作用大同小异
应用层心跳
虽然有了TCP keep-alive机制,但现代的应用程序通常不会依赖它。首先,它属于全局设置,修改它会影响系统里的所有程序,这样就不够灵活。其次,在实际测试的过程中,它似乎并不总是能生效,也许和系统底层的实现有很大关系。因此,通常应用程序会自行实现心跳机制,一般被称为应用层心跳。应用层心跳包是由程序自己约定,只适用该程序的数据包(与其他程序不兼容)。例如:客户端发送hello,服务端回应world,这样就完成了一次心跳检测。不过在设计心跳包的时候,应该尽可能用一些特殊字符,避免与业务数据包混淆。

粘包
我第一次看到“粘包”这个词还是在一个nodejs爱好者群里,它指的是发送方发送的数据包和接收方接收的数据包并不是一一对应的。例如,发送方发了两个包:hello、world。接收方可能一次性收到helloworld,也可能是陆续收到hell、oworld,亦或是hel、lowo、rld。我们看一个示例代码:
客户端:
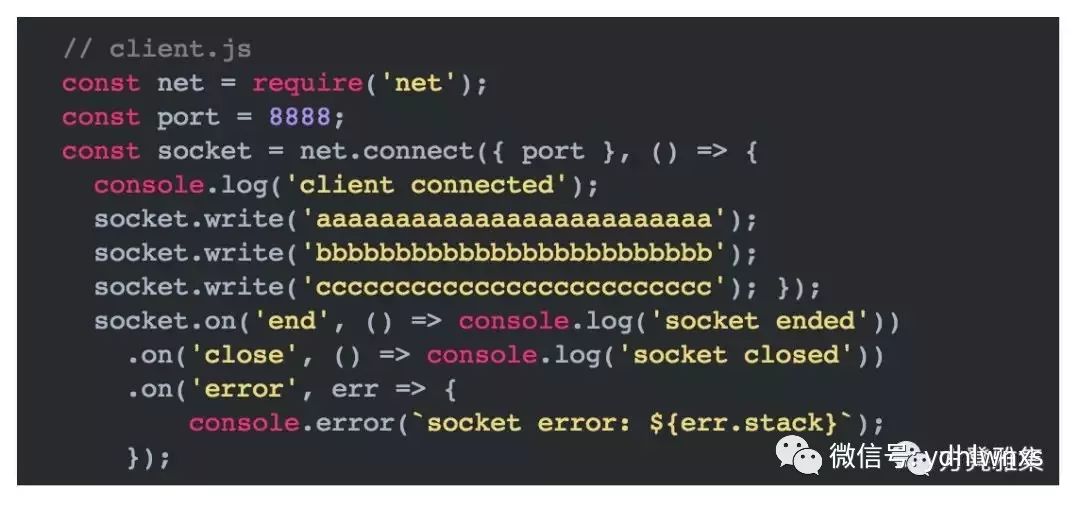
