
这样总结MySQL索引分类才好
文章简介
本文将大致介绍索引的类型、InnoDB的索引分类、如何创建索引、使用索引的注意事项等几个方面记录索引。由于侧重点的不同,本文不会全面介绍索引的知识点,例如二叉树、平衡二叉树、B Tree和B + Tree等,后面会单独针对这几种数据结构,进行深度的分享。导图连接(点击底部阅读原文,就可以打开文档连接了。)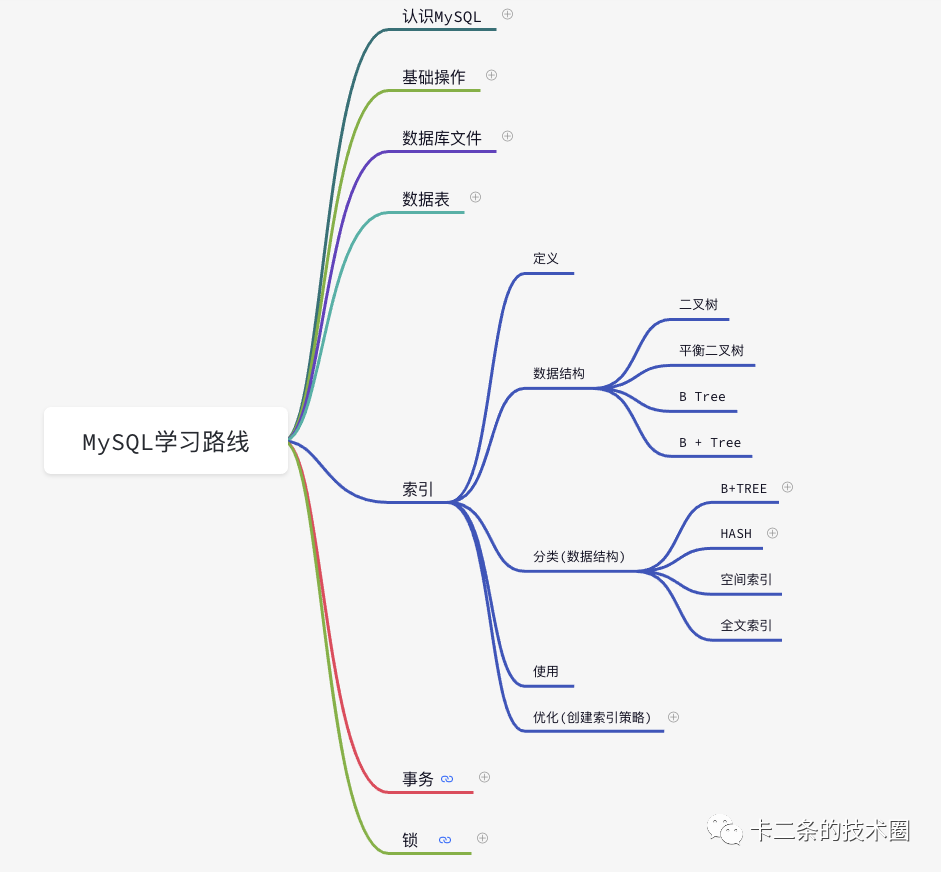
问题引入
详细很多程序员在面试的时候,都会被问到这样一个问题“MySQL中的索引都有哪些”?或许你很自信的啪啪啪答了一大堆,什么唯一索引、普通索引、主键索引、联合索引等等索引名称,你还以为自己答得非常完美。此时,你看面试官脸上带着一脸嫌弃的样子,你心里瞬间跌入了万丈深渊似的。
不是因为你没有答对,而是因为你回答的方式不对。该文将梳理如何回答该问题。
文章提纲
下面的截图也是文章的大致题纲,写作的思路也是围绕该题纲进行。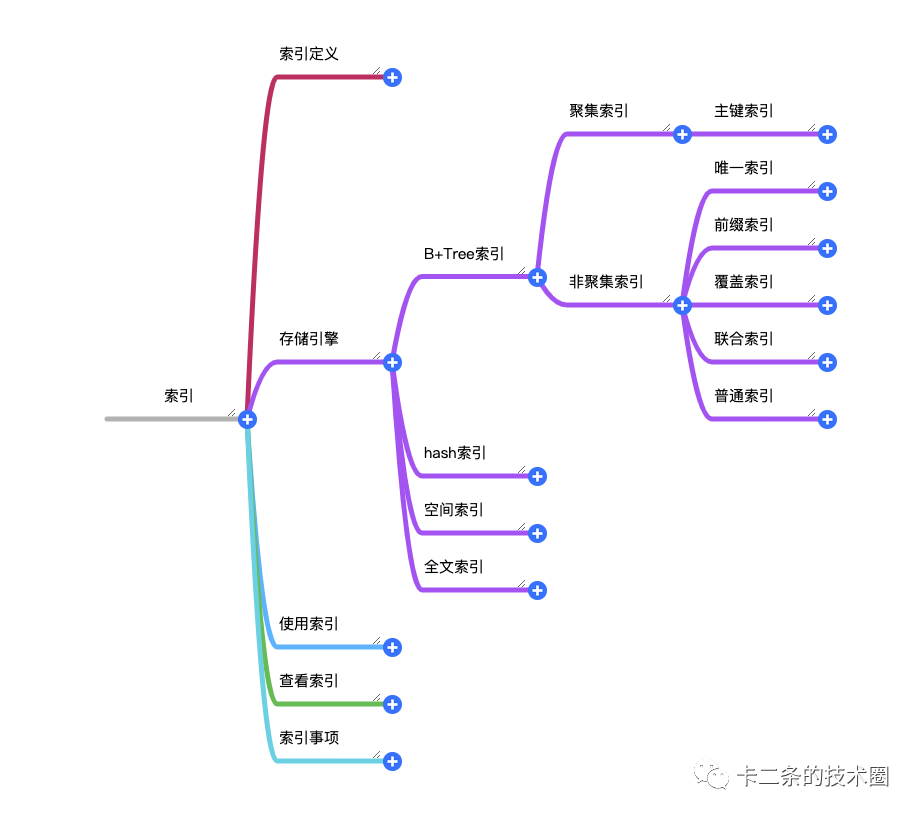
索引定义
什么是索引,想必大家都很熟悉了。使用的字典目录这个案例也是非常之多了。这里个人罗列一下自己对为什么使用索引多一个定义吧(不一定准确,属于个人理解)。
索引是利用数据结构的特点,实现一种为了快速检索数据的存储方式。
存储引擎
本文的话题是索引,为什么会提出存储引擎这个东西呢?因为不同的存储引擎支持的索引也不同。下面罗列出不同的存储引擎之间的区别:
| 引擎名称 | 支持索引类型 |
|---|---|
| InnoDB | InnoDB支持Hash/B-tree索引类型 |
| MyISAM | MyISAM支持B-tree/FullText/R-tree索引类型 |
hash索引是不需要我们手动设置的,InnoDB存储引擎的表会自动根据使用情况,调整为hash索引。其他的索引类型,使用的少,暂时也没过多的了解,后期针对该文更新时弥补上。
索引分类
索引从数据结构上主要分为下面四种索引类型。其中B+Tree索引使用情况也是最多的。后面文章重点也是总结该索引类型。
B+Tree 类型索引 hash索引 空间索引 全文索引
B+Tree索引
B+Tree是一种多路搜索的数据结构类型。它就像一棵树一样,有根节点、叶子结点、枝干等元素。一般在提交到索引的时候,都会提及到二叉树、平衡二叉树、B Tree这几种数据结构,至于为什么会提及呢?主要是B+Tree是根据这几种数据结构演变过来的,因为前面的数据结构存在这种种不足。
这里简单提及一下几种数据结构,后面单独出一篇文章来总结这几种数据结构。
索引分类
