
有赞移动Crash平台建设

作者:王剑标
部门:电商移动
背景 & 痛点 & 价值
某次版本上线之后,没有及时发现其隐藏的Crash, 导致故障产生 Crash发生之后,无法根据特定规则分给某位处理人。 某个版本上线灰度时,该版本在特定角色下存在Crash。这个时候没法中断灰度版本的下发
crash平台建设的线路规划
基础架构搭建。Crash的收集、上报、分类、查看、处理
增加三方平台没有的功能。实时监控、告警、日报
补齐三方平台的功能,Crash趋势统计、Crash符号化
crash平台的功能集
Crash收集:某次Crash从发生,保存本地到上报的过程 Crash查看:查看Crash的发生堆栈,版本分布,发生页面,操作页面路径,帮助处理人快速定位问题。 Crash处理人以及状态:将某个Crash分配给指定人,发送通知。处理人修复完成之后,修改Crash的状态。 Crash分类:根据上报的Crash将Crash进行分组,不同机型、不同版本可能发生同一个Crash,某个Crash标识某段代码错误。 Crash告警检测:针对新版本引入的Crash以及因为服务端变更引起的老版本Crash,增加告警功能,第一时间发现影响面广的Crash问题。 Crash报告:每日报告,本日Crash情况,让团队的小伙伴能够清晰的了解到当天整体的crash情况,及时解决crash次数较多的问题。
Crash平台整体设计
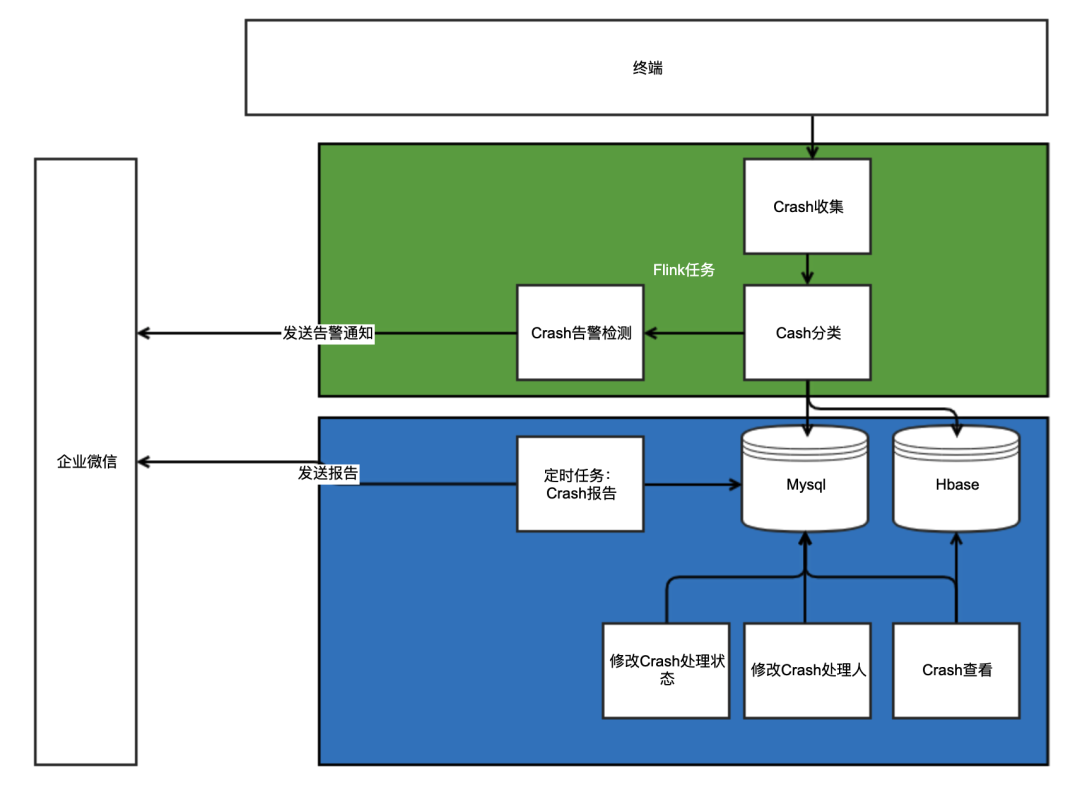
为了避免crash堆栈的数据量过大,crash堆栈等长字段存储至HBase. Mysql中只要存储前128预览字符与Hbase中的row_key即可
一、实现方案
1.1 Crash发生时的拦截+上报
Thread.UncaughtExceptionHandler接口,在初始化的时候将线程默认的Handler替换为我们拦截的Handler(当然别忘了调用下原先默认的handler)。1.2 Crash收集、数据整理--分组归类及自动分配处理人
1.2.1 Crash收集
为什么要用埋点平台, 而不是用自己上报?
