
Excel、SQL、Python做数据分析有何不同?
作者简介
HeoiJin:立志透过数据看清世界的产品策划,专注爬虫、数据分析、产品策划领域。万物皆营销 | 资本永不眠 | 数据恒真理
CSDN:https://me.csdn.net/weixin_40679090
一、前言
后互联网时代,获客拉新的成本越来越高,如何增加客户的留存,提高客户的复购次数、购买金额等变得十分重要,同期群分析便是当中非常重要的分析方法。
关于同期群分析概念和思路的文章很多,但分享如何实现的文章非常罕见。因此,本文将简单介绍同期群分析的概念,并用数据分析师的三板斧ESP(Excel、MySQL、Python)分别实现同期群分析。
二、项目准备
Excel: office或wps均可,office 2013后的版本更好 MySQL: 版本:8.0(本次不涉及窗口函数,其他版本亦可) Navicat Python: 版本:3.7 IDE:pycharm 库:pandas、xlrt
PS.
因篇幅原因,可能会有未能详细讲解的过程 完整源码及数据集请移步至文末获取
三、同期群分析概念讲解
数据分析最终目标都是为了解决业务问题,任何分析方法都只是工具。因此在详细讲解如何实现之前,需要先明晰方法的含义是什么,能带来什么收益,才能在合适的问题上选对分析方法。
3.1 同期群分析含义
同期群(Cohort)即相同时间内具有相似或特定属性 、行为的群体。核心要素为时间+特定属性,比如把00后出生的人划分为一个群组。
同期群分析指将用户进行同期群划分后,对比不同同期群用户的相同指标。我们耳熟能详的留存率就是同期群分析的其中一种,案例如下图:
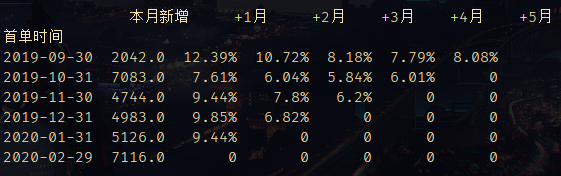
同期群分析包含了3个重要元素:
客户首次行为时间,这是我们划分同期群的依据 时间维度,即上图中+N月或者N日留存率中的N日 指标,注册转化率、付款转化率、留存率等等
3.2 意义
同期群分析给到更加细致的衡量指标,帮助我们实时监控真实的用户行为、衡量用户价值,并为营销方案的优化和改进提供支撑:
