
丁鹏:多角度回顾因果推断的模型方法

来源:集智俱乐部 本文约23000字,建议阅读20+分钟 本文整理自丁鹏老师的8篇短文,从多角度回顾了因果推断的各种模型方法。

[ 导读 ] 推断因果关系,是人类思想史与科学史上的重要主题。现代因果推断的研究,始于约尔-辛普森悖论,经由鲁宾因果模型、随机试验等改进,到朱力亚·珀尔的因果革命,如今因果科学与人工智能的结合正掀起热潮。
目录
1. 因果推断简介之一:
从 Yule-Simpson’s Paradox 讲起
在国内的时候,向别人介绍自己是研究因果推断(causal inference)的,多半的反应是:什么?统计还能研究因果?这确实是一个问题:统计研究因果,能、还是不能?直接给出回答,比较冒险;如果有可能,我需要花一些篇幅来阐述这个问题。
目前市面上能够买到的相关教科书仅有 2011 年图灵奖得主 Judea Pearl 的 Causality: Models, Reasoning, and Inference。Harvard 的统计学家 Donald Rubin 和 计量经济学家 Guido Imbens 合著的教科书历时多年仍尚未完成;Harvard 的流行病学家 James Robins 和他的同事也在写一本因果推断的教科书,本书目前只完成了第一部分,还未出版。我本人学习因果推断是从 Judea Pearl 的教科书入手的,不过这本书晦涩难懂,实在不适合作为入门的教科书。Donald Rubin 对 Judea Pearl 提出的因果图模型(causal diagram)非常反对,他的教科书中杜绝使用因果图模型。我本人虽然脑中习惯用图模型进行思考,但是还是更偏好 Donald Rubin 的风格,因为这对于入门者,可能更容易。不过这一节,先从一个例子出发,不引进新的统计符号和概念。

天才的高斯在研究天文学时,首次引进了最大似然和最小二乘的思想,并且导出了正态分布(或称高斯分布)。其中最大似然有些争议,比如 Arthur Dempster 教授说,其实高斯那里的似然,有贝叶斯或者信仰推断(fiducial inference)的成分。高斯那里的 “统计” 是关于 “误差” 的理论,因为他研究的对象是 “物理模型” 加“随机误差”。大约在 100 多年前,Francis Galton 研究了父母身高和子女身高的 “关系”,提出了“(向均值)回归” 的概念。众所周知,他用的是线性回归模型。此时的模型不再是严格意义的“物理模型”,而是“统计模型” — 用于刻画变量之间的关系,而不一定是物理机制。之后,Karl Pearson 提出了“相关系数”(correlation coefficient)。
后世研究的统计,大多是关于 “相关关系” 的理论。但是关于 “因果关系” 的统计理论,非常稀少。据 Judea Pearl 说,Karl Pearson 明确的反对用统计研究因果关系;有意思的是,后来因果推断为数不多的重要文章(如 Rosenbaum and Rubin 1983; Pearl 1995)都发表在由 Karl Pearson 创刊的 Biometrika 上。下面讲到的悖论,可以说是困扰统计的根本问题,我学习因果推断便是由此入门的。
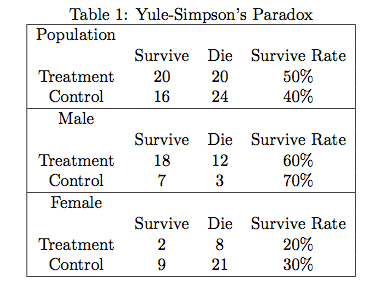
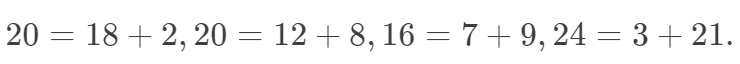
Table 1 中,处理组和对照组中,男性的比例分别为多少?这对悖论的产生有什么样的影响?反过来考虑处理的 “分配机制”(assignment mechanism),计算P(Treatment∣Male)和 P(Treatment∣Female)。 假如(X,Y,Z)服从三元正态分布,X和Y正相关,Y和Z正相关,那么X和Z是否正相关?(北京大学概率统计系 09 年《应用多元统计分析》期末第一题) 流行病学的教科书常常会讲各种悖论,比如混杂偏倚 (confounding bias)和入院率偏倚(Berkson’s bias)等,本质上是否与因果推断有关?
计量经济学中的 “内生性”(endogeneity)怎么定义?它和 Yule-Simpson 悖论有什么联系?
2. 因果推断简介之二:
Rubin Causal Model (RCM) 和随机化试验