埋点平台在收到来自客户端的数据后为我们做了哪些工作
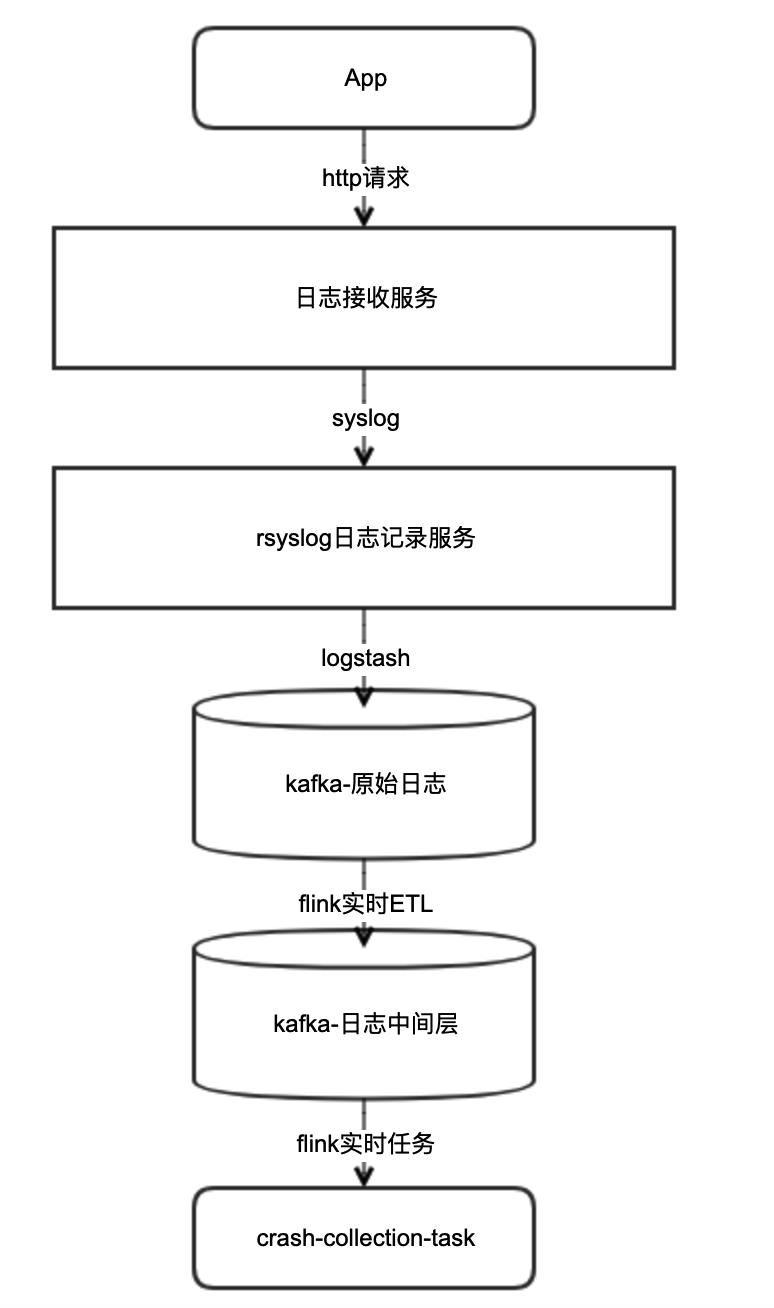
前端监控用户行为,收集并通过http请求上报 NIO高并发日志接收服务将日志转发到rsyslog服务器中 rsyslog服务器再通过logstash转发到kafka原始日志中 flink实时ETl任务将原始日志加工成标准中间层格式,并继续落地到kafka 最后消息会到我们的Crash收集flink任务程序crash-clollection-task
消息:
// 隐去敏感数据,更改为测试数据
{
topic: "topic.log",
servers: "****",
type: "kafka010",
consumerGroup: "crash_collection_task"
}@Override
public boolean filter(String line) {
try {
JSONObject data = JSON.parseObject(line);
String type = data.getString("event_type");
return Objects.equal(type, "crash");
} catch (Exception e) {
System.out.println(String.format("line:[%s]: \n解析发生错误:%s", line, e.toString()));