横向比较:观察同一同期群在不同生命周期下的行为变化,推测相似群体的行为随时间的变化
纵向比较:观察不同的同期群在同一个生命周期下的行为变化,验证业务行为是否取得预期效果
四、材料梳理
4.1 数据情况梳理
拿到数据的第一步,自然是了解数据的情况。针对本次同期群分析,我们可能需要用到的字段有:
客户昵称 付款时间:时间戳形式 订单状态:交易失败/交易成功 支付金额 购买数量
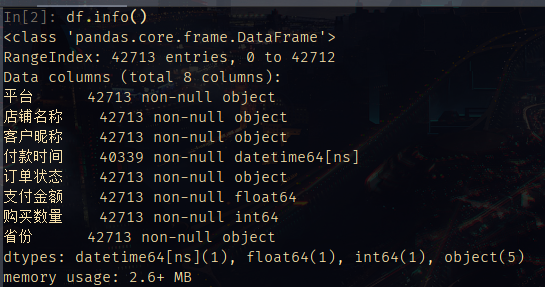
通过进一步计算,发现付款时间中缺失值所在行的订单状态均为“交易失败”,那么下文分析都需要将订单状态为“交易失败”的行全部剔除。
4.2 分析方法确定
针对此份数据,有3个分析方向可以选择:
留存率或付款率 人均付款金额 人均购买次数
我们选择其中最经典,也是数分面试中最常考的留存率作为例子,需要用到的字段有:
客户昵称 付款时间 订单状态
相信各位对留存率都十分熟悉,不过多介绍。在本次的分析中,留存率的具体计算方式为:+N月留存率=(+N月付款用户数/首月付款用户数)*100%
注意:公式中的+N月存在歧义,会有两种计算方法:
以自然月作为月份偏移的依据:即所有首次行为在9月的用户,只要10月有付款行为,都计算进+1月留存 以每30天作为月份偏移的依据:即9月30日首次付款的用户,在10月30日-11月29日之间有付款行为,才计算进+1月留存
具体的差距会在Excel(用算法1)和MySQL(用算法2)两种工具实现的结果中分别展示。没有相关技术背景的看官老爷可直接对比最终的留存率结果。
五、Excel实现
Excel的实现方式是三个当中门槛最低的,只需要掌握数据透视表和一些基础函数,但过程相对繁杂。实现思路如下:
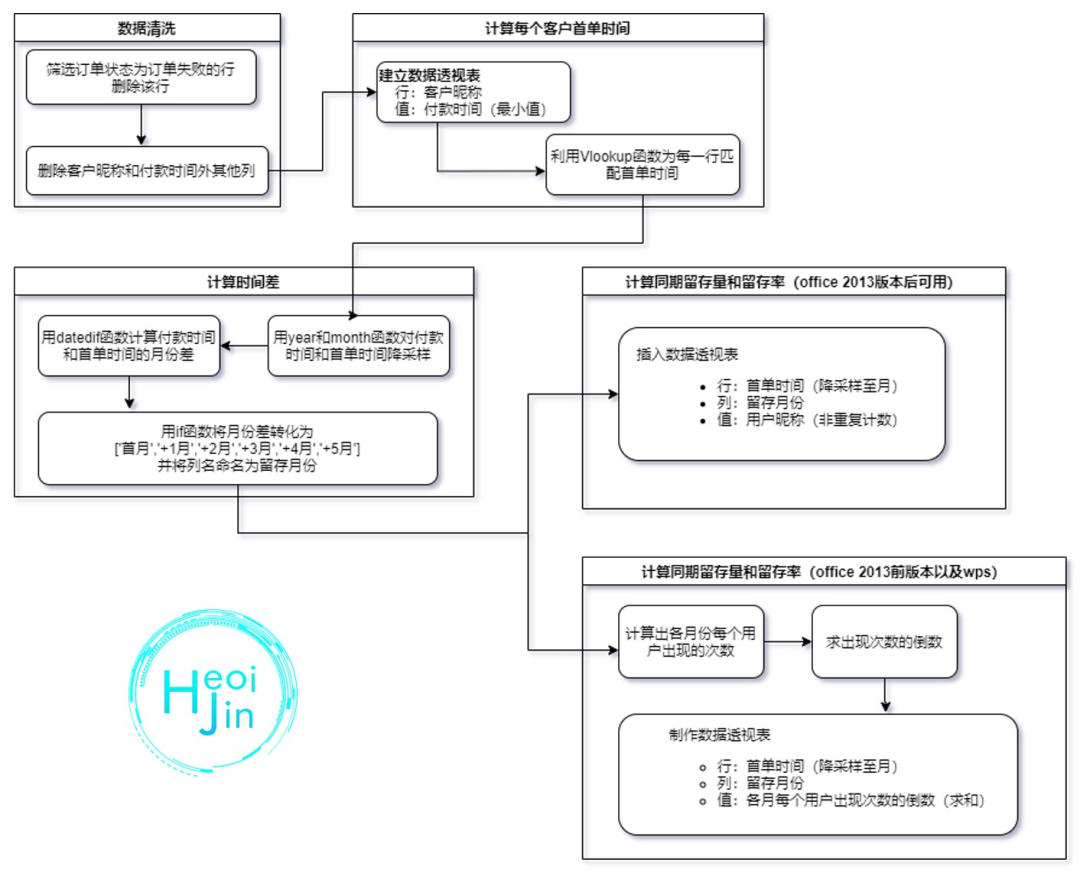
实现思路一共分为4大部分:数据清洗 -> 计算首单时间 -> 计算首单时间与付款时间差 -> 利用透视表计算同期群留存量和留存率。其中由于部分版本的office和wps的数据透视表不支持非重复计数,因此需要先计算各月中各用户出现的次数。