设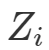 表示个体 i接受处理与否,处理取1,对照取0 (这部分的处理变量都讨论二值的,多值的可以做相应的推广);
表示个体 i接受处理与否,处理取1,对照取0 (这部分的处理变量都讨论二值的,多值的可以做相应的推广);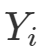 表示个体 i的结果变量。另外记
表示个体 i的结果变量。另外记 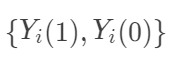 表示个体 i接受处理或者对照的潜在结果 (potential outcome),那么
表示个体 i接受处理或者对照的潜在结果 (potential outcome),那么 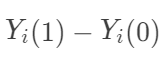 表示个体 i 接受治疗的个体因果作用。不幸的是,每个个体要么接受处理,要么接受对照,
表示个体 i 接受治疗的个体因果作用。不幸的是,每个个体要么接受处理,要么接受对照, 中必然缺失一半,个体的因果作用是不可识别的。观测的结果是
中必然缺失一半,个体的因果作用是不可识别的。观测的结果是  。但是,在Z做随机化的前提下,我们可以识别总体的平均因果作用 (Average Causal Effect; ACE):
。但是,在Z做随机化的前提下,我们可以识别总体的平均因果作用 (Average Causal Effect; ACE):

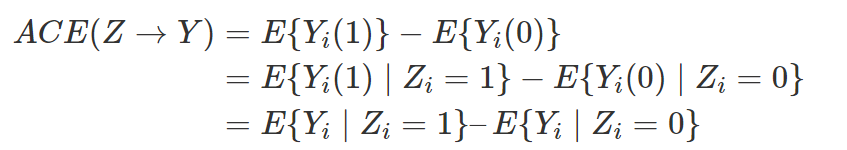
 可以由观测的数据估计出来。其中第一个等式用到了期望算子的线性性(非线性的算子导出的因果度量很难被识别!);第二个式子用到了随机化,即
可以由观测的数据估计出来。其中第一个等式用到了期望算子的线性性(非线性的算子导出的因果度量很难被识别!);第二个式子用到了随机化,即
 表示独立性。由此可见,随机化试验对于平均因果作用的识别起着至关重要的作用。
表示独立性。由此可见,随机化试验对于平均因果作用的识别起着至关重要的作用。
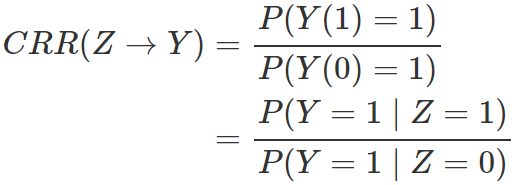
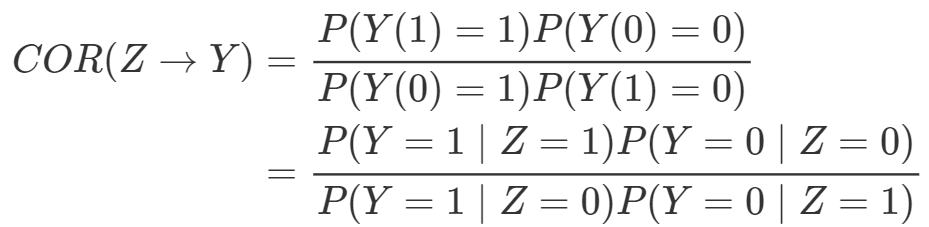

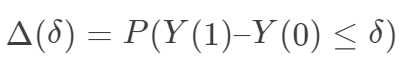
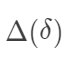 需要非常强的假定,通常不具有可行性。
需要非常强的假定,通常不具有可行性。“可识别性”(identifiability)在统计中是怎么定义的? 医学研究者通常认为,随机对照试验(randomized controlled experiment)是研究处理有效性的黄金标准,原因是什么呢?随机化试验为什么能够消除 Yule-Simpson 悖论?  在随机化下是可识别的。另外一个和它“对偶”的量是 Ju and Geng (2010) 提出的分布因果作用(distributional causal effect: DCE):
在随机化下是可识别的。另外一个和它“对偶”的量是 Ju and Geng (2010) 提出的分布因果作用(distributional causal effect: DCE):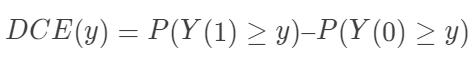 ,在随机化下也可以识别。
,在随机化下也可以识别。即使完全随机化,  也不可识别。也就是说,经济学家提出的具有“经济学意义”的量,很难用观测数据来估计。这种现象在实际中常常发生:关心实际问题的人向统计学家索取的太多,而他们提供的数据又很有限。
也不可识别。也就是说,经济学家提出的具有“经济学意义”的量,很难用观测数据来估计。这种现象在实际中常常发生:关心实际问题的人向统计学家索取的太多,而他们提供的数据又很有限。
3. 因果推断简介之三:
R. A. Fisher 和 J. Neyman 的分歧

