
期望最大化(Expectation Maximization)算法简介和Python代码实现(附代码)

来源:DeepHub IMBA 本文约3400字,建议阅读5分钟
本文中通过几个简单的示例解释期望最大化算法是如何工作的。
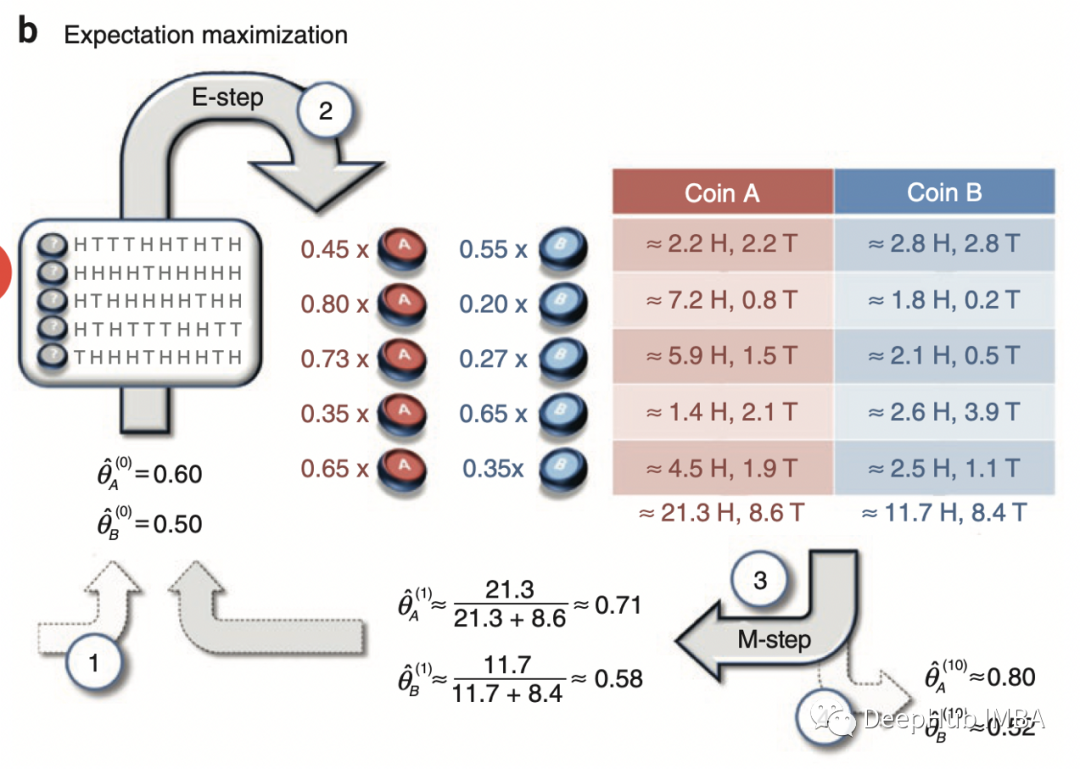
这个算法最流行的例子(互联网上讨论最多的)可能来自这篇论文
(http://www.nature.com/nbt/journal/v26/n8/full/nbt1406.html)。这是一个非常简单的例子,所以我们也从这里开始。
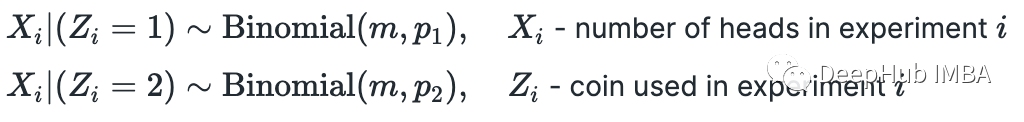
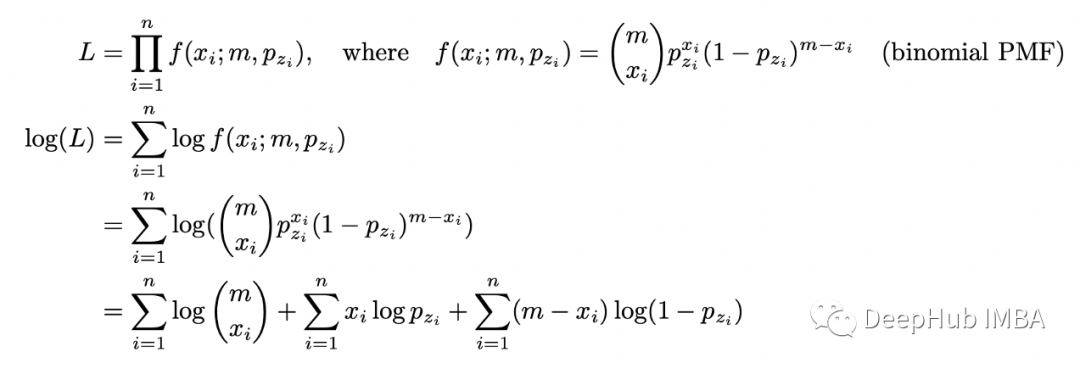
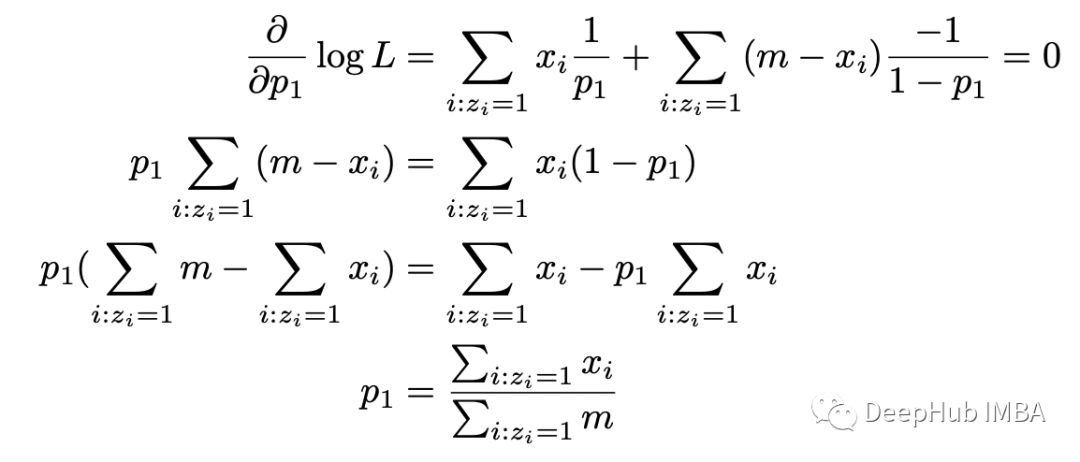
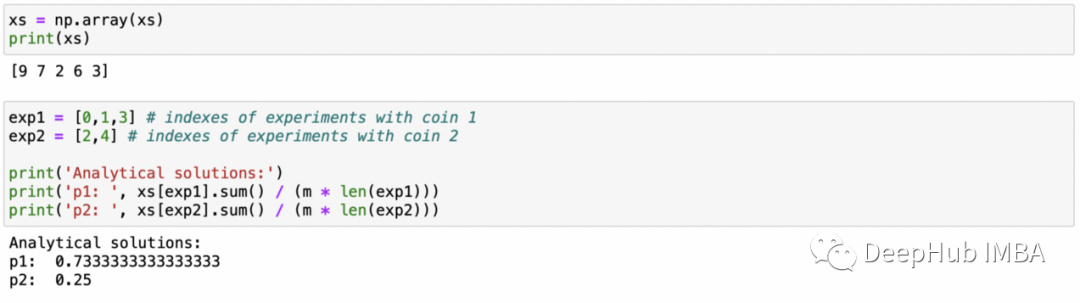
m = 10 # number of flips in experimentn = 5 # number of experimentsp_1 = 0.8p_2 = 0.3xs = [] # number of heads in each experimentzs = [0,0,1,0,1] # which coin to flipnp.random.seed(5)for i in zs:if i==0:xs.append(stats.binom(n=m, p=p_1).rvs()) # flip