服务端:
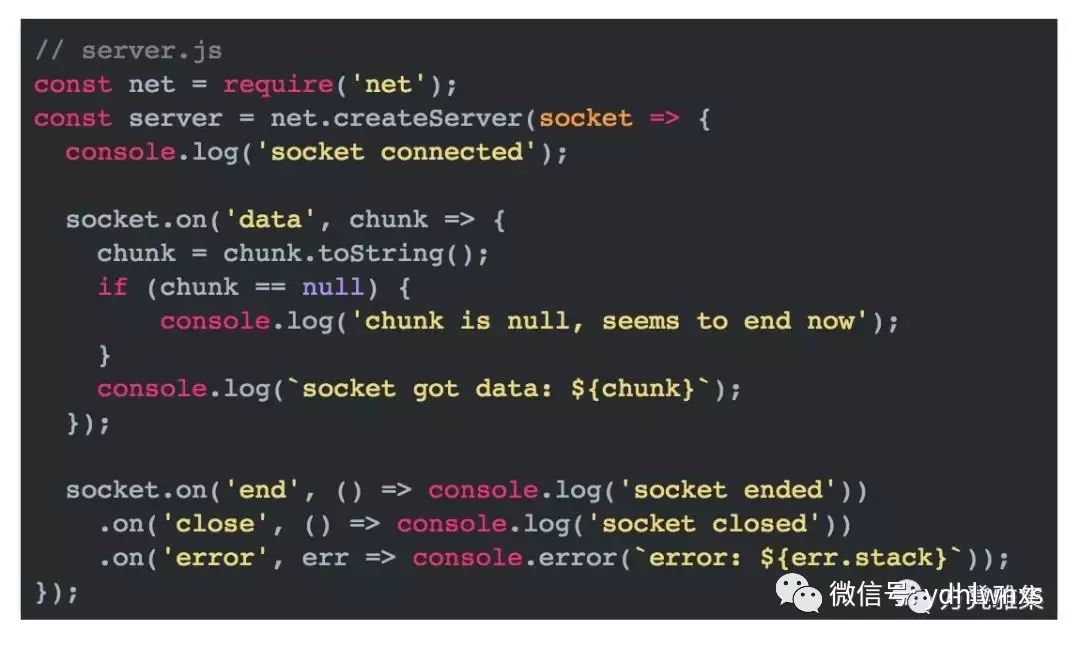
运行程序,查看终端打印的结果:

“粘包”不是Bug,是TCP天然的行为。我们认为发生了“粘包”,是因为我们把数据根据业务属性进行了“分包”。对于TCP来说,这些“包”都是二进制的0和1而已。当发送端调用socket.write(data)时,系统并不会立刻把这个包发送出去,而是把它放到一个发送缓冲区里。具体需要发送多少数据(字节),什么时候发送,是由TCP拥塞控制策略来决定的。同样,在接收端有一个接收缓冲区,收到的数据会先放到接收缓冲区里,然后程序再从这里读取一部分数据(字节)进行消费。TCP本身是流式协议,这和nodejs的Stream模块设计是极其类似的,不知isaacs大神当时设计Stream的时候是否参考了TCP的设计:D。
通信模型
前面在介绍不同版本的HTTP协议时其实有讨论过,大致可以分为请求-响应、多请求-多响应、无响应三种。