R.A.Fisher
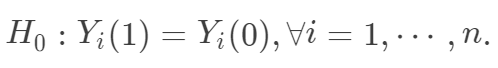 坦白地说,这个零假设是我见过的最奇怪的零假设,没有之一。现行的统计教科书中,讲到假设检验,零假设都是针对某些参数的,而 Fisher 的 sharp null 看起来却像是针对随机变量的。这里需要讲明白的是,当我们关心有限样本 (finite sample)的因果作用时,每个个体的潜在结果
坦白地说,这个零假设是我见过的最奇怪的零假设,没有之一。现行的统计教科书中,讲到假设检验,零假设都是针对某些参数的,而 Fisher 的 sharp null 看起来却像是针对随机变量的。这里需要讲明白的是,当我们关心有限样本 (finite sample)的因果作用时,每个个体的潜在结果  都是固定的,观测变量
都是固定的,观测变量 结果向量为
结果向量为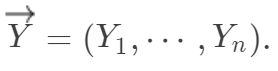
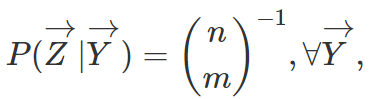
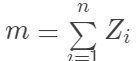 为处理组中的总数。这里的“条件期望”并不是说
为处理组中的总数。这里的“条件期望”并不是说 
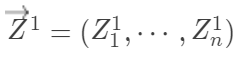 ,计算此时的检验统计量
,计算此时的检验统计量  ;如此重复多次n不大时,可以穷尽所有的置换,便可以模拟出统计量在零假设下的分布,计算出 p 值。
;如此重复多次n不大时,可以穷尽所有的置换,便可以模拟出统计量在零假设下的分布,计算出 p 值。
J. Neyman


