
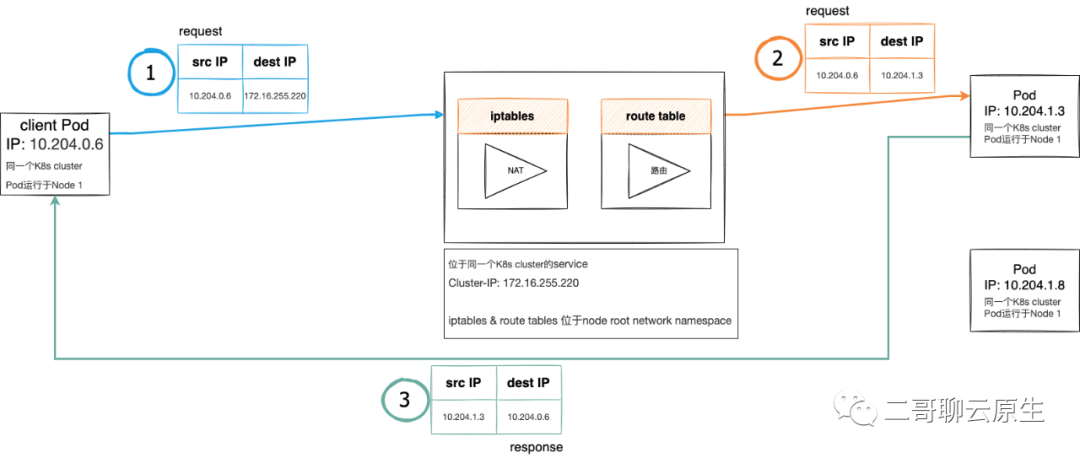
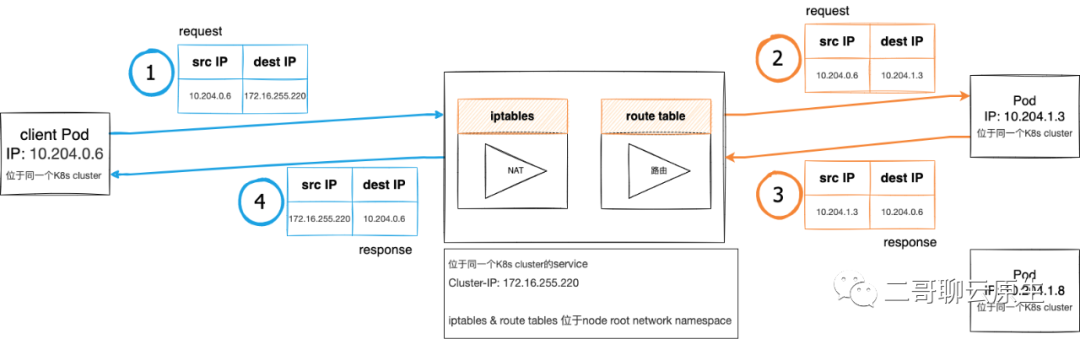
一个响应是如何从Pod回到客户端
K8s网络模型为基于veth+bridge+vtep所组成的Overlay,这也就意味着Pod跨Node通信时,需要VXLAN的介入。我在文章《特洛伊木马-图解VXLAN容器网络通信方案》详细介绍了这种方案,而在文章《当vpc遇到K8s overlay》里,则详细讨论了VXLAN是如何工作的。 参与这个游戏的各方都位于同一个K8s Cluster,它们是:client Pod,service Cluster-IP和响应请求的Pod。这里的service Cluster-IP也会被称为virtual IP。 pod向service发起的请求会经过iptables进行NAT处理。
SNAT:仅对源地址(source)进行转换。 DNAT:仅对目的地址(destination)进行转换。 Full NAT:同时对源地址和目的地址进行转换。

-A KUBE-SERVICES -d 172.16.255.220/32 -p tcp -m comment \--comment "LanceAndCloudnative/nginx-web-service: cluster IP" -m tcp --dport 80 -j KUBE-SVC-4LFXAAP7ALRXDL3I
评论