从 B+Tree数据结构分类,InnoDB中的索引类型分为聚集索引和非聚集索引。聚集索引包含了主键索引,而非聚集索引包含了唯一索引、联合索引、前缀索引、复合索引、普通索引。
hash索引
hah索引是一种等值类型的数据类型。通过将键值进行hash计算,检索时通过过相同的hash方式进行等值查找的一种存储策略方式。
这种索引类型在等值上检索快(不需要像B+tree进行逐级查找,只需要进行一次的hash计算,就等定位到数据,检索快。),但是也存在诸多不足之处。例如:
不能进行范围检索。 不能进行大小比较。 不能进行排序检索。
使用该索引也不需要手动去定义,InnoDB存储引擎会根据表的使用情况,自动生成hash索引,不能通过人为的干预生成hash索引。
定义索引
主键索引
定义
由一个或者多个字段组成的索引列,该索引列是唯一的、自增的、不能为null的。
语法
alter table table_name add primary key(column_name)
唯一索引
定义
表中的当前列的值不能重复,但可以为null。
语法
alter table table_name add unique(column_name)
前缀索引
定义
为值的前几个字符创建索引的一种策略。
语法
alter table add key(column_name(inde_length))
该类索引适用于text,blob,varchar等字符类型,但是建议减少该索引类型的使用。
优缺点
便于快速检索数据。 不能使用在order by情况中。 不能使用在group by的情况中。 不能使用在覆盖索引的情况中。 创建的索引长度,最好是根据column_name对应的长度来确定。
普通索引
语法
alter table table_name add index index_name(column_name)
联合索引
定义
是表中两个或者两个以上的索引组成的一个新索引。
语法
create index index_name on table_name(index_name_1,index_name_2)
优缺点
减少数据检索范围。 必须遵循前缀索引原则,则索引会生效。
覆盖索引
定义
一个索引包含(覆盖)所有查询字段的值。
优点
减少回表查询查询额外的字段值。为什么覆盖索引会检索快呢? 索引检索的数据量始终是小于数据表的数据量。 索引是按照顺序检索的,避免了直接检索表的随机IO读取。 减少系统层面的调用,部分存储引擎读取数据还需要调用系统层面。 在InnoDB的聚集索引中,可以减少二次索引的开销。
查看索引
show语法
mysql root@127.0.0.1:demo> show index from `user`\G;
2 rows in set
Time: 0.003s