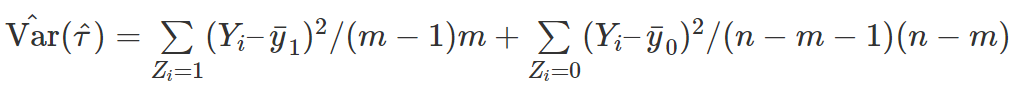
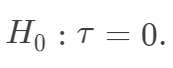
在 sharp null下,Neyman 方法下构造的 T 统计量,是否和 Fisher randomization test 构造的统计量相同?分布是否相同?
Fisher randomization test 中的统计量可以有其他选择,比如 Wilcoxon 秩和统计量等,推断的方法类似。
当Y是二值变量时,上面 Fisher 的方法就是教科书中的 Fisher exact test。在没有学习 potential outcome 这套语言之前,理解 Fisher exact test 是有些困难的。
证明
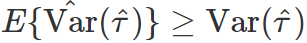 。
。假定n个个体是一个超总体(super-population)的随机样本,超总体的平均因果作用定义为
 那么 Neyman 的方法得到估计量是超总体平均因果作用的无偏估计,且方差的表达式是精确的;而 sharp null 在超总体的情形下不太适合。
那么 Neyman 的方法得到估计量是超总体平均因果作用的无偏估计,且方差的表达式是精确的;而 sharp null 在超总体的情形下不太适合。
观察性研究,可忽略性和倾向得分
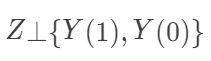 成立,这保证了平均因果作用
成立,这保证了平均因果作用  成立,因为只有在给定协变量X后,处理的分配机制才是完全随机化的。比如,男性和女性中,接受处理的比例不同,但是这个比例是事先给定的。
成立,因为只有在给定协变量X后,处理的分配机制才是完全随机化的。比如,男性和女性中,接受处理的比例不同,但是这个比例是事先给定的。
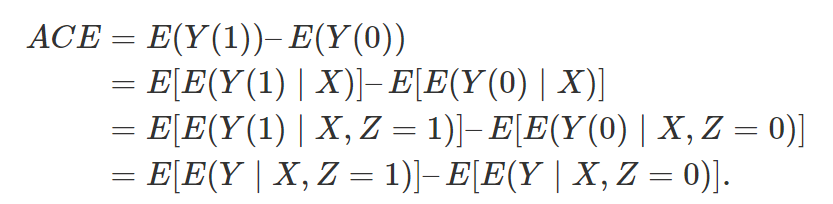
 成立,那么
成立,那么 就表示平均因果作用。线性模型比较容易实现,实际中人们比较倾向这种方法。但是他的问题是:(1)假定个体因果作用是常数;(2)对于处理和对照组之间的不平衡(unbalance)没有很好的检测,常常在对观测数据外推(extrapolation)。
就表示平均因果作用。线性模型比较容易实现,实际中人们比较倾向这种方法。但是他的问题是:(1)假定个体因果作用是常数;(2)对于处理和对照组之间的不平衡(unbalance)没有很好的检测,常常在对观测数据外推(extrapolation)。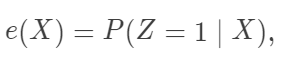 容易验证,在可忽略性下,它满足性质
容易验证,在可忽略性下,它满足性质 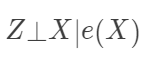 (在数据降维的文献中,称之为“充分降维”,sufficient dimension reduction) 和
(在数据降维的文献中,称之为“充分降维”,sufficient dimension reduction) 和 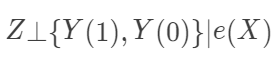 (给定倾向得分下的可忽略性)。根据前面的推导,显然有 ACE=E[E(Y|e(X), Z=1)]-E[E(Y|e(X),Z=0)] 。此时,倾向得分是一维的,我们可以根据它分层 (Rosenbaum 和 Rubin 建议分成 5 层),得到平均因果作用的估计。连续版本的分层,就是下面的加权估计:
(给定倾向得分下的可忽略性)。根据前面的推导,显然有 ACE=E[E(Y|e(X), Z=1)]-E[E(Y|e(X),Z=0)] 。此时,倾向得分是一维的,我们可以根据它分层 (Rosenbaum 和 Rubin 建议分成 5 层),得到平均因果作用的估计。连续版本的分层,就是下面的加权估计:
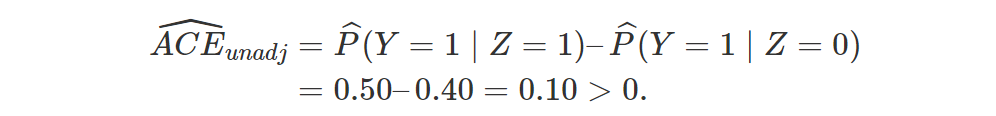
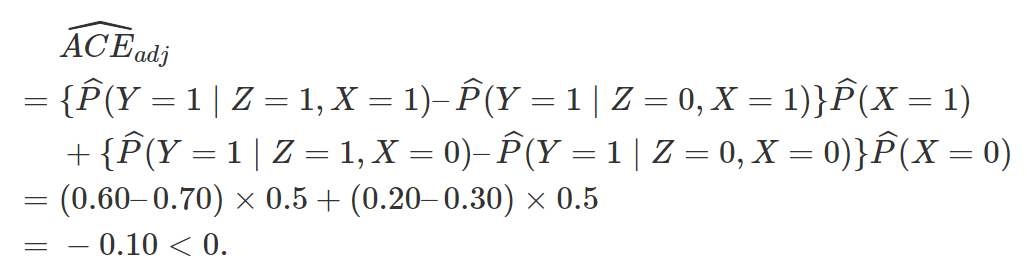 时, 第一个估计量是因果作用的相合估计;当 时,第二个估计量是因果作用的相合估计。根据实际问题的背景,我们应该选择哪个估计量呢?到此为止,回答这个问题有些似是而非(选择调整的估计量?),更进一步的回答,请听下回分解:因果图(causal diagram)。
时, 第一个估计量是因果作用的相合估计;当 时,第二个估计量是因果作用的相合估计。根据实际问题的背景,我们应该选择哪个估计量呢?到此为止,回答这个问题有些似是而非(选择调整的估计量?),更进一步的回答,请听下回分解:因果图(causal diagram)。如果X是二值的变量(如性别),那么匹配或者倾向的分都导致如下的估计量: 
这个公式在流行病学中非常基本,即根据混杂变量进行分层调整。在后面的介绍中将讲到,这个公式被 Judea Pearl 称为“后门准则”(backdoor criterion)。 倾向得分的加权形式, 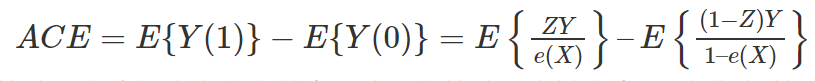
本质上是抽样调查中的 Horvitz-Thompson 估计。在流行病学的文献中,这样的估计量常被称为“逆概加权估计量”(inverse probability weighting estimator; IPWE)。 直观上,为什么估计的倾向得分会更好?想想偏差和方差的权衡(bias-variance tradeoff)。
5. 因果推断简介之五: 因果图 (Causal Diagram)