}
return false;
}1.2.2 分组归类、自动分配处理人
分组归类
groupIdprivate String generateGroupId() {
String groupKey = MD5Utils.crypt(bundleId + crashType + crashReason + pageType);
return "Android-v4-" + groupKey;
}
自动分配处理人
配置清单分配
历史页面自动分配
配置清单分配
{
"modules": [
{
"name": "xxxxSDK",
"key_stacks": [
"com.youzan.mobile.xxxx"
],
"cas_id": 10086
}
}历史页面自动分配
2.2 Crash实时监控、每日报告
2.2.1 版本过滤
想要过滤版本就需要知道目前某个App的最新版本多少。目前有赞移动端的打包发版控制已经都使用自研的构建发布平台。
crash上报之后,只要它的版本号大于等于最新全量的版本号,就实时上报到秒级响应群,以便及时发现最新版本、灰度版本、项目测试包的crash问题。
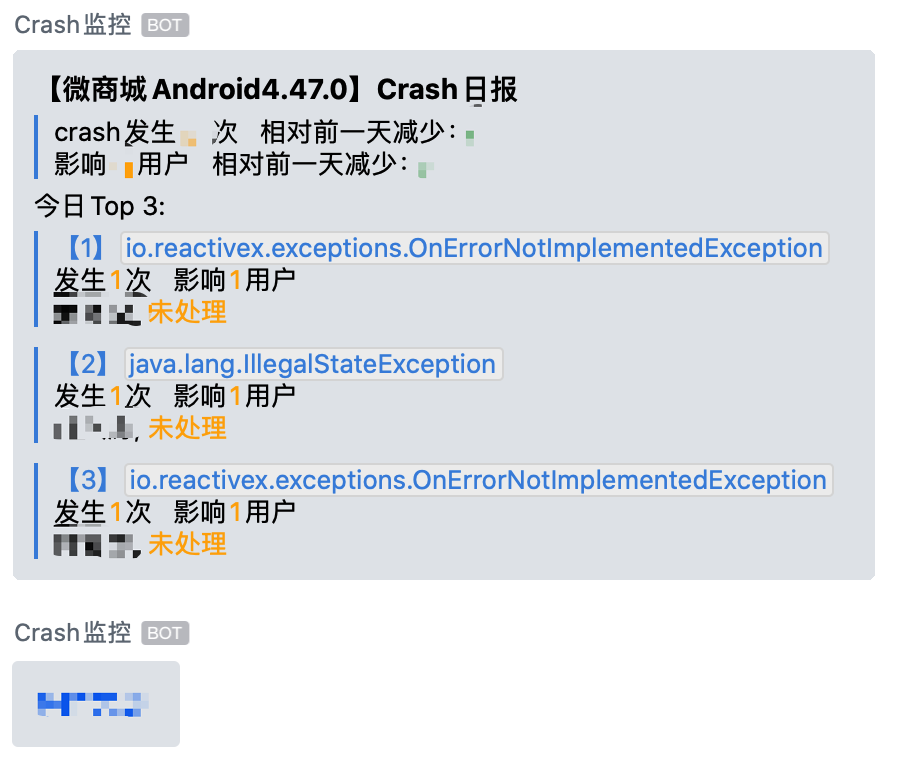
2.2.2 每日报告
每日报告功能有两个目的,一是为了让各个App负责人对每天的Crash大致状况有个大致上的了解。二是为了让没时间及时处理的小伙伴,当有属于自己的模块,发生次数、影响面比较大的Crash出现时要引起重视。
