
用 Python 登录 24 个主流网站
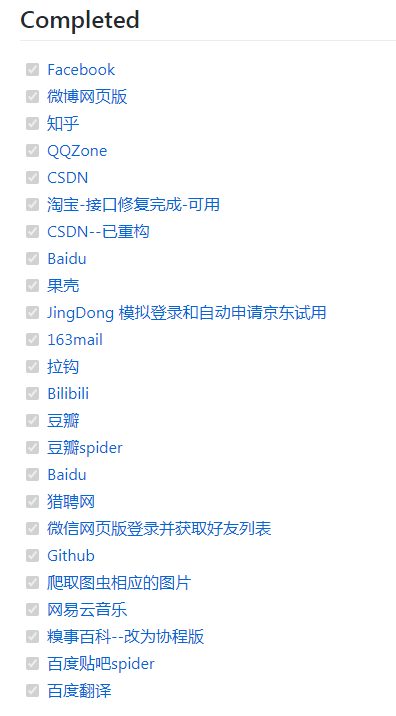
▍已完成的主流网站
▍模拟登录GitHub
"""
github第二种登录方式
info:
author:CriseLYJ
github:https://github.com/CriseLYJ/
update_time:2019-3-7
"""
import re
import requests
from lxml import etree
class Login(object):
class GithubLogin(object):
def __init__(self, email, password):
# 初始化信息
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Referer': 'https://github.com/',
'Host': 'github.com'
}
self.session = requests.Session()
self.login_url = 'https://github.com/login'
self.post_url = 'https://github.com/session'
self.session = requests.Session()
self.email = email
self.password = password
# 模拟登录
def login_GitHub(self):
# 登录入口
post_data = {
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': self.get_token(),
'login': self.email,
'password': self.password
}
resp = self.session.post(
self.post_url, data=post_data, headers=self.headers)
print('StatusCode:', resp.status_code)
if resp.status_code != 200:
print('Login Fail')
match = re.search(r'"user-login" content="(.*?)"', resp.text)
user_name = match.group(1)
print('UserName:', user_name)
response = self.session.post(self.post_url, data=post_data, headers=self.headers)
print(response.status_code)
print(post_data)
if response.status_code == 200:
print("登录成功!")
else:
print("登录失败!")
# 获取token信息
# Get login token
def get_token(self):
response = self.session.get(self.login_url, headers=self.headers)
html = etree.HTML(response.content.decode())
token = html.xpath('//input[@name="authenticity_token"]/@value')[0]
return token
if response.status_code != 200:
print('Get token fail')
return None
match = re.search(
r'name="authenticity_token" value="(.*?)"', response.text)
if not match:
print('Get Token Fail')
return None
return match.group(1)
if __name__ == '__main__':
email = input('请输入您的账号: ')
password = input('请输入您的密码: ')
email = input('Account:')
password = input('Password:')
login = Login(email, password)
login = GithubLogin(email, password)
login.login_GitHub()
▼点击成为社区会员 喜欢就点个在看吧
评论