一、 有向无环图和 do 算子
 。这里用
。这里用  表示连续变量的密度函数和离散变量的概率函数。有两种观点看待一个 DAG:一是将其看成表示条件独立性的模型;二是将其看成一个数据生成机制。当然,本质上这两种观点是一样的。在第一种观点下,给定 DAG 中某个节点的“父亲”节点,它与其所有的非“后代”都独立。根据全概公式和条件独立性,DAG 中变量的联合分布可以有如下的递归分解:
表示连续变量的密度函数和离散变量的概率函数。有两种观点看待一个 DAG:一是将其看成表示条件独立性的模型;二是将其看成一个数据生成机制。当然,本质上这两种观点是一样的。在第一种观点下,给定 DAG 中某个节点的“父亲”节点,它与其所有的非“后代”都独立。根据全概公式和条件独立性,DAG 中变量的联合分布可以有如下的递归分解: 表示
表示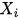 的“父亲”集合,即所有指向的节点集合。
的“父亲”集合,即所有指向的节点集合。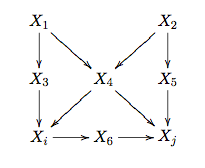
Figure 1: An Example of Causal Diagram
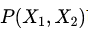 可以有两种分解
可以有两种分解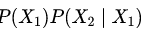 和
和 因此,我们从观测变量的联合分布,很难确定“原因”和“结果”。在下一节图模型结构的学习中,我们会看到,只有在一些假定和特殊情形下,我们可以从观测数据确定“原因”和“结果”。
因此,我们从观测变量的联合分布,很难确定“原因”和“结果”。在下一节图模型结构的学习中,我们会看到,只有在一些假定和特殊情形下,我们可以从观测数据确定“原因”和“结果”。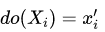 (也可以记做
(也可以记做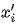 ),表示如下的操作:将
),表示如下的操作:将 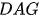 中指向
中指向 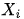 的有向边全部切断,且将 的取值固定为常数. 如此操作,得到的新的联合分布可以记做
的有向边全部切断,且将 的取值固定为常数. 如此操作,得到的新的联合分布可以记做 可以证明,干预后的联合分布为
可以证明,干预后的联合分布为 在绝大多数情况下是不同的。
在绝大多数情况下是不同的。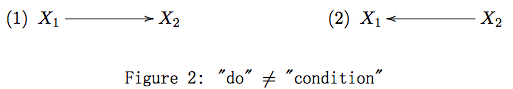
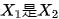 的“原因”,“条件”和“干预
的“原因”,“条件”和“干预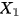 ,对应
,对应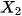 的分布相同。但是在 Figure 2 (2) 中,有. 由于的“结果”,“条件”(或者“给定”)“结果”,“原因”的分布不再等于他的边缘分布,但是人为的“干预”“结果,并不影响“原因的分布。
的分布相同。但是在 Figure 2 (2) 中,有. 由于的“结果”,“条件”(或者“给定”)“结果”,“原因”的分布不再等于他的边缘分布,但是人为的“干预”“结果,并不影响“原因的分布。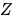 对于
对于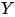 的平均因果作用定义为
的平均因果作用定义为“I must take the opportunity to acknowledge four colleagues who saw clarity shining through the do(x) operator before it gained popularity: Steffen Lauritzen, David Freedman, James Robins and Philip David. Phil showed special courage in pringting my paper in Biometrika, the journal founded by causality’s worst adversary – Karl Pearson.” (Pearl, 2000)
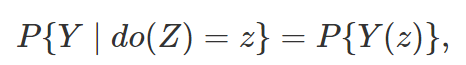
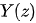 表示潜在结果。要想说明两个模型的等价性,可以将潜在结果嵌套在 DAG 所对应的数据生成机制之中,所有的潜在结果都由这个非参数结构方程模型产生:
表示潜在结果。要想说明两个模型的等价性,可以将潜在结果嵌套在 DAG 所对应的数据生成机制之中,所有的潜在结果都由这个非参数结构方程模型产生: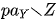 表
表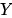 除的父亲节点。上面的方程表示:
除的父亲节点。上面的方程表示: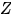 的值强制z时,DAG 系统所产生
的值强制z时,DAG 系统所产生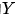 值。这个意义下,do 算子导出的结果,就是“潜在结果”。
值。这个意义下,do 算子导出的结果,就是“潜在结果”。二、 d分离,前门准则和后门准则
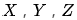 是 DAG 中不相交的节点集合,