多请求-多响应可以看做是请求-响应的升级版(就像HTTP/2是HTTP/1.x的升级版),而无响应模型指的是接收方无需对发送方进行回应,发送方也不在乎接收方是否收到消息,这也有一定的实际场景。下面我们就通过简单的图示再展示下这三种模型的优劣和异同:
请求-响应

多请求-多响应
无响应

包协议
OK,接下来我们就要对程序的数据包的格式制定一个规范,所有的数据包都要遵循这个规范,我称之为“包协议”。注意,这里的“所有数据包”不光指发送方发出的包,还包括接收方收到的包。这个协议需要能够适配我们的实际业务场景需要,同时也要解决一些通用问题,例如:心跳、粘包及通信模型等。协议不是唯一的,怎么设计完全由设计者自由发挥,只要能满足需求即可。下面我给出自己设计的协议,供大家参考。
一个最简的包协议:

reqType:请求类型,表示是请求还是响应,0 - 请求,1 - 响应,2 - 请求无需响应。
packetId:包id。
packetType:包类型,0 - 普通包,1 - 心跳包。
customBody:自定义包体。
包头
可以看到,包头(Header)部分有3个字段(共6个byte)。我们来仔细看一下这3个字段的含义。
reqType
请求类型。它标识一个数据包是请求还是响应,亦或是无需响应的请求(比较少见)。这个字段是必要的,因为TCP连接通道是全双工的,连接的两端在不停地收、发请求。在某个时间点,一端发出了一个数据包,它既可能是一个请求,也可能是一个(对之前收到的请求的)响应。有了reqType字段,接收方就明确了这个包的意图,并进行了后续处理。
packetId
包id。我们给每个包都赋予一个id,咋一听起来也没毛病,但id是必要的吗?没有id会怎么样?答案是肯定的。考虑一个场景:连接的一方向另一方连续发送了3个请求,过了一会儿它收到对方发过来的一个数据包,根据reqType识别了它是一个响应包,那么问题来了,这个包对之前发出的哪个请求的响应呢?总不能随机选一个吧,否则系统就出bug了。这个时候packetId就起到了关键作用。假如,发出的3个请求包分别带上了1、2、3的id,而收到的响应包的id为2,那么就表示这是对第2个请求进行的响应。这个问题本质上是多请求-多响应模型必须要解决的问题,因为响应的顺序不一定和请求的顺序是一一对应的。