数据清洗部分只需要筛选+删除便可完成,相信如此简单的操作难不倒各位看官老爷们,那么我们便从第二部分开始详细讲解。
5.1 计算每个客户首单时间
首先通过数据透视表求每一个用户首次付款时间。数据透视表,说白了就是通过特定的条件进行分组,并对数据进行求和、求均值、求方差等聚合操作。在制作数据透视表时要注意以下几点:
数据区域的第一行为标题栏(字段名称) 标题栏不能出现空单元格,亦不要出现重复的标题名 数据中避免有合并单元格 不能出现非法日期
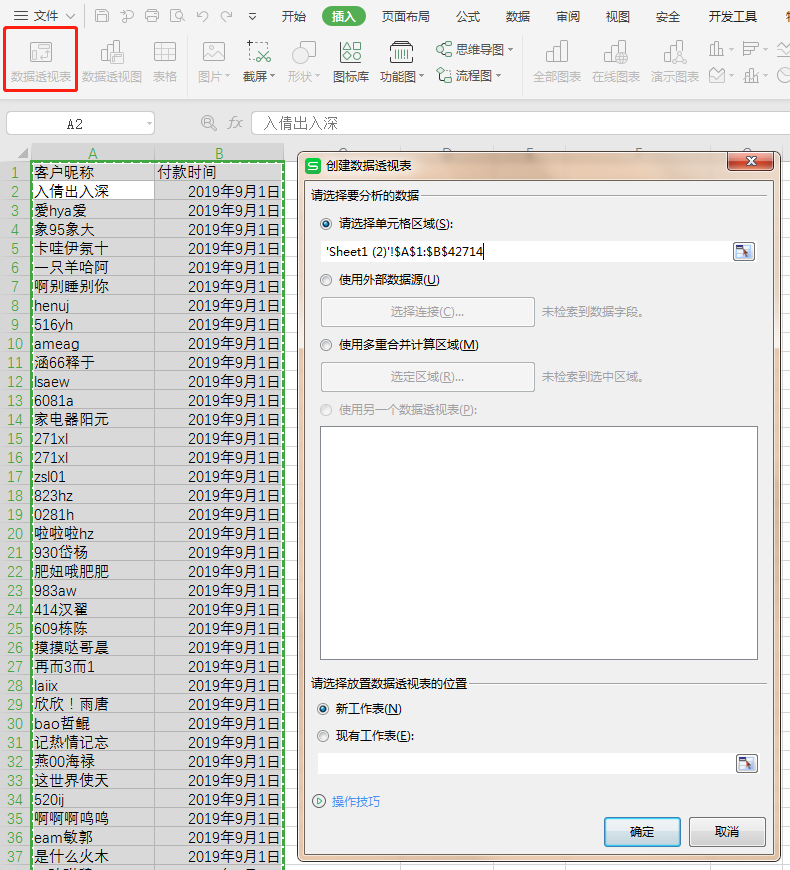
5.1.1 创建透视表
全选数据 -> 插入 -> 数据透视表 -> 确定
5.1.2 选择分组字段和值字段
将“客户昵称”拖进“行”,将付款时间拖进“值”,并将值字段设置中的汇总方式设置为最小值
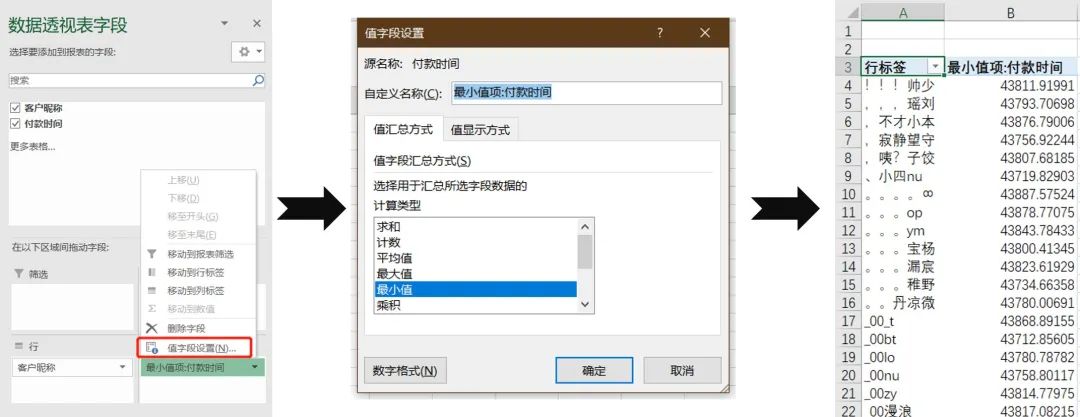
这里最小付款时间显示为10位的时间戳,只要调整显示格式便可转为我们常见的xx年xx月xx日。
5.1.3 将首单时间拼接到每个用户所在行
此步骤需要使用到vlookup函数进行匹配。VLOOKUP函数是一个纵向查找的函数,包含4个参数,具体语法为=VLOOKUP(查找的依据,查找的区域,返回的值在查找区域中的列号,是否近似匹配)
注意:
查找的位置如果要保持不变,要使用A:B或者1:15的形式锁定匹配区域 参数[ 查找的位置 ]中,“!”号前为表的名称 列号的计数是从1开始,且第一列必须是与查找依据对应的列 近似匹配参数中,0为否(即必须与查找依据一模一样才匹配),1为是(即依据为“同期”时,可以匹配出“同期”、“同期群”或者“同期群分析”)
=VLOOKUP(A2,首付时间透视表!A:B,2,0)
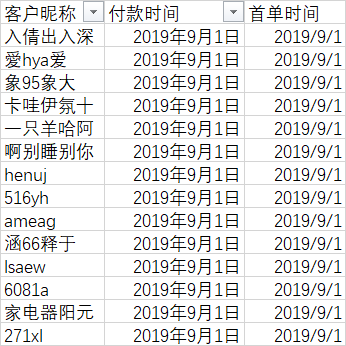
利用VLOOKUP拼接之后,首单时间同样显示为10位的时间戳,设置单元格格式后即可显示为上图的形式。
5.2 计算时间差