是 DAG 中不相交的节点集合, 为一条连接
为一条连接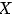 中某节点到
中某节点到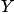 中某节点的路径 (不管方向)。如果路径
中某节点的路径 (不管方向)。如果路径 上某节点满足如下的条件:
上某节点满足如下的条件:在路径 上,w点处为v 结构 (或称冲撞点,collider),且W及其后代不在Z中; 在路径 上,w点处不是v 结构,且 w在 中,
进一步,如果 Z阻断了X到 Y的所有路径,那么称 z d 分离 X和Y,记为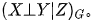
Z中节点不能是的后代; Z阻断了之间所有指向  的路径(这样的路径可以称为后门路径);
的路径(这样的路径可以称为后门路径);
 后门准则。进一步,Z相对于变量的有序满足后门准则,其中
后门准则。进一步,Z相对于变量的有序满足后门准则,其中  是中的任意节点;那么称变量的集Z相对于节点集合的有序对
是中的任意节点;那么称变量的集Z相对于节点集合的有序对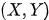 满足后门准则。满足后门准则,那X和Y的因果作用是可以识别的,且为了理解因果图的概念,下面的简短证明是很有必要的。 满足前门准则,如果
满足后门准则。满足后门准则,那X和Y的因果作用是可以识别的,且为了理解因果图的概念,下面的简短证明是很有必要的。 满足前门准则,如果Z切断了所有 X到Y 的直接路径; X到Z 没有后门路径; 所有 Z到Y 的后门路径都被X 阻断。
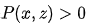 X和Y的因果作用可识别,为
X和Y的因果作用可识别,为 。
。
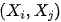 之间的后门路径被
之间的后门路径被 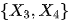 或者
或者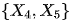 阻断,而前门路径被
阻断,而前门路径被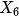 阻断。上面的两个准则表明,要识别从
阻断。上面的两个准则表明,要识别从 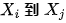 的因果作用,我们不需要观测到所有的变量,只需要观测到切断后门路径或者前门路径的变量即可。
的因果作用,我们不需要观测到所有的变量,只需要观测到切断后门路径或者前门路径的变量即可。三、 回到 Yule-Simpson’s Paradox
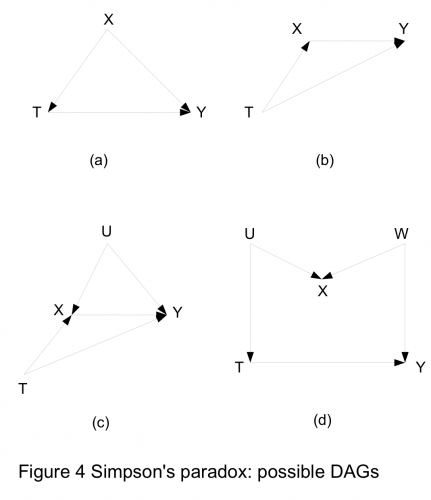
 之间形成了一个V结构:虽然 T和U之间是独立的,但是给定 X之后,T和U不再独立。
之间形成了一个V结构:虽然 T和U之间是独立的,但是给定 X之后,T和U不再独立。四、 讨论
现实的问题,是否能用一个有向无环图表示?大多数生物学家看到 DAG 的反应是“能不能用图表示反馈?”的确,DAG 作为一种简化的模型,在复杂系统中可能不完全适用。要想将 DAG 推广到动态的系统,或者时间序列中,还有待研究。 Pearl 引入的 do 算子,是他在因果推断领域最主要的贡献。所谓 “do”,就是“干预”,Pearl 认为干预就是从系统之外人为的控制某些变量。但是,这依赖于一个假定:干预某些变量并不会引起 DAG 中其他结构的变化。这个假定常常会受到质疑,但是质疑归质疑,Pearl 的这个假定虽然看似很强,但根据观测数据却不可检验。这种质疑并不是 Pearl 的理论独有的缺陷,这事实上是一切研究的缺陷。比如,我们用完全随机化试验来研究处理的作用,我们要想将实验推广到观察性的数据或者更大的人群中去,也必须用到一些不可验证的假定。 很多人看了 Pearl 的理论后就嘲笑他:难道我们可以在 DAG 中干预“性别”?确实,离开了实际的背景,干预性别似乎是不太合理的。那这个时候,根据 Pearl 的 do算子得到的因果作用意味着什么呢?可以从几个方面回答这个问题。 很多问题,我们不能谈论“干预性别”,也不能谈论“性别”的“因果作用”。“性别”的特性是“协变量”(covariate),对于这类变量(如身高、肤色等),谈论因果作用不合适,因为我们不能想象出一个可能的“实验”,干预这些变量。 上面的回答基于“实验学派”(experimentalists’)的观点,认为不可干预,就没有“因果”。但是,如果认为只要有数据的生成机制,就有因果关系,那么算出性别的因果作用也不奇怪。(计量经就学一直有争议,以 Joshua Angrist、Guido Imbens 等为首的“实验派”,和以 James Heckman 为首的“结构方程模型”派,有过很激烈的讨论。) 有些问题中性别的因果作用是良好定义的。比如,我们可以人工的修改应聘者简历上的名字(随机的使用男性和女性名字),便可以研究性别对于求职的影响,是否存在性别歧视等等(已有研究使用过这种实验设计)。 一个更为严重的问题是,实际工作中,我们很难得到一个完整的 DAG,用于阐述变量之间的因果关系或者数据生成机制,使得 DAG 的应用受到的巨大的阻碍。不过,从观测数据学习 DAG 的结构,确实是一个很有趣且重要的问题,这留待下回分解。
在何种意义下,后门准则的条件,等价于可忽略性,即
 ?
?在第一节的 Yule-Simpson’s Paradox 中,我们最终选择调整的估计量,还是不调整的估计量?
工具变量(instrumental variable)
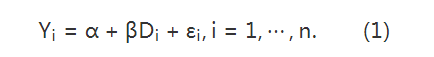
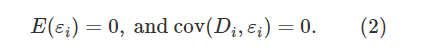
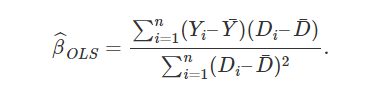