回到一开始对packetId的解释:“我们给每个包都赋予一个id”,其实这句话是有瑕疵的,因为在上面的例子中,响应包的id和请求包的id是一样的(2)。通常情况下,我们只需要把每个请求附上id,然后把这个id与响应包进行关联即可。所以,packetId这个单词其实也可以改成reqId(请求id)。
packetType
包类型。有一些内置的功能我们希望在这个库里面封装掉,比如心跳。应用层心跳包和其他类型的数据包没有区别,是应用层自行给出设计并实现的。也就是说,心跳包也有请求和响应,一方收到一个心跳请求后,要返回一个响应告知对方“我还活着”,这个很好理解。因此,需要一个标志把业务请求和心跳请求区分开来,如果发现是心跳请求,则进行心跳响应。心跳的处理逻辑在我开源的这个包里面统一封装了,也就是说使用方不需要关注心跳逻辑,如下:
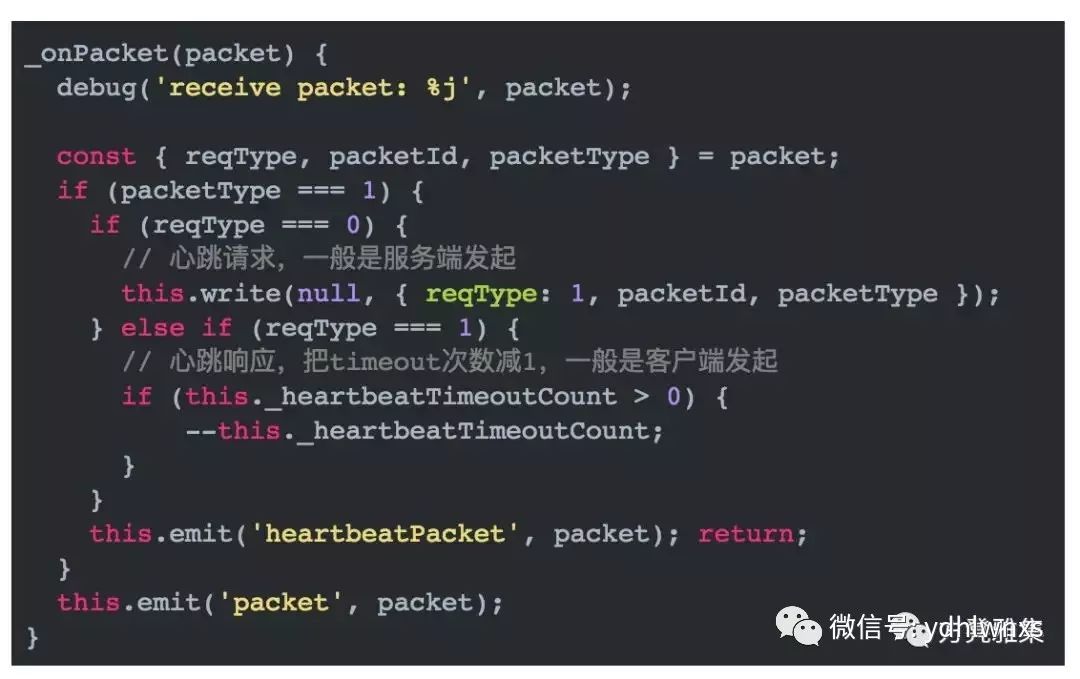
另外,除了心跳包你还可以继续定义其他类型的包。
包体