coin 1elif i==1:xs.append(stats.binom(n=m, p=p_2).rvs()) # flip coin 2xs = np.array(xs)print(xs)exp1 = [0,1,3] # indexes of experiments with coin 1exp2 = [2,4] # indexes of experiments with coin 2print('Analytical solutions:')print('p1: ', xs[exp1].sum() / (m * len(exp1)))print('p2: ', xs[exp2].sum() / (m * len(exp2)))
ef neg_log_likelihood(probs, m, xs, zs):'''compute negative log-likelihood'''ll = 0for x,z in zip(xs,zs):ll += stats.binom(p=probs[z], n=m).logpmf(x)return -llres = optimize.minimize(neg_log_likelihood, [0.5,0.5], bounds=[(0,1),(0,1)], args=(m,xs,zs), method='tnc')print('Numerical solution:')print('p1: ', res.x[0])print('p2: ', res.x[1])

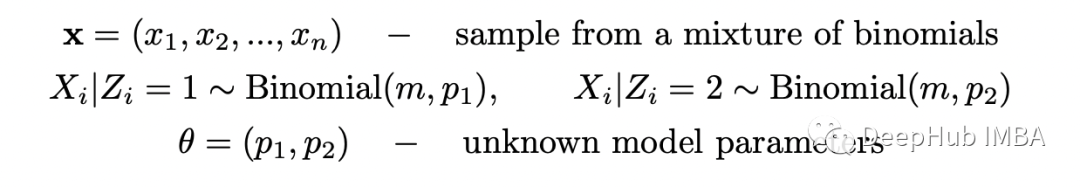
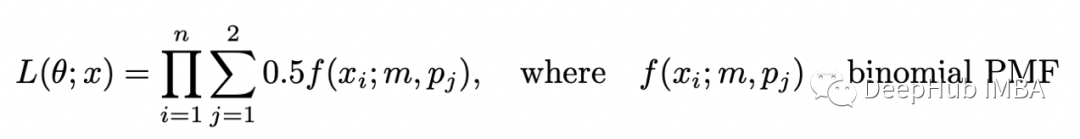
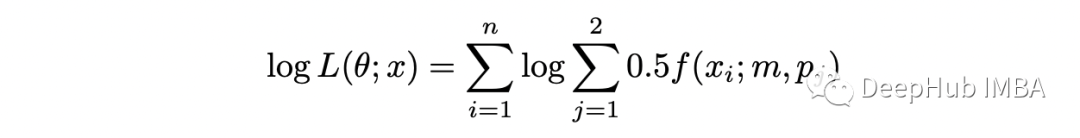
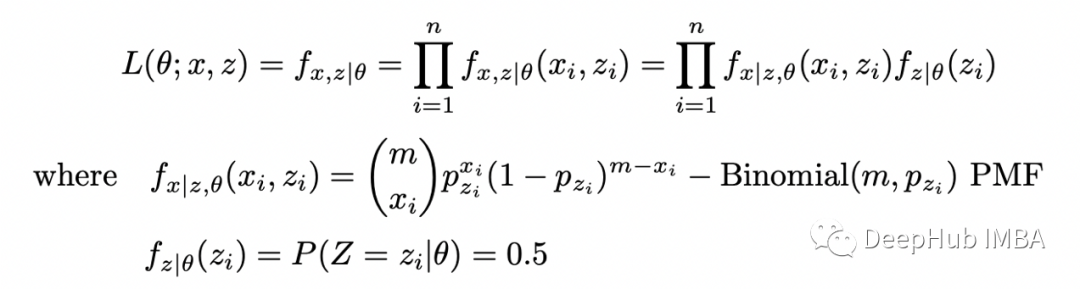
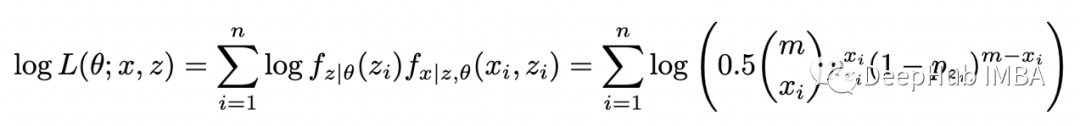
期望步骤(E-step):计算完整对数似然函数相对于 Z 给定数据 X 的当前条件分布和当前参数估计 theta 的条件期望; 最大化步骤(M-step):找到最大化该期望的参数 theta 的值。
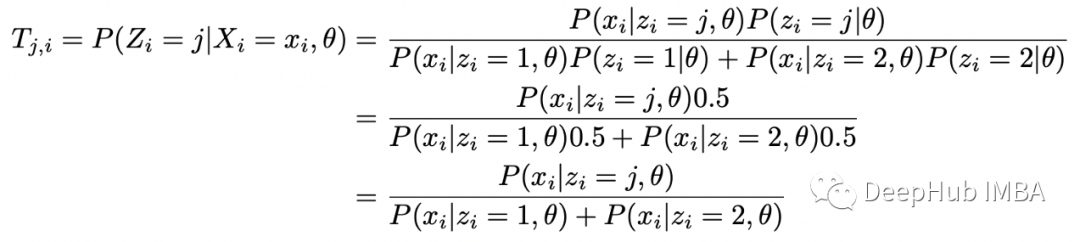
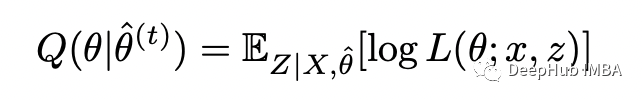
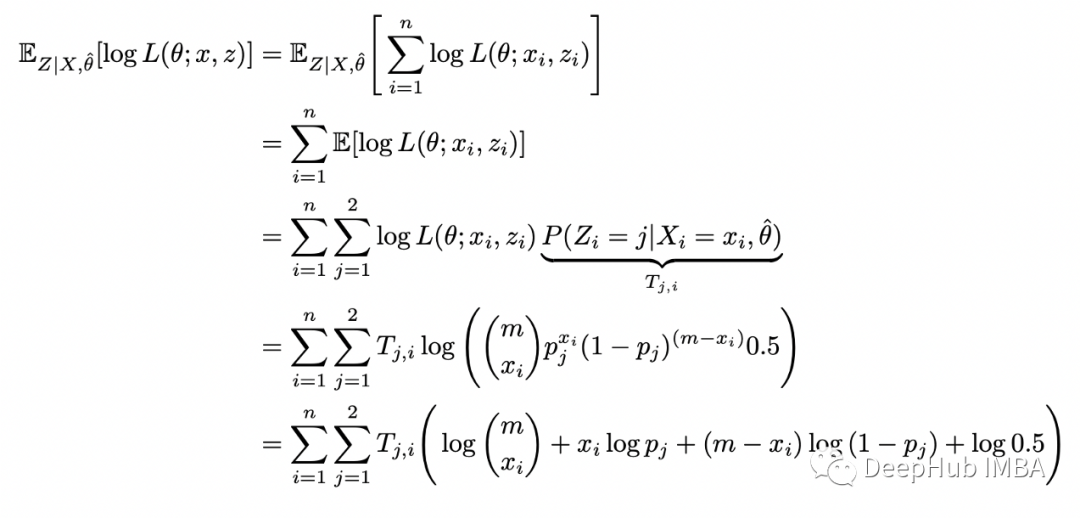
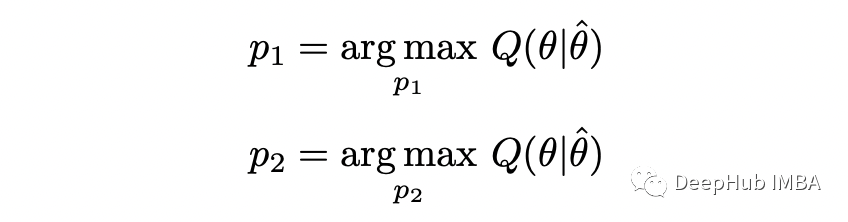
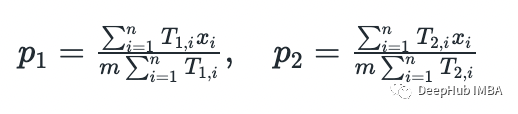
m = 10 # number of flips in each samplen = 5 # number of samplesxs = np.array([5,9,8,4,7])theta = [0.6, 0.5] # initial guess p_1, p_2for i in range(10):= thetaT_1s = []T_2s = []# E-stepfor x in xs:T_1 = stats.binom(n=m,p=theta[0]).pmf(x) / (stats.binom(n=m,p=theta[0]).pmf(x) +=m,p=theta[1]).pmf(x))T_2 = stats.binom(n=m,p=theta[1]).pmf(x) / (stats.binom(n=m,p=theta[0]).pmf(x) +=m,p=theta[1]).pmf(x))T_1s.append(T_1)T_2s.append(T_2)# M-stepT_1s = np.array(T_1s)T_2s = np.array(T_2s)p_1 = np.dot(T_1s, xs) / (m * np.sum(T_1s))p_2 = np.dot(T_2s, xs) / (m * np.sum(T_2s)):{i}, p1={p_1:.2f}, p2={p_2:.2f}')theta = [p_1, p_2]

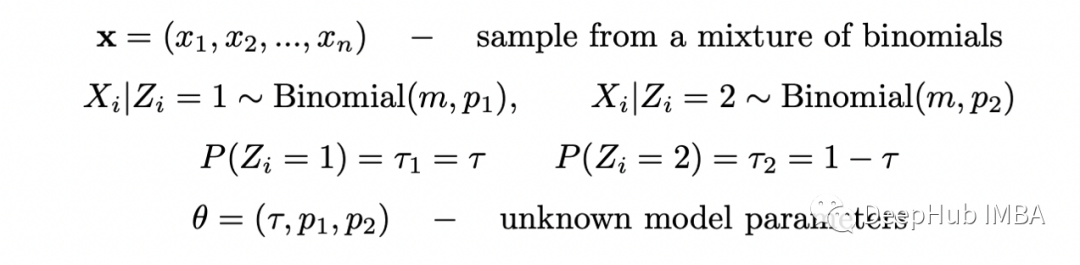
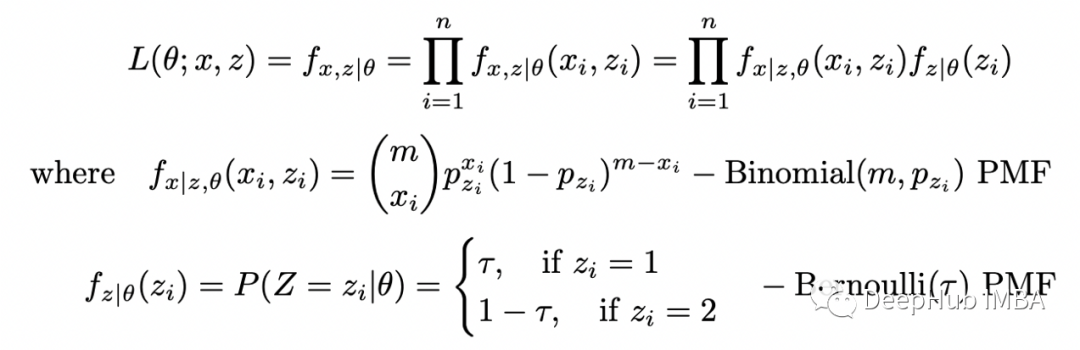
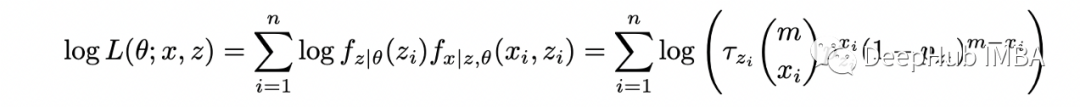
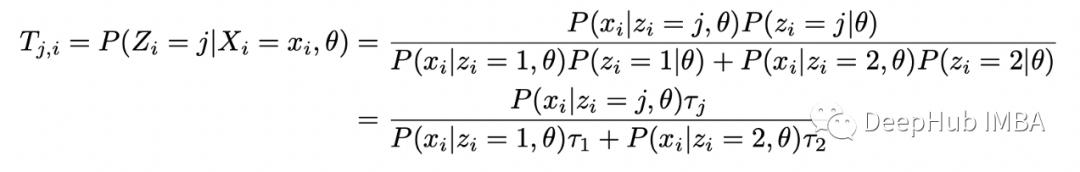
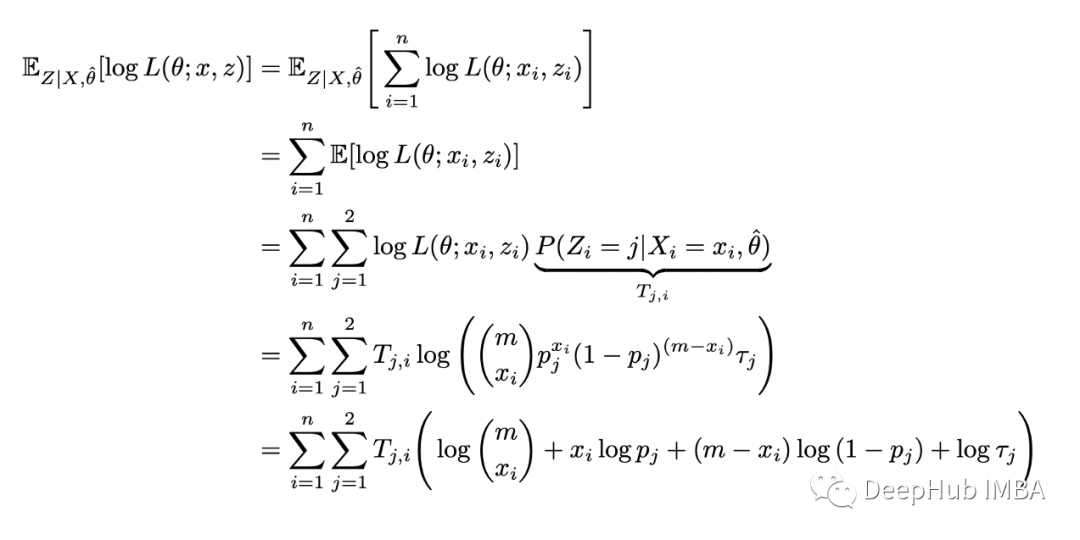
