
Prompt范式,真香
卷友们好,我是rumor。
之前我学习Prompt范式的源起PET后就鸽了很久,相信卷友们已经把Prompt的论文都追完了,把我远远地落在了后面。周末我不甘被卷,奋起直追,连刷三篇paper,希望能赶上大家学习的步伐。

Prefix-tuning- Optimizing continuous prompts for generation
P-tuning-GPT Understands, Too
Prompt-tuning-The Power of Scale for Parameter-Efficient Prompt Tuning
自动化Prompt
Prompt范式的第一个阶段,就是在输入上加Prompt文本,再对输出进行映射。但这种方式怎么想都不是很优雅,无法避免人工的介入。即使有方法可以批量挖掘,但也有些复杂(有这个功夫能标不少高质量语料),而且模型毕竟是黑盒,对离散文本输入的鲁棒性很差:

怎么办呢?离散的不行,那就连续的呗
用固定的token代替prompt,拼接上文本输入,当成特殊的embedding输入,这样在训练时也可以对prompt进行优化,就减小了prompt挖掘、选择的成本。
如何加入Prompt
前面的想法非常单纯,但实际操作起来还是需要些技巧的。
Prefix-tuning
Prefix-tuning是做生成任务,它根据不同的模型结构定义了不同的Prompt拼接方式,在GPT类的自回归模型上采用[PREFIX, x, y],在T5类的encoder-decoder模型上采用[PREFIX, x, PREFIX', y]:
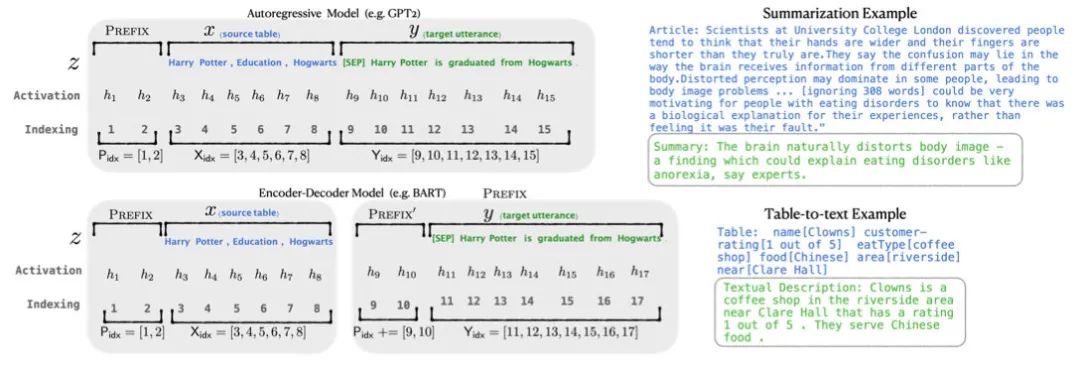
值得注意的还有三个改动:
把预训练大模型freeze住,因为大模型参数量大,精调起来效率低,毕竟prompt的出现就是要解决大模型少样本的适配 作者发现直接优化Prompt参数不太稳定,加了个更大的MLP,训练完只保存MLP变换后的参数就行了 实验证实只加到embedding上的效果不太好,因此作者在每层都加了prompt的参数,改动较大
P-tuning
P-tuning是稍晚些的工作,主要针对NLU任务。对于BERT类双向语言模型采用模版(P1, x, P2, [MASK], P3),对于单向语言模型采用(P1, x, P2, [MASK]):
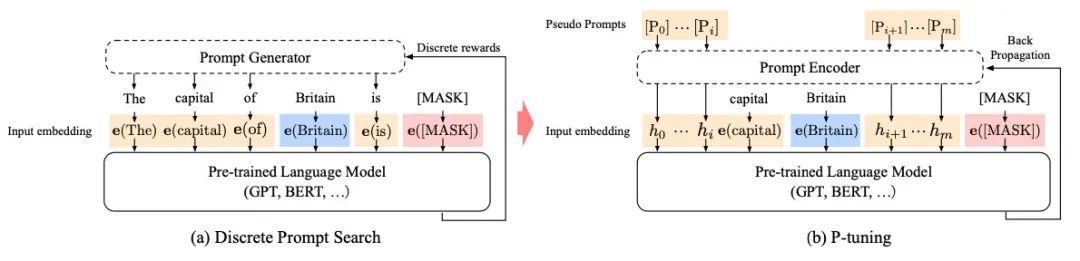
同时加了两个改动:
考虑到预训练模型本身的embedding就比较离散了(随机初始化+梯度传回来小,最后只是小范围优化),同时prompt本身也是互相关联的,所以作者先用LSTM对prompt进行编码 在输入上加入了anchor,比如对于RTE任务,加上一个问号变成 [PRE][prompt tokens][HYP]?[prompt tokens][MASK]后效果会更好
P-tuning的效果很好,之前的Prompt模型都是主打小样本效果,而P-tuning终于在整个数据集上超越了精调的效果:

虽然P-tuning效果好,但实验对比也有些问题,它没有freeze大模型,而是一起精调的,相当于引入了额外的输入特征,而平时我们在输入加个词法句法信息也会有提升,所以不能完全肯定这个效果是prompt带来的。同时随着模型尺寸增大,精调也会更难。
Prompt-tuning
Prompt-tuning就更加有信服力一些,纯凭Prompt撬动了大模型。
Prompt-tuning给每个任务定义了自己的Prompt,拼接到数据上作为输入,同时freeze预训练模型进行训练,在没有加额外层的情况下,可以看到随着模型体积增大效果越来越好,最终追上了精调的效果:
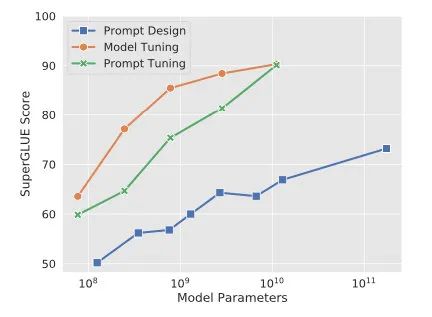
同时,Prompt-tuning还提出了Prompt-ensembling,也就是在一个batch里同时训练同一个任务的不同prompt,这样相当于训练了不同「模型」,比模型集成的成本小多了。
其他Trick
除了怎么加Prompt之外,Prompt向量的初始化和长度也有所讲究。
Prompt初始化
Prefix-tuning采用了任务相关的文字进行初始化,而Prompt-tuning发现在NLU任务上用label文本初始化效果更好。不过随着模型尺寸的提升,这种gap也会最终消失。

Prompt长度
从Prompt-tuning的实验可以看到,长度在10-20时的表现已经不错了,同时这个gap也会随着模型尺寸的提升而减小。

总结
要说上次看PET时我对Prompt范式还是将信将疑,看完这几篇之后就比较认可了。尤其是Prompt-tuning的一系列实验,确实证明了增加少量可调节参数可以很好地运用大模型,并且模型能力越强,所需要的prompt人工调参就越少。
这种参数化Prompt的方法除了避免「人工」智能外,还有一方面就是省去了Y的映射。因为在精调的过程中,模型的输出就被拿捏死了,而且Prompt-tuning还用label初始化Prompt,更加让模型知道要输出啥。
Finally,终于追上了前沿,大家的鬼点子可真多啊。


「赶紧Prompt一下我的业务」