5.2.1 对付款时间和首单时间进行降采样
如按算法2进行计算,可直接省略此步骤。
可能有看官老爷对重采样的概念并不是很清楚,简单说下:
将时间序列从一个频率转化为另外一个频率的过程即重采样 常见的时间频率由低到高依次为:年 -> 月 -> 日 -> 时 -> 分 -> 秒 将高频率转为低频率为降采样,将低频率转为高频率为升采样
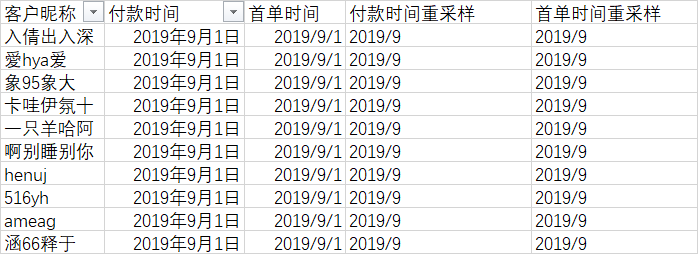
在Excel当中可以使用分列或者时间相关函数(YEAR、MONTH、DAY等)方式来获取到对应的时间频率。我们使用YEAR和MONTH来对时间进行降采样,注意与字符串连接一定要用“&”号。
=YEAR(B2)&"/"&MONTH(B2)
5.2.2 计算时间差
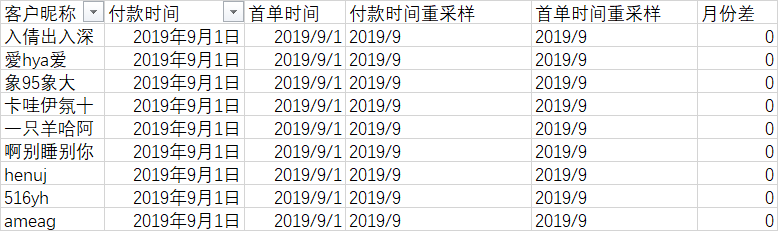
此步骤中需要用到DATEDIF函数,此公式常用于计算两个日期之间的天数、月份、年数差,语法为:=DATEDIF(起始时间,结束时间,时间频率),常用的时间频率参数有['Y','M','D'],分别对应年月日
=DATEDIF(E2,D2,"M")
5.2.3 重置月份差标签
修改透视表的标签并不方便,因此先重置月份差标签,需要用到一个IF函数便可。具体语法:=IF(条件,符合条件时的操作,不符合条件时的操作)
=IF(F2=0,"首月","+"&F2&"月")
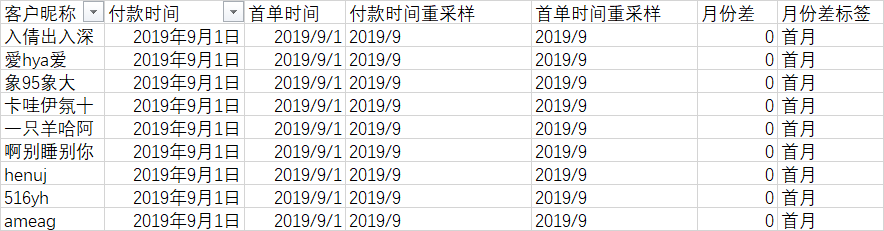
5.3 计算同期留存量和留存率
如果是office 2013及之后的版本,以上的数据已经足够我们进行留存量的计算,可以直接跳过计算用户出现次数环节。
5.3.1 计算每月中每个用户出现的次数
这里利用COUNTIFS函数,计算出“用户昵称”和“付款时间(重采样)”均相同的次数,并取其倒数,让当月无论该用户出现多少次,最终都只会计算为一次。即假设用户当月付款5次,倒数后权重变为1/5,求和后出现次数为1。
COUNTIFS的语法为:=COUNTIFS(区域A,条件A,区域B,条件B,....)