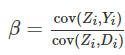
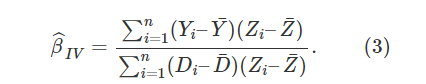

(随机化)Zi⊥{Di(1),Di(0),Yi(1),Yi(0)}
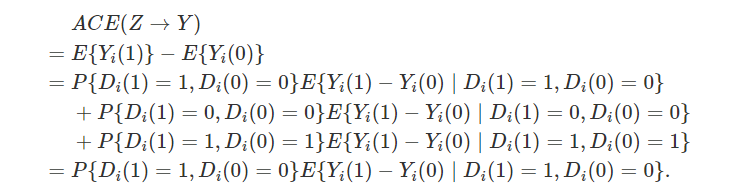
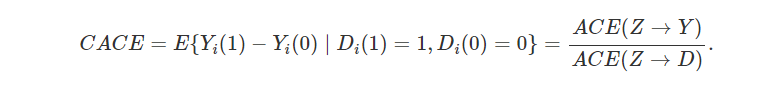
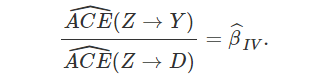

CACE.IV(Y, D, Z)$CACE[1] 0.07914375$se.CACE[,1][1,] 0.02273439$p.value[,1][1,] 0.0004991073$prob.complier[1] 0.2925123$se.complier[1] 0.004871619
五、R code
## function for complier average causal effectCACE.IV <- function(outcome, treatment, instrument) {Y <- outcomeD <- treatmentZ <- instrumentN <- length(Y)Y1 <- Y[Z == 1]Y0 <- Y[Z == 0]D1 <- D[Z == 1]D0 <- D[Z == 0]mean.Y1 <- mean(Y1)mean.Y0 <- mean(Y0)mean.D1 <- mean(D1)mean.D0 <- mean(D0)prob.complier <- mean.D1 - mean.D0var.complier <- var(D1) / length(D1) + var(D0) / length(D0)se.complier <- var.complier^0.5CACE <- (mean.Y1 - mean.Y0) / (mean.D1 - mean.D0)## COVpi1 <- mean(Z)pi0 <- 1 - pi1Omega <- c(var(Y1) / pi1, cov(Y1, D1) / pi1, 0, 0,cov(Y1, D1) / pi1, var(D1) / pi1, 0, 0,0, 0, var(Y0) / pi0, cov(Y0, D0) / pi0,0, 0, cov(Y0, D0) / pi0, var(D0) / pi0)Omega <- matrix(Omega, byrow = TRUE, nrow = 4)## GradientGrad <- c(1, -CACE, -1, CACE) / (mean.D1 - mean.D0)COV.CACE <- t(Grad) %*% Omega %*% Grad / Nse.CACE <- COV.CACE^0.5p.value <- 2 * pnorm(abs(CACE / se.CACE), 0, 1, lower.tail = FALSE)## resultsres <- list(CACE = CACE,se.CACE = se.CACE,p.value = p.value,prob.complier = prob.complier,se.complier = se.complier)return(res)}
第一个统计学家,采取了一种很简单的方法。如图所示,横轴表示 1963 年 6 月入学前的体重X,纵轴表示 1964 年 6 月前放假的体重Y。个体上来看,男女入学前和入学后一年体重都会有些变化,男女学生体重的散点图分别用绿色和红色标出。从男女学生生平均体重来看,男生入学前后一年平均体重均是 150 磅(图中右上角的黑点),女生入学前后一年平均体重均为 130 磅(图中左下角的黑点)。图中的虚线是对角线Y=X,两个黑点均位于对角线上。因此,第一个统计学家的结论是食堂对于男女学生体重都没有影响,因此对男女学生体重的作用相同。

