
面试官:能说一说Mysql缓存池吗?
点上面👆 蓝色字体 关注我呀
今天来聊一聊 Mysql 缓存池原理。
提纲附上,话不多说,直接干货。

前言
面试官:同学,你能说说Mysql 缓存池吗?
狂聊君:啊,这么难吗,容我组织一下语言。(内心OS:这TM还不简单?我能给你扯半小时!)
面试官:可以,给你一分钟时间想一想吧。
....一分钟后....
狂聊君:我准备好了,你可听好,我要开始表演了。
为什么要有缓存池?
Mysql 的 innodb 存储引擎是基于磁盘存储的,并且是按照页的方式进行管理的。
在数据库系统中,CPU 速度与磁盘速度之间的差距是非常大的,为了最大可能的弥补之间的差距,提出了缓存池的概念。
所以缓存池,简单来说就是一块「内存区域」,通过内存的速度来弥补磁盘速度较慢,导致对数据库造成性能的影响。
缓存池的基本原理
「读操作」:
在数据库中进行读取页的操作,首先把从磁盘读到的页存放在缓存池中,下一次读取相同的页时,首先判断该页是不是在缓存池中。
若在,称该页在缓存池中被命中,则直接读取该页,否则,还是去读取磁盘上的页。
「写操作」:
对于数据库中页的修改操作,首先修改在缓存池中的页,然后在以一定的频率刷新到磁盘,并不是每次页发生改变就刷新回磁盘,而是通过 checkpoint 的机制把页刷新回磁盘。
可以看到,无论是读操作还是写操纵,都是对缓存池进行操作,而不是直接对磁盘进行操纵。
缓存池结构
Buffer Pool 是一片连续的内存空间,innodb 存储引擎是通过页的方式对这块内存进行管理的。
缓存池的结构如下图:

可以看到缓存池中包括数据页、索引页、插入缓存、自适应哈希索引、锁信息、数据字段。
其中数据页和索引页会用掉多数内存。
「但是,innodb 是如何管理缓存池中的这么多页呢?」
为了更好的管理这些缓存的页,innodb 为每一个缓存页都创建了一些所谓的控制信息,这些控制信息包括该页所属的:
表空间编号(sapce id) 页号(page numeber) 页在 buffer Pool 的地址 一些锁信息以及 LSN 信息日志序列号 其他控制信息
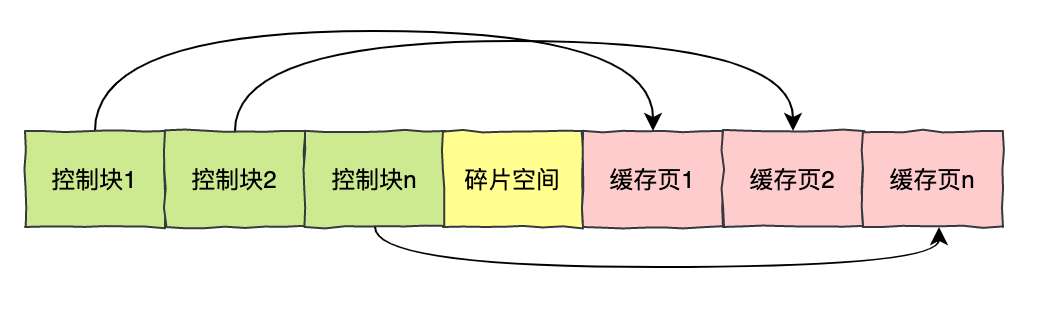
每个缓存页对应的控制信息占用的内存大小是相同的,我们把每个页对应的控制信息占用的一块内存称为一个「控制块」。
「控制块」和缓存页是一一对应的,它们都被存放到 Buffer Pool 中,其中控制块被存放到 Buffer Pool 的前边,缓存页被存放到 Buffer Pool 的后边。
Buffer Pool 对应的内存空间示意图:
缓存池参数设置