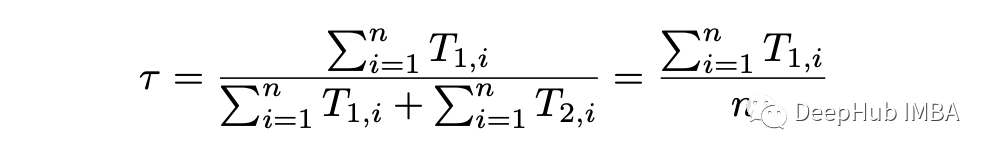
# model parametersp_1 = 0.1p_2 = 0.8tau_1 = 0.3tau_2 = 1-tau_1m = 10 # number of flips in each samplen = 10 # number of samples# generate datanp.random.seed(123)dists = [stats.binom(n=m, p=p_1), stats.binom(n=m, p=p_2)]xs = [dists[x].rvs() for x in np.random.choice([0,1], size=n, p=[tau_1,tau_2])]# random initial guessnp.random.seed(123)theta = [np.random.rand() for _ in range(3)]last_ll = 0max_iter = 100for i in range(max_iter):= thetaT_1s = []T_2s = []# E-steplls = []for x in xs:denom = (tau * stats.binom(n=m,p=p_1).pmf(x) + (1-tau) * stats.binom(n=m,p=p_2).pmf(x))T_1 = tau * stats.binom(n=m,p=p_1).pmf(x) / denomT_2 = (1-tau) * stats.binom(n=m,p=p_2).pmf(x) / denomT_1s.append(T_1)T_2s.append(T_2)* np.log(tau * stats.binom(n=m,p=p_1).pmf(x)) +T_2 * np.log(tau * stats.binom(n=m,p=p_2).pmf(x)))# M-stepT_1s = np.array(T_1s)T_2s = np.array(T_2s)tau = np.sum(T_1s) / np_1 = np.dot(T_1s, xs) / (m * np.sum(T_1s))p_2 = np.dot(T_2s, xs) / (m * np.sum(T_2s)):{i}, tau={tau}, p1={p_1:.2f}, p2={p_2:.2f}, log_likelihood={sum(lls):.2f}')theta = [tau, p_1, p_2]# stop when likelihood doesn't improve anymoreif abs(sum(lls) - last_ll) < 0.001:breakelse:last_ll=sum(lls)

https://github.com/financialnoob/misc/blob/305bf8bc7cbdddaf47d40078100ba27935ff4452/6.introduction_to_em_algorithm.ipynb
编辑:于腾凯 校对:林亦霖
评论