注:横轴表示 1963 年 6 月入学前的体重X,纵轴表示 1964 年 6 月前放假的体重Y;虚线是对角线Y=X;男女学生体重的散点图分别用绿色和红色标出。图中数据生成机制如下:男学生(X,Y)~二元正态分布,均值(150,150),协方差矩阵;女学生(X,Y)~二元正态分布,均值(130,130),协方差矩阵
。生成这幅图的 R 代码可以在这里下载:Rcodehttps://uploads.cosx.org/2013/09/Rcode2.txt。由于样本量 3000,样本均值非常接近理论均值,因此落在了对角线上。)
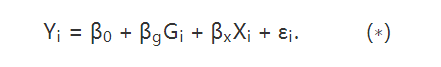
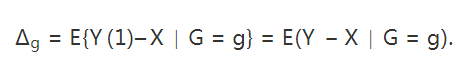
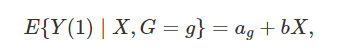
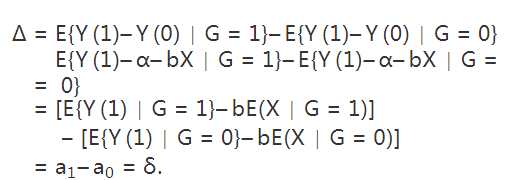
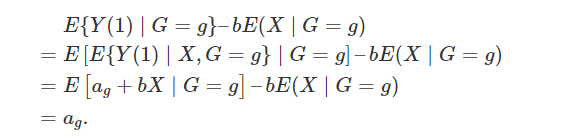
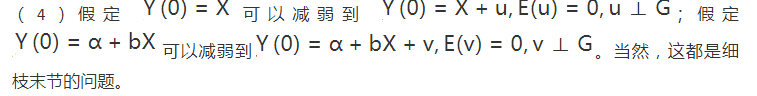
吸烟是否导致肺癌?Fisher versus Cornfield
一、Cornfield 条件或者 Cornfield 不等式




(图注:J Cornfield)
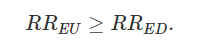
… if cigarette smokers have 9 times the risk of nonsmokers for developing lung cancer, and this is not because cigarette smoke is a causal agent, but only because cigarette smokers produce hormone X, then the proportion of hormone-X producers among cigarette smokers must be at least 9 times greater than nonsmokers. If the relative prevalence of hormone-X-producers is considerably less than ninefold, then hormone-X cannot account for the magnitude of the apparent effect.


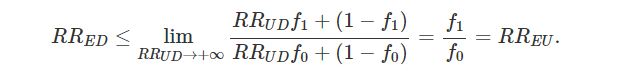
Bickel, P. J. and Hammel, E. A. and O’Connell, J. W. (1975) Sex bias in graduate admissions: Data from Berkeley. Science, 187, 398-404.
Pearl, J. (2000) Causality: models, reasoning, and inference. Cambridge University Press。
Rosenbaum, P.R. and Rubin, D.B. (1983) The central role of the propensity score in observational studies for causal effects. Biometrika, 70, 41-55.
Rothman, K., Greenland, S. and Lash, T. L. (2008) Modern Epidemiology. Lippincott Williams & Wilkins.
Neyman, J. (1923) On the application of probability theory to agricultural experiments. Essay on principles. Section 9. reprint in Statistical Science. 5, 465-472.
Pearl, J. (1995) Causal diagrams for empirical research. Biometrika, 82, 669-688.
Pearl, J. (2000) Causality: models, reasoning, and inference. Cambridge University Press。
Rubin, D.B. (1978) Bayesian inference for causal effects: The role of randomization. The Annals of Statistics, 6, 34-58.
Neyman, J. (1923) On the application of probability theory to agricultural experiments. Essay on principles. Section 9. reprint in Statistical Science. 5, 465-472. with discussion by Donald Rubin.
Rosenbaum, P. R. and Rubin, D. B. (1983) The central role of the propensity score in observational studies for causal effects. Biometrika, 70, 41-55.
Rubin, D. B. (1976) Inference and missing data (with discussion). Biometrika, 63, 581-592.
Rubin, D. B. (1978) Bayesian inference for causal effects: The role of randomization. The Annals of Statistics, 6, 34-58.
Wooldridge, J. M. (2002) Econometric analysis of cross section and panel data. The MIT press.
Lord FM. A paradox in the interpretation of group comparisons. Psychol Bull. 1967;68:304–5. doi: 10.1037/h0025105.
Holland, P.W., Rubin, D.B. (1983). On Lord’s paradox. In: Wainer, H., Messick, S. (Eds.), Principals of Modern Psychological Measurement. Lawrence Erlbaum Associates, Hillsdale, NJ, pp. 3–25.
Cornfield 最早的论文发表于 1959 年;由于它的重要性,这篇文章又在 2009 年重印了一次(50 周年纪念)。于是参考文献有两篇,它们是一样的;不过后者多了很多名人的讨论。
Cornfield J et al. Smoking and lung cancer: recent evidence and a discussion of some questions. JNCI 1959;22:173-203.
Cornfield J et al. Smoking and lung cancer: recent evidence and a discussion of some questions. Int J Epidemiol 2009;38:1175-91.(本文邀请了 David R Cox 和 Joel B Greenhouse 等人讨论。)
最近 Ding and VanderWeele 重新回访了这个经典问题,给出了更加广泛的结果。Ding, Peng and Vanderweele, Tyler J. (2014). Generalized Cornfield conditions for the risk difference, Biometrika, 101:4, 971-977. https://doi.org/10.1093/biomet/asu030

编辑:于腾凯
校对:林亦霖