=COUNTIFS(A:A,A:A,D:D,D:D,E:E,E:E)
=1/H2
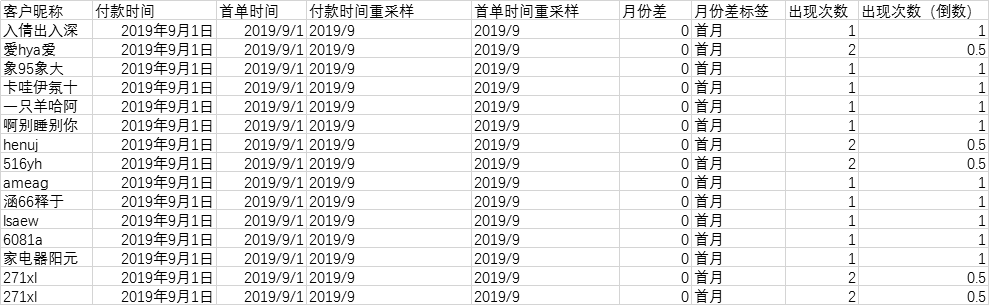
5.3.2 创建留存量数据透视表
针对wps及office2013以前的版本,我们已经计算了出现次数的倒数,只需要仿照前文“计算每个用户首单时间”的步骤创建数据透视表,以“首单时间重采样”作为行,以“月份差标签”作为列,以“出现次数(倒数)”作为值,并修改值字段设置中的计算类型为求和即可。
而office 2013及之后的版本,我们在插入数据透视表时,需要注意勾选“将此数据添加到数据模型”
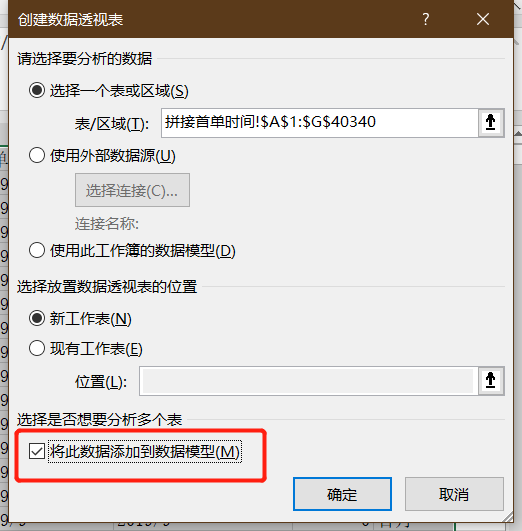
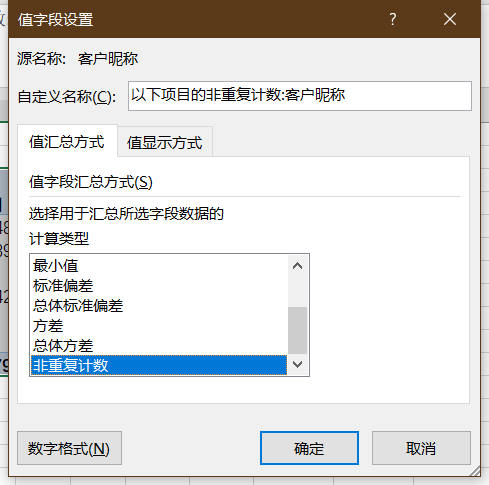
同样以“首单时间重采样”作为行,以“月份差标签”作为列,但不同的是,我们可以直接以“客户昵称”作为值,并在值字段设置当中,将计算类型设置为“非重复计数”。
到此,我们留存量的透视图便完成了,但格式看上去还是有点丑,我们手动拖动下行、列标签的排序,最终获得如下效果:
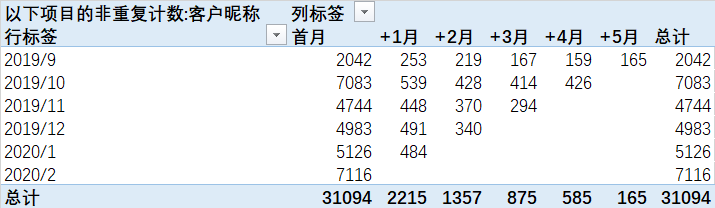
5.3.3 计算留存率
在值字段显示方式当中并没有找到我们想要的效果,因此我们在数据透视表下方选定一个区域,复制好行标签和列标签。通过公式“=C5/$B5”计算出留存率,并向右向下拖动公式便可完成
注:
B5为2019年9月的首月留存量,C5为2019年9月的+1月留存量 分母需要将B列锁定,否则在向右拖动公式时,分母会依次变为D5、E5
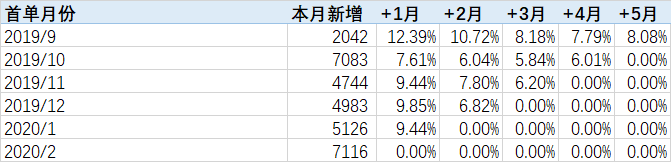
完美符合我们预期的结果!Excel版本的实现就到这里便完成,接下来是门槛稍微高一亿点点的MySQL实现。
六、MySQL实现
MySQL的实现路径与Excel的实现路径非常相近,具体步骤为:
导入数据 清洗数据:筛选订单状态为“交易成功”的行 获取首单时间 求月份偏移:求出月份差,并对首付时间降采样 计算留存量:通过首付时间和月份差进行分组,求唯一的用户id数 求留存率
6.1 导入数据
目前的数据的保存格式为xlsx,我们需要先将数据导入到数据库当中才能执行查询。第一步选择一个库,右键选择导入向导。
第二步选择导入类型,我们直接选择Excel文件即可。
第三步为选择数据源的路径,我们找到对应的数据后,勾选需要导入的表。
完成前文的操作之后便可以点击“>>”跳转至最后的步骤,当然中间还有几个调整数据的步骤,但此次数据十分工整,不需要进行额外操作。
到达下图的界面,我们按照指引直接点击“开始”即可,如导入成功,会在日志栏中显示Finished successfully,如下图所示。
6.2 数据清洗
照旧先筛选出订单状态为交易成功的行,并提取用户昵称、付款时间两个字段。这里我们稍微修改了列名,把`用户昵称`修改成`c_id`,`付款时间`修改为`paytime`,`交易状态`修改成了`status`。
我们后续的查询都是基于筛选后的数据,因此这里新建一个表sheet2去存储查询结果。
-- 步骤一:筛选订单状态为”交易成功“的行,并输出表sheet2:用户昵称[c_id]、付款时间[paytime]
CREATE table sheet2 as
SELECT c_id,paytime
FROM sheet1
WHERE `status`='交易成功';
6.3 计算首单时间
此步骤只需要对用户昵称进行groupby,再求最小值即可,不多赘述。
-- 步骤二:找出每个用户的首单时间
SELECT c_id,min(paytime) f_time
FROM sheet2
GROUP BY c_id;
6.4 计算月份差,重采样首付时间
此步骤中会涉及到两个重要的函数:
与Excel类似,MySQL对时间戳重采样也是用YEAR()、MONTH()等函数 用于计算日期差的TIMESTAMPDIFF,具体语法为TIMESTAMPDIFF(频率,起始时间,结束时间)
