
五年磨一剑:李飞飞AI100报告第二弹,提出14大AI机遇与挑战

新智元报道
新智元报道
来源:Stanford
编辑:好困 David
【新智元导读】时隔5年,由斯坦福大学教授李飞飞主导的「AI100」研究报告终于推出了第二期,对过去五年来人工智能领域最重要的14个大问题进行了回顾和分析。此外,该报告据称未来要一直做下去,直到100年。


问题1:每个问题后面的图片即代表该问题下影响力最大的技术进步
问题2:AI领域最重要的进展是什么?

基础技术
语言处理
计算机视觉和图像处理
游戏
机器人
出行
健康
金融
推荐系统
问题3:最令人激动的重大挑战问题都有哪些?
图灵测试
机器人世界杯

国际数学奥林匹克竞赛 (IMO)
问题4:我们在理解人类智力的关键奥秘方面取得了多大进展?
集体智力
认知神经科学
计算模型
The State of the Art
问题5:更通用的人工智能前景如何?
基于Transformer的自监督学习

持续和多任务学习
让深度强化学习更加通用化
常识问题
问题6:公众对人工智能的情绪如何演变,我们应如何告知/教育公众?

问题7:为确保AI应用是负责任的,政府做了些什么?
问题8:在开发和部署人工智能技术以及研究人工智能的影响方面,学术界和工业界的作用应该是什么?
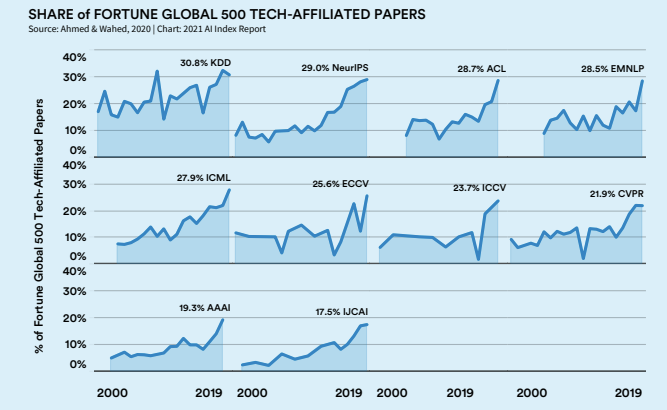
问题9:当前AI最具前途的机遇是什么?

问题10:AI最紧迫的危险是什么?

问题11:AI对社会经济关系造成的影响有哪些?
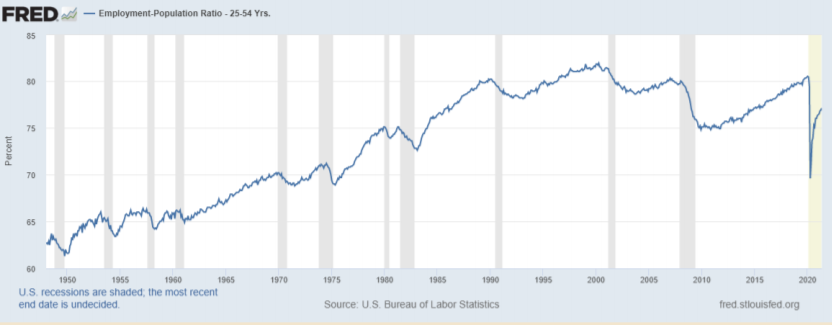
问题12:从长远来看,「建立我们的思维方式」作为一种工程策略是否有效?
除了以上常设的12个问题以外,本次报告还加入了两个来自workshop的问题。
1. 在高风险的公共背景下,如何进行人工智能驱动的预测,决策者在实施和治理中必须考虑哪些社会、组织和实际因素?——「实践中的预测」
2. 在使用人工智能为有需要的人提供身体和情感关怀方面,最紧迫的挑战和重大机遇是什么?—— 「编码关怀」
参考资料:
https://ai100.stanford.edu/sites/g/files/sbiybj18871/files/media/file/AI100Report_MT_10.pdf

评论