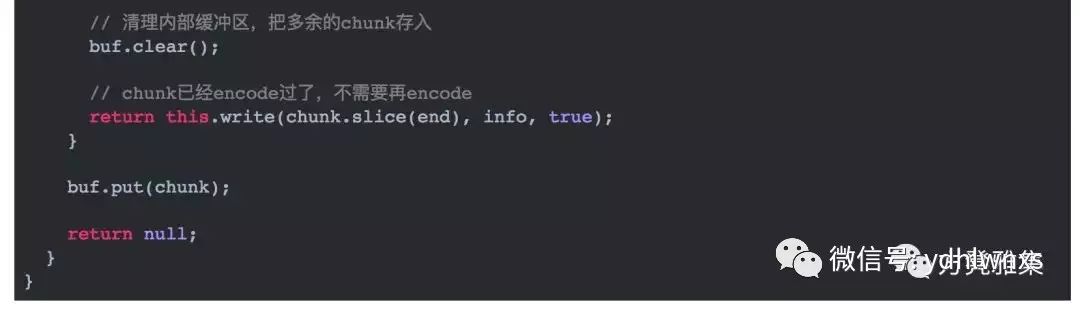
包体(Body)就是我们发送这个包的具体内容(数据),和HTTP POST payload一样,体积可大可小,没有统一的规范。还记得我们前面讲过粘包的问题吗?理想状态下,我们希望接收方一个包一个包地接收,这里的“包”就是按照我们制定的协议封装好的。但是现实很残酷,由于粘包是TCP的“天性”,实际收到的数据包可能是残缺不全的,也可能粘连了其他的包数据。另一方面,我们需要知道包体有多大,这样才能找到边界。解决这个问题,我们把包体进一步进行拆分,方式有很多,下面介绍库里实现的两种,实际场景中任选一种即可:
Length-Based Protocol
Length-Based Protocol也是个很简单的协议,如下:
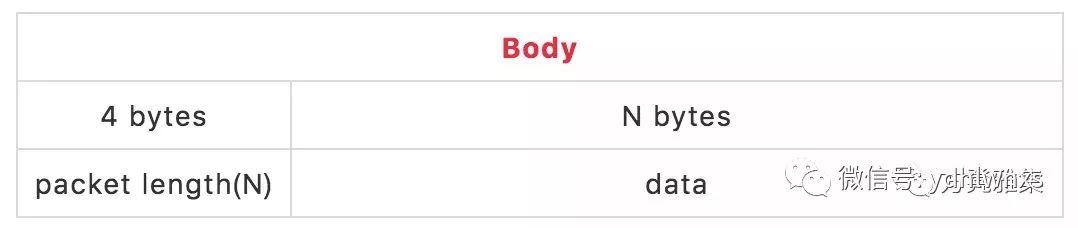
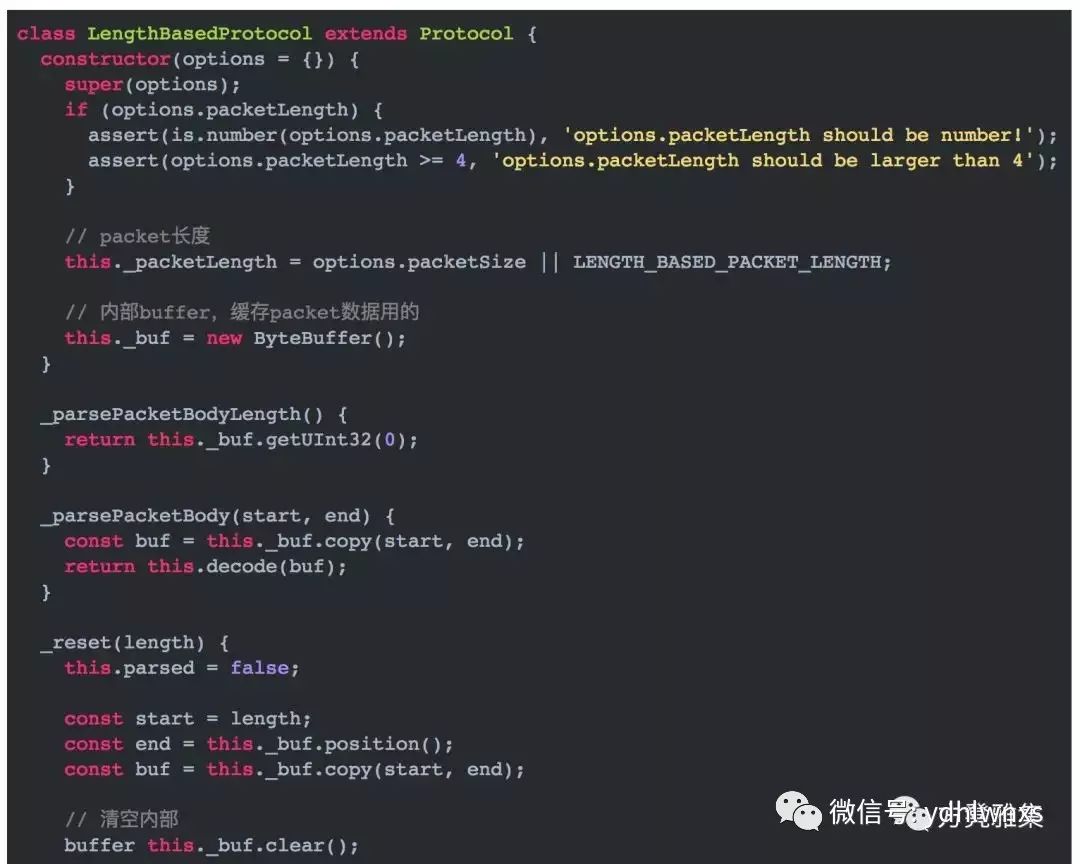
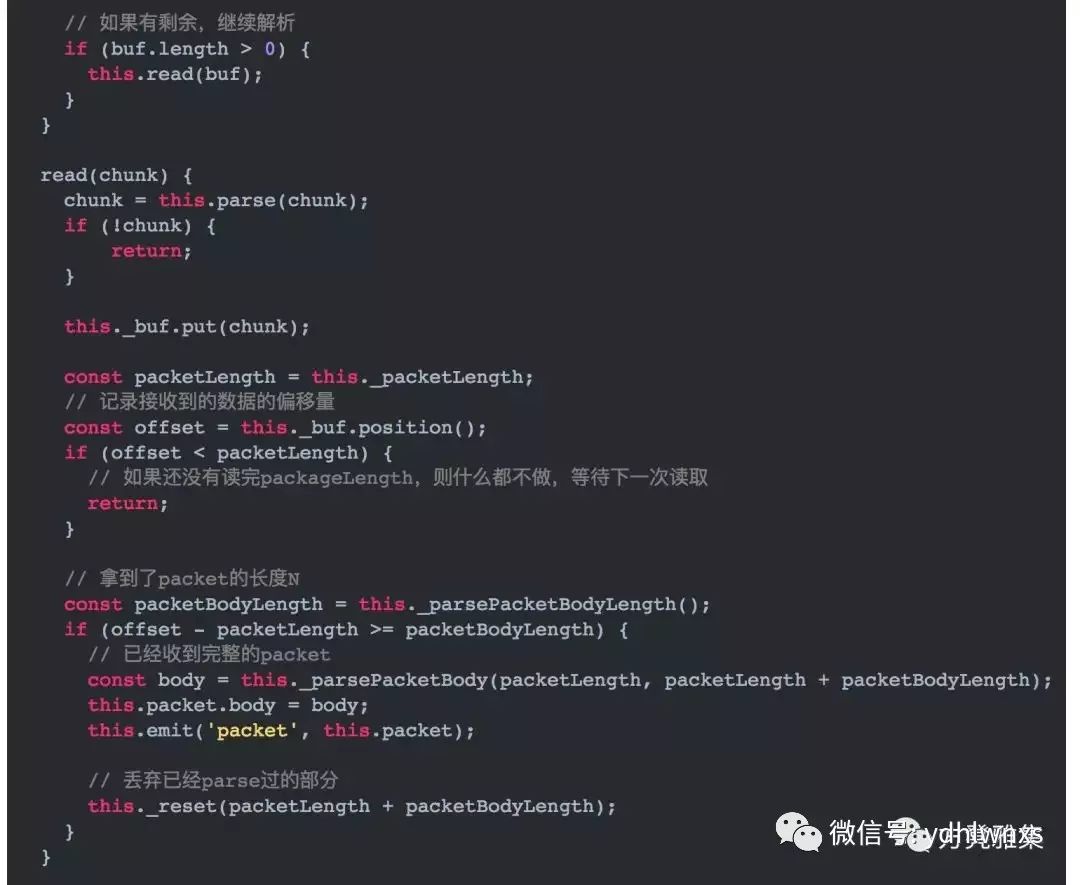