当然在计算月份差之前,需要以用户名称作为依据,拼接用户的首单时间。但由于数据量较大,拼接需要重复遍历整个表很多遍,耗时很长。而当前查询的结果并不是最终结果,我们只需要确保查询语句没有问题即可。因此我们引入分页查询(LIMIT语句)来限制查询结果的行数,从而提高查询效率。
-- 步骤三:求出月份差,对首付时间进行重采样
SELECT
a.c_id,
b.f_time,
TIMESTAMPDIFF(MONTH,b.f_time,a.paytime) m_diff,
CONCAT(YEAR(b.f_time),"年",MONTH(b.f_time),"月") y_m
FROM sheet2 a
LEFT JOIN (
SELECT c_id,min(paytime) f_time
FROM sheet2
GROUP BY c_id
-- LIMIT测试时用,为了提升效率
LIMIT 0,7000
) b on a.c_id=b.c_id
-- 同样是为了提升效率而使用
WHERE b.f_time is NOT NULL;
6.5 计算留存量
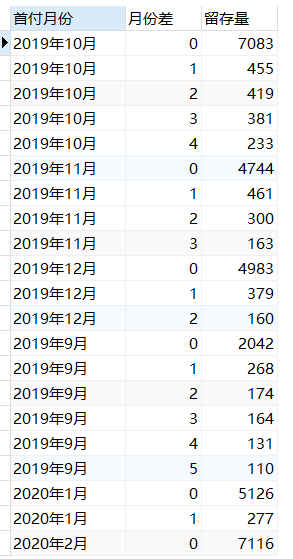
我们只需要将前面的三个步骤作为子查询,并以`首单时间`以及`月份差`作为条件对数据进行分组,用DISTINCT筛选出唯一的`用户ID`即可求出我们所需的留存量。这里创建一个名为cohort的表储存查询结果。
-- 步骤四:通过首付时间和月份差进行分组,求出唯一的用户id数,并输出为表[cohort]
CREATE table cohort as
SELECT c.y_m "首付月份",c.m_diff"月份差",COUNT(DISTINCT c.c_id) "留存量"
FROM (
SELECT
a.c_id,
b.f_time,
TIMESTAMPDIFF(MONTH,b.f_time,a.paytime) m_diff,
CONCAT(YEAR(b.f_time),"年",MONTH(b.f_time),"月") y_m
from sheet2 a
LEFT JOIN (
SELECT c_id,min(paytime) f_time
FROM sheet2
GROUP BY c_id
) b on a.c_id=b.c_id
-- 为了提升效率而使用
WHERE b.f_time is NOT NULL
) c
GROUP BY c.y_m,c.m_diff;
查询结果如下。相比于步骤三,我们这里删除了用于分页查询的LIMIT语句,但依然保留了WHERE b.f_time is NOT NULL。这里的where语句并没有筛选任何一行,但有无这一句的查询效率相差非常大,分别为0.739s和125.649s。这里涉及到SQL优化的问题,有机会以后专门整理一篇文章分享给各位。
6.6 计算留存率
我们有了留存量的表格,计算留存率便非常容易,只要让每一期的留存率都除以首月的留存率即可。
-- 步骤五:计算留存率(基础版)
SELECT c.`首付月份`,CONCAT(ROUND((c.`留存量`/m.`留存量`)*100,2),"%") 留存率
FROM cohort c
LEFT JOIN (
SELECT 首付月份,留存量
FROM cohort
where `月份差`=0
) m
on c.`首付月份`=m.`首付月份`;
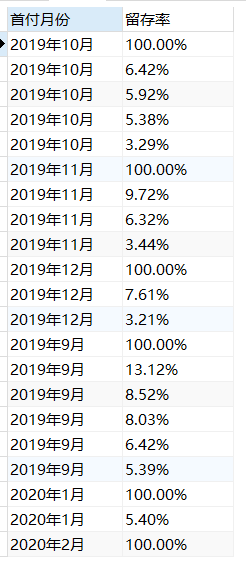
留存率结果如上图,但结果并不利于观察和分析,因此接下来的进阶版将通过case when语句,加入亿点细节来优化下展示格式。
-- 步骤五:计算留存率(进阶版)
SELECT
n.`首付月份`,
AVG(n.`留存量`) "本月新增",
CONCAT(sum(n.`+1月`),"%") "+1月",
CONCAT(sum(n.`+2月`),"%") "+2月",
CONCAT(sum(n.`+3月`),"%") "+3月",
CONCAT(sum(n.`+4月`),"%") "+4月",