innodb_buffer_pool_size:缓存池的大小最多应设置为物理内存的 80% innodb_buffer_pool_instance:设置有多少个缓存池,通常建议把缓存池个数设置为 CPU 的个数,多个缓存池可以减少数据库内部的资源竞争,增加数据库并发访问的能力 innodb_old_blocks_pct:老生代占整个 LRU 的链长比例,默认是 3:7 innodb_old_blocks_time:老生代停留时间窗口,单位是毫秒,默认是 1000,即同时满足“被访问”与“在老生代停留时间超过 1 秒”两个条件,才会被插入到新生代头部
缓存池管理
「管理缓存池依赖的链表结构」:
Free 链表
当启动 Mysql 服务器的时候,需要完成对 Buffer Pool 的初始化过程,即分配 Buffer Pool 的内存空间,把它划分为若干对控制块和缓存页,但是此时并没有真正的磁盘页被缓存到 Buffer Pool 中,之后随着程序的运行,会不断的有磁盘上的页被缓存到 Buffer Pool 中。
在使用过程中,为了记录哪些缓存页是可用的,我们把所有空闲的页包装成一个节点组成一个链表,这个链表可以称作为 Free 链表(空闲链表)。因为刚刚完成初始化的 Buffer Pool 中所有的缓存页都是空闲的,所以每一个缓存页都会被加入到 Free 链表中。
为了方便管理 Free 链表,特意为这个链表定义了一些「控制信息」,里面包含链表的头节点地址,尾节点地址,以及当前链表中节点的数量等信息。
另外会在每个 Free 链表的节点中都记录了某个「缓存页控制块」的地址,而每个「缓存页控制块」都记录着对应的「缓存页地址」,所以相当于每个 Free 链表节点都对应一个空闲的缓存页。
给大家画了个结构图:
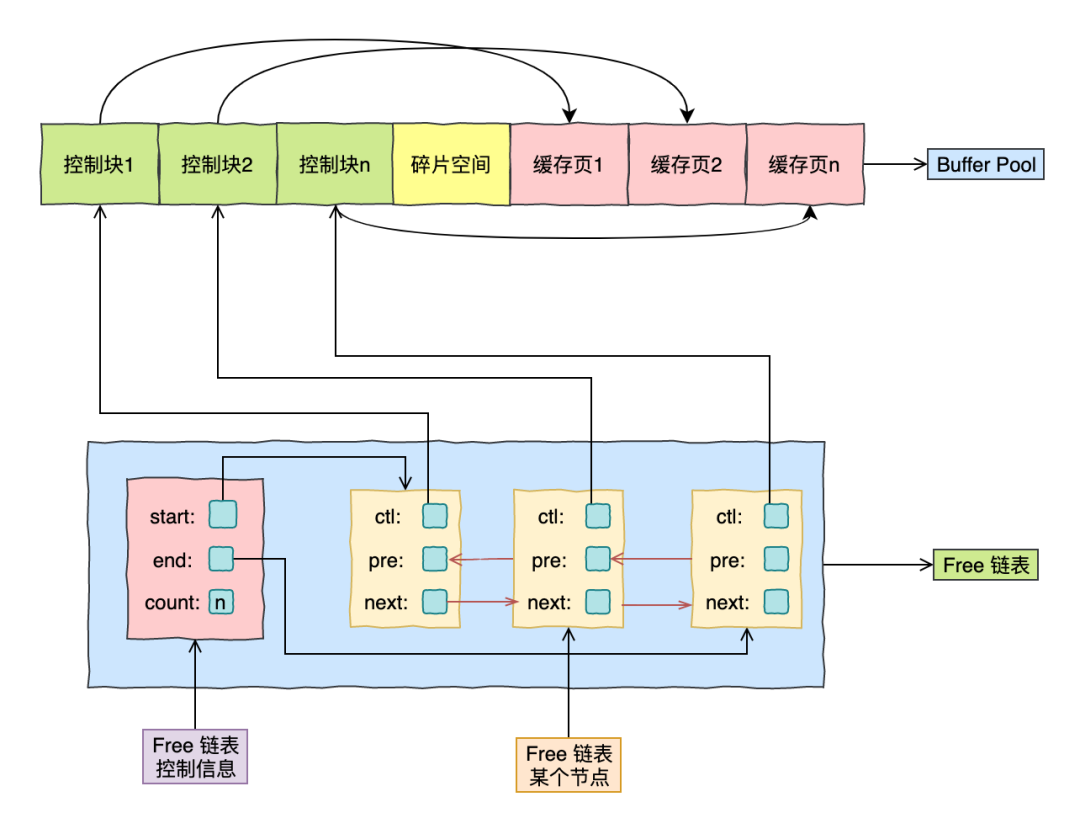
这图怎么样,这下能看的懂了吧!
2、Lru 链表
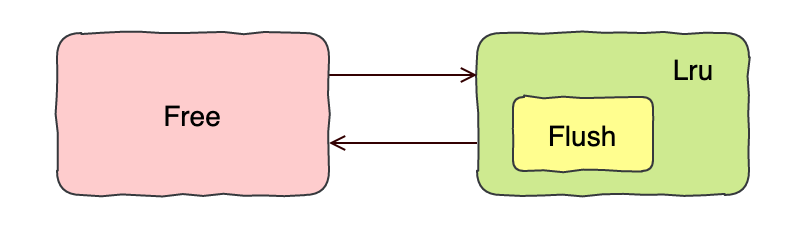
Lru 链表用来管理已经读取的页,当数据库刚启动时,Lru 链表是空的,此时页也都放在 Free 列表中,当需要读取数据时,会从 Free 链表中申请一个页,把从放入到磁盘读取的数据放入到申请的页中,这个页的集合叫做 Lru 链表。
3、Flush 链表
Flush 链表用来管理被修改的页,Buffer Pool 中被修改的页也被称之为「脏页」,脏页既存在于 Lru 链表中,也存在于 Flush 链表中,Flush 链表中存的是一个指向 Lru 链表中具体数据的指针。
因此只有 Lru 链表中的页第一次被修改时,对应的指针才会存入到 Flush 中,若之后再修改这个页,则是直接更新 Lru 链表中的页对应的数据。
这三者之间是这么个关系:
读操作
Buffer Pool 一个最主要的功能是「加速读」。加速读是当需要访问一个数据页面的时候,如果这个页面已经在缓存池中,那么就不再需要访问磁盘,直接从缓冲池中就能获取这个页面的内容。当我们需要访问某个页中的数据时,就会把该页加载到 Buffer Pool 中,如果该页已经在 Buffer Pool 中的话直接使用就可以了。
问题:那么如何快速查找在 Buffer Pool 中的页呢?