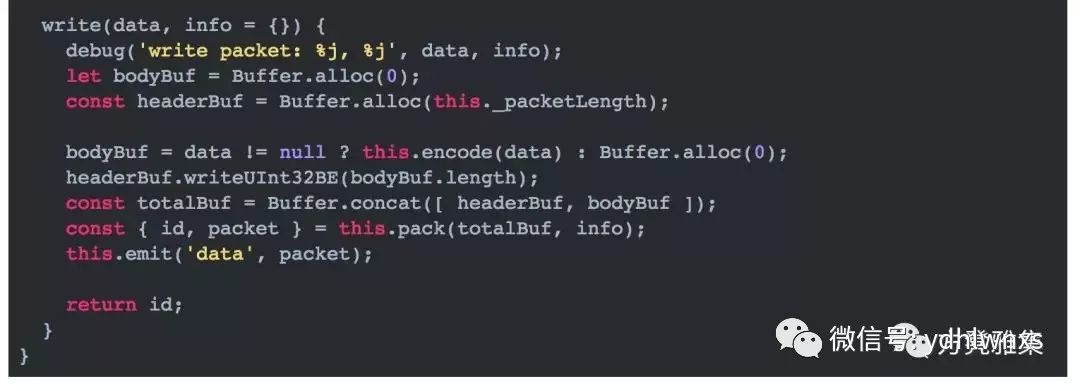
因为每个包的包体大小都不一样,所以我们在包体的前4个byte设置了一个字段,用来标识包体的大小,记为N,然后再往后读N个byte,即可拿到包体的全部数据。以下是它的实现:
Line-Based Protocol
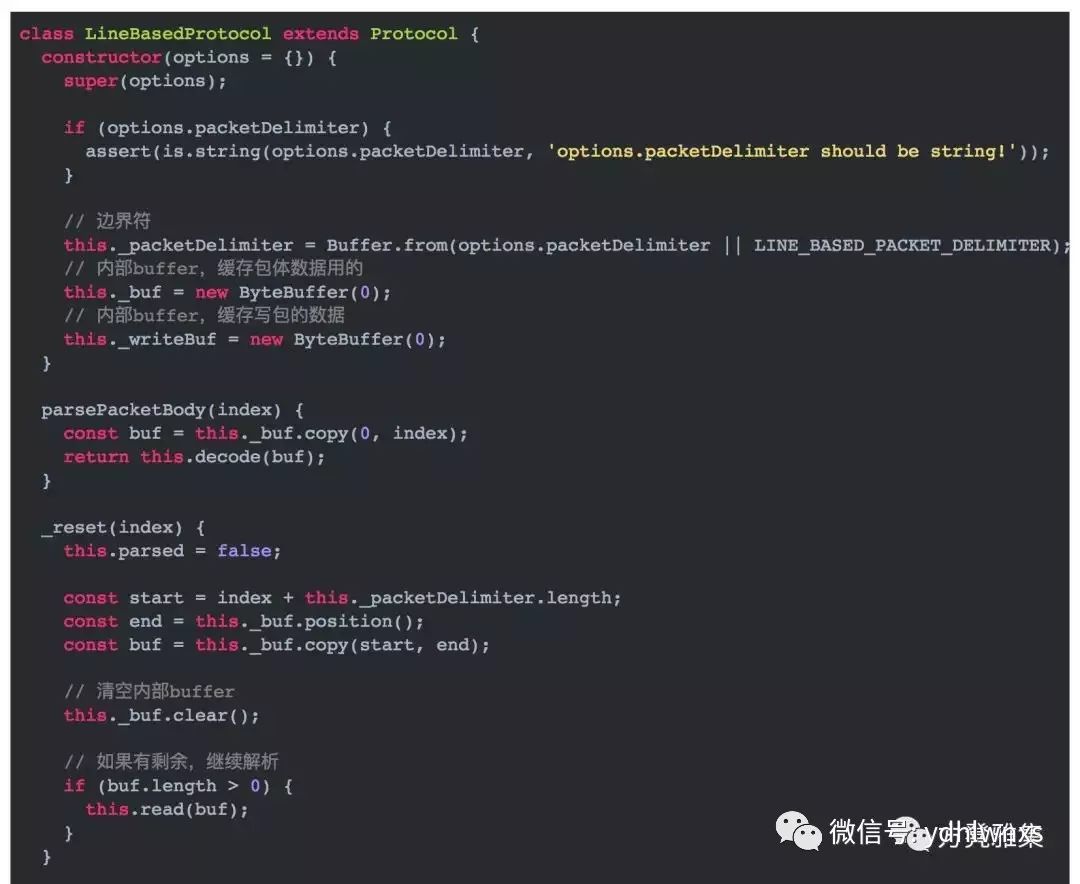
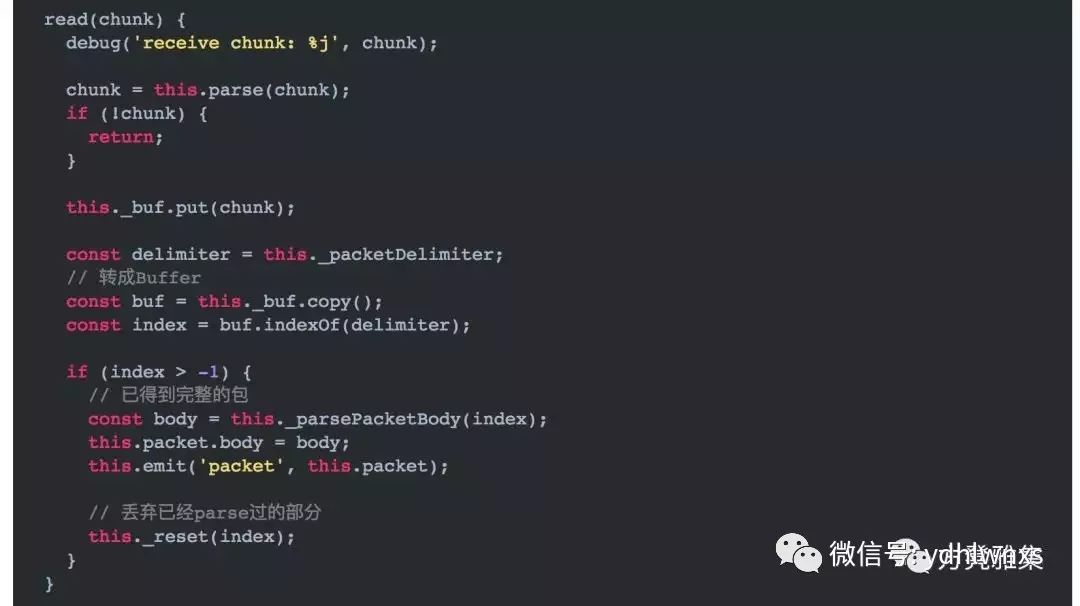
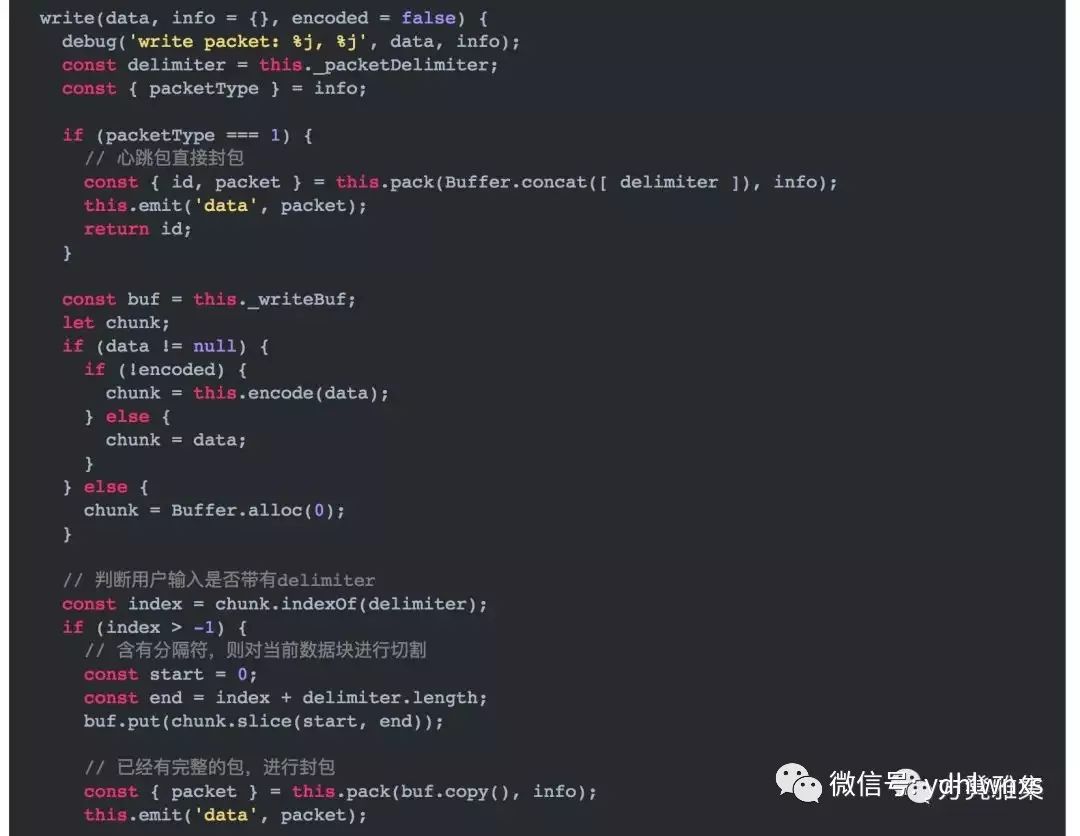
Line-Based Protocol其实就是HTTP协议的包体规范,这种方式它不会告诉你包体有多大,你可以一直读下去直到读到一个边界符(\r\n)为止。

边界符你可以任意指定,只要保证在你的程序中它不会出现在正常的包体里面就可以。它的实现如下:
编解码器
编解码器是编码器(Encoder)和解码器(Decoder)的统称,也叫作TransCoder。