CONCAT(sum(n.`+5月`),"%") "+5月"
FROM(
# 一级子查询:转置表格,将月份差作为列名
SELECT
a.`首付月份`,
a.`留存量`,
CASE a.`月份差` when 1 THEN a.`留存率` ELSE 0 END "+1月",
CASE a.`月份差` when 2 THEN a.`留存率` ELSE 0 END "+2月",
CASE a.`月份差` when 3 THEN a.`留存率` ELSE 0 END "+3月",
CASE a.`月份差` when 4 THEN a.`留存率` ELSE 0 END "+4月",
CASE a.`月份差` when 5 THEN a.`留存率` ELSE 0 END "+5月"
FROM(
# 二级子查询:计算留存率
SELECT a.`首付月份`,b.`留存量`,a.`月份差`,ROUND((a.`留存量`/b.`留存量`)*100,2) 留存率
FROM cohort a
LEFT JOIN (
# 三级子查询:查询首月用户量
SELECT `首付月份`,`留存量`
FROM cohort
WHERE cohort.`月份差`=0
) b
on a.`首付月份`=b.`首付月份`
) a
) n
GROUP BY n.`首付月份`;
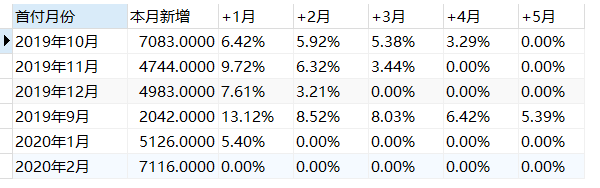
正如“分析方法确定”环节中提及,Excel中通过自然月去划分月份的偏移量,而MySQL中则直接将付款时间和首单时间相减。我们使用的TIMESTAMPDIFF函数的逻辑为结束日期的DAY参数大于等于起始日期的DAY参数时,月份差才会+N。即:
起始日期为9月30日,终止日期大于等于10月30日时,月份差才不为0。 起始日期为10月31日,终止日期大于等于12月1日时,月份差才不为0。 起始日期为1月30或31日,终止日期大于等于3月1日时,月份差才不为0,平/闰年一样。
对比可知,算法1中留存率会出现小幅度的回升,但在算法2则随时间增加而递减。由此可知,不同的计算标准对结果影响非常大,可能会造成误判,因此数据分析中确认标准非常重要。
七、Python实现
作为压轴,肯定是路子野、效率高、操作骚的Python。得益于pandas强大的分组功能及非常多的奇技淫巧,Python的实现相比于Excel或MySQL会更加简单,但实现路径会比较抽象,需要注入一点想象力。按惯例先盘实现思路:
数据清洗:删除订单状态为”交易失败“的行 拼接首单时间:计算每个用户首单时间,并拼接为新的dataframe 求留存量:对数据分组,并求唯一的客户昵称数 求留存率:用首月留存量除整个留存量的dataframe
7.1 数据清洗
此步骤只需要调用drop函数即可完成删除,难度不大,核心是找到订单状态为“交易失败”的所在行的行索引。
df.drop(index=df[df['订单状态'] == '交易失败'].index, axis=1, inplace=True)
7.2 拼接首单时间
调用分组聚合函数groupby以及数据拼接函数merge便能完成我们的需求,都是常规操作
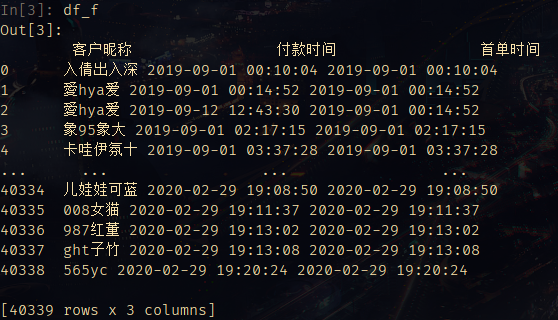
df_f = df.groupby(by='客户昵称')['付款时间'].min().to_frame(name='首单时间')
df_f.reset_index(inplace=True)
# 合并新的dataframe,包含客户昵称,付款时间,首单时间
df_f = df[['客户昵称', '付款时间']].merge(df_f)
7.3 计算留存量
接下来就是见证骚操作的时刻了。在pandas的分组聚合当中,对时间戳进行重采样不要太简单,只需要修改freq参数即可。核心思路:
利用groupby函数对首单时间和付款时间进行分组,获得复合索引的series 利用pd.Grouper对首单时间和付款时间进行重采样 利用nunique函数求不重复值个数 利用unstack函数将复合索引的series转为dataframe