为了避免查询数据页时扫描 Lru,其实是根据表空间号 + 页号来定位一个页的,也就相当于表空间号 + 页号是一个 key,缓存页就是对应的 value。用表空间号 + 页号作为 key,缓存页作为 value 创建一个哈希表,在需要访问某个页的数据时,先从哈希表中根据表空间号 + 页号看看有没有对应的缓存页。
如果有,直接使用该缓存页就好。
如果没有,那就从 Free 链表中选一个空闲的缓存页,然后把磁盘中对应的页加载到该缓存页的位置。每当需要从磁盘中加载一个页到 Buffer Pool 中时,就从 Free 链表中取一个空闲的缓存页,并且把该缓存页对应的控制块的信息填上,然后把该缓存页对应的 Free 链表节点从链表中移除,表示该缓存页已经被使用了,并且把该页写入 Lru 链表。
在初始化的时候,Buffer pool 中所有的页都是空闲页,需要读数据时,就会从 Free 链表中申请页,但是物理内存不可能无限增大,数据库的数据却是在不停增大的,所以 Free 链表的页是会用完的。
因此需要考虑把已经缓存的页从 Buffer pool 中删除一部分,进而需要考虑如何删除及删除哪些已经缓存的页。假设一共访问了 n 次页,那么被访问的页在缓存中的次数除以 n 就是缓存命中率,缓存命中率越高,和磁盘的 IO 交互也就越少 。
为了提高缓存命中率,InnoDB 在传统 Lru 算法的基础上做了优化,解决了两个问题:1、预读失效 2、缓存池污染
写操作
Buffer pool 另一个主要的功能是「加速写」,即当需要修改一个页面的时候,先将这个页面在缓冲池中进行修改,记下相关的重做日志,这个页面的修改就算已经完成了。
被修改的页面真正刷新到磁盘,这个是后台刷新线程来完成的。前面页面更新是在缓存池中先进行的,那它就和磁盘上的页不一致了,这样的缓存页被称为脏页(dirty page)。
问题:这些被修改的页面什么时候刷新到磁盘?以什么样的顺序刷新到磁盘?
最简单的做法就是每发生一次修改就立即同步到磁盘上对应的页上,但是频繁的往磁盘中写数据会严重的影响程序的性能。所以每次修改缓存页后,不能立即把修改同步到磁盘上,而是在未来的某个时间点进行同步,由后台刷新线程依次刷新到磁盘,实现修改落地到磁盘。
但是如果不立即同步到磁盘的话,那之后再同步的时候如何判断 Buffer Pool 中哪些页是脏页,哪些页从来没被修改过呢?
InnoDB 并没有一次性把所有的缓存页都同步到磁盘上,InnoDB 创建一个存储脏页的链表,凡是在 Lru 链表中被修改过的页都需要加入这个链表中,因为这个链表中的页都是需要被刷新到磁盘上的,所以这个链表也叫 Flush 链表,链表的构造和 Free 链表一致。
这里的脏页修改指的此页被加载进 Buffer Pool 后第一次被修改,只有第一次被修改时才需要加入 Flush 链表,对于已经存在在 Flush 链表中的页,如果这个页被再次修改就不会再放到 Flush 链表。
需要注意,脏页数据实际还在 Lru 链表中,而 Flush 链表中的脏页记录只是通过指针指向 Lru 链表中的脏页。并且在 Flush 链表中的脏页是根据 oldest_lsn(这个值表示这个页第一次被更改时的 lsn 号,对应值 oldest_modification,每个页头部记录)进行排序刷新到磁盘的,值越小表示要最先被刷新,避免数据不一致。
最后
狂聊君:面试官,我就先说这些吧!
面试官:行,回答的还凑合。(内心OS:这小子知道的还挺多啊!)
看累了吧,学到了吧,那就关注一下呗!
欢迎在看、点赞、转发、您的认可是我原创的动力!
—————END—————
推荐阅读:
最近面试BAT,整理一份面试资料《Java面试BAT通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上。
明天见(。・ω・。)ノ♡