我们知道,TCP底层发送的是二进制数据(0/1),但是在应用层,我们可能发送的是一个数字、一个字符串或者是一个对象,发送端需要把它们转换成二进制数据。同样的,接收端也需要把二进制数据恢复成数字、字符串、对象,用于应用层使用。这个时候就涉及到序列化和反序列化的操作。在这里,编码器的任务是做序列化,解码器的任务是做反序列化。下面我们来实现一个简单的编解码器,名字听着很高大上,其实只需要实现encode和decode两个方法就可以了。
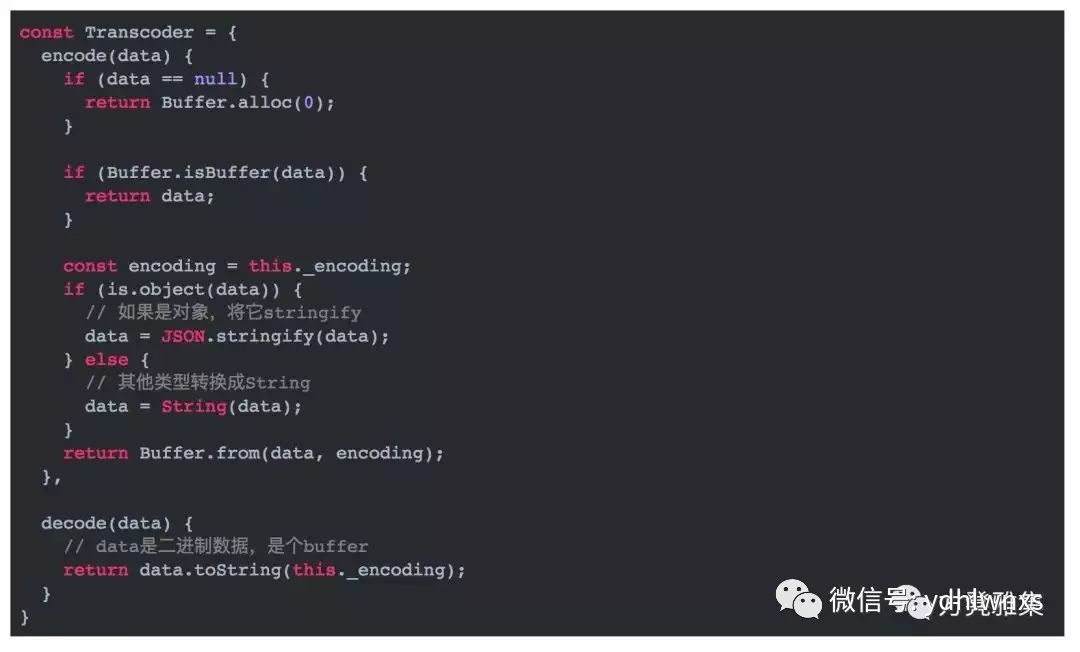
社区有很多专业的序列化和反序列化的协议,例如:hessian、protobuf、thrift,它们在编解码的时候还会对数据进行压缩,以优化网络带宽。这里需要注意的是,编解码器只对包体进行处理,而不是针对整个包协议的,否则整个协议的解析就乱套了。
总结
这篇文章主要是针对TCP长连接的基本知识进行了简单的整理。本文讨论的包协议等实现思路都沉淀在这里,希望对大家有所帮助,欢迎一起探讨。TCP协议博大精深,由于笔者能力有限,还有很多地方没有说清楚及cover到的,请见谅。谢谢。