# 通过首单时间及付款时间进行分组,获得每个时间段的不重复客户数量
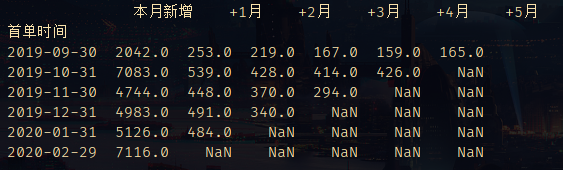
df_f = df_f.groupby(by=[pd.Grouper(key='首单时间', freq='m'), pd.Grouper(key='付款时间', freq='m')])['客户昵称'].nunique()
# 将复合索引的series转置为dataframe
df_f = df_f.unstack()

获得的结果如上图。如果有看Excel或MySQL实现方式的看官可能有会有疑问,为什么python不用计算月份差而其他两种需要。那是因为这种分组方式,首月用户量都分布在表格的对角线上,在Excel的数据透视表或者MySQL当中,等差地移动单元格并不是一件容易的事,但对于Python来说,不过是一个for循环。
for i in range(len(df_f.index)):
df_f.iloc[i] = df_f.iloc[i].shift(periods=-i)
# 重置columns
df_f.columns = ['本月新增', '+1月', '+2月', '+3月', '+4月', '+5月']
shift函数常用于移动dataframe或series,具体参数如下:
axis:针对dataframe:{0:"向下移动" , 1:"向右移动"},针对series:向下移动 periods:移动的步长,当periods为负时,向上/左移动 fill_value:补充NaN的值
得到如下结果
7.4 计算留存率
尽管pandas非常强大,但此步骤中,如通过df_f/df_f[‘首月’]计算,结果是全为NaN的dataframe。不过我们可以使用apply函数遍历dataframe来实现。
df_1 = df_f.apply(count_per, axis=0, args=(df_f['本月新增'],))
df_1['本月新增']=df_f['本月新增']
def count_per(s, dx):
a=[f'{i}%' if str(i)!='nan' else 0 for i in round((s / dx) * 100, 2)]
return a
作为pandas中最好用的函数之一,apply的详细用法各位参考官方文档即可,这里仅提三点注意事项:
在apply中调用的函数不需要加括号,仅提供函数名即可 向apply调用的函数传递变量,只需赋值给args,如果仅传递一个变量,要在变量后加上 “,”号 调用的函数当中第0个参数由self提供,从第一个变量开始才是args中的变量,即上面函数中,dx对应的是df_f['本月新增']
获得结果如下,完美完成任务:
八、复盘总结
先回顾下同期群分析的重点
同期群分析指将用户进行同期群划分后,对比不同同期群组用户的相同指标的分析方法 同期群分析是产品数据分析的核心,能细致地监控用户行为,衡量用户价值 时间的划分标准对分析结果影响很大,确定标准非常重要
最后总结下本次ESP实现方式中分别涉及到的重要知识点
| 工具 | 重要知识点 |
|---|---|
| Excel | - 数据透视表 - VLOOKUP函数 - 时间重采样函数:YEAR、MONTH - 时间差函数:DATEDIF - 条件函数:IF、COUNTIFS |
| MySQL | - 时间重采样函数:YEAR、MONTH - 时间差函数:TIMESTAMPDIFF - 流程控制函数:CASE WHEN |
| Python | - 分组api:pd.Grouper() - 不重复计数:nunique() - 元素移动:shift() - apply() |
那么本次的分享到这里便结束了。至于同期群分析如何应用到实际业务问题中,我们留到下一篇商业分析实战再详细讲解。(如果写出来的话,一定不会鸽,一定不会~鸽!)
我是HeoiJin,不要期待有下篇~
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典