***************************[ 1. row ]***************************
Table | user
Non_unique | 0
Key_name | PRIMARY
Seq_in_index | 1
Column_name | id
Collation | A
Cardinality | 7
Sub_part | <null>
Packed | <null>
Null |
Index_type | BTREE
Comment |
Index_comment |
***************************[ 2. row ]***************************
Table | user
Non_unique | 0
Key_name | idx_mobiel
Seq_in_index | 1
Column_name | mobile
Collation | A
Cardinality | 7
Sub_part | <null>
Packed | <null>
Null | YES
Index_type | BTREE
Comment |
Index_comment |
explain语法
explain语句可以分析出SQL语句是否使用了索引、检索的类型等情况。
mysql root@127.0.0.1:demo> explain select * from `user` where id = 1\G;
1 row in set
Time: 0.003s
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | user
partitions | <null>
type | const
possible_keys | PRIMARY
key | PRIMARY
key_len | 4
ref | const
rows | 1
filtered | 100.0
Extra | <null>
注意事项
创建索引
选择性低的字段不要创建字段。 很少查询的列不要创建索引。 大数据类型的字段不要创建索引。 尽量避免列不要使用null,尽可能的设置为not null。尽可能使用空值来代替这种情况。
使用索引
通过索引扫描的行记录数数超过全表的30%,优化器不会走索引,而且会变成全表扫描。 联合索引中,第一个查询条件不是最左索引列不会走索引。 模糊查询条件列最左以"%"开始的。 两个单列索引,一个用于检索,一个用于排序。这种情况是只能使用一个索引,因为SQL查询语句中最多只能使用一个索引,推荐使用联合索引来替代。 查询列上面使用了聚合函数,也不会走索引。
相关阅读