基于这样的目的我们在每日报告中加了每日Crash变化趋势(与前一日相比)、每日Crash Top N两大块。这里主要讲下设计思路。
每日Crash变化趋势
碰到的坑
起初昨日与今日的Crash次数是按照自然日取的。这样有个问题,就是昨日的次数是一整天的,今天的次数不是一整天。所以这里对比,应该以报告时间往前24小时内、48~24小时,这样来对比。才能正常反馈Crash的变化趋势。
每日Crash Top N
排序规则
排序的背后是Crash的影响面大小,影响面大的排在前。这样让处理人与管理者能每天及时知晓影响大的Crash有哪些,是否需要及时处理等等目的。
我们为什么选择了Top3?
其实开始不是Top3 ,而是Top10。但是运转一段时间后发现,crash问题并不多,每天汇报时都报Top10,会有大部分次数少的crash,会让人失焦。无论是管理者还是处理人,都搞不清楚,某个问题是该及时处理还是可以延后处理。再集合运转的这一段时间的平均数据,最终选择了Top3。
技术实现
2.3 Crash反馈平台--管理后台
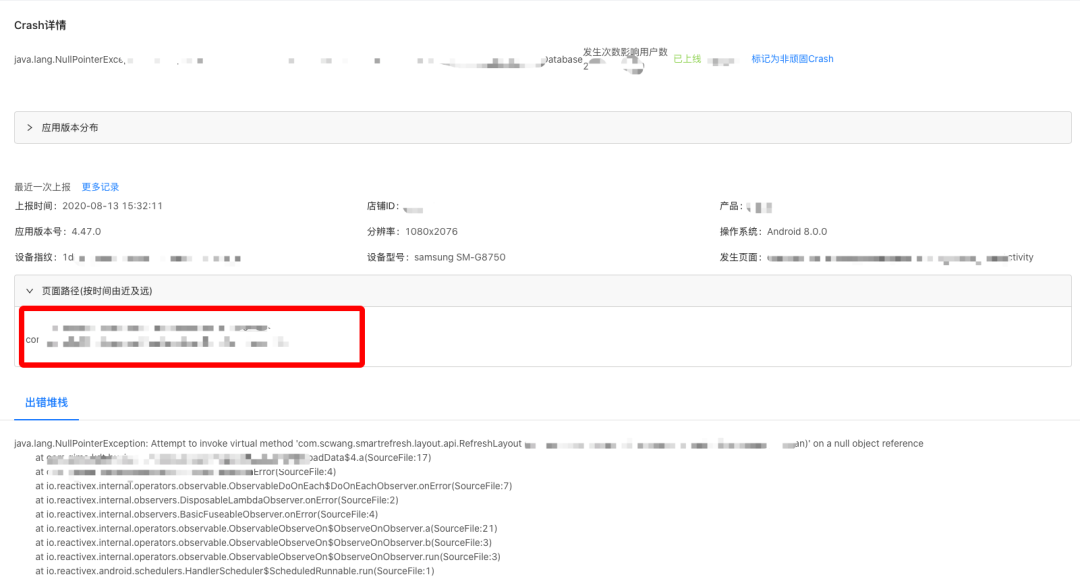
如何快速定位问题
4.47.0改了某块代码之后,发布至线上,因为用户老数据的问题,Crash一直隐藏着带到了线上。此时根据发生过的应用版本就能很快定位到Crash就是出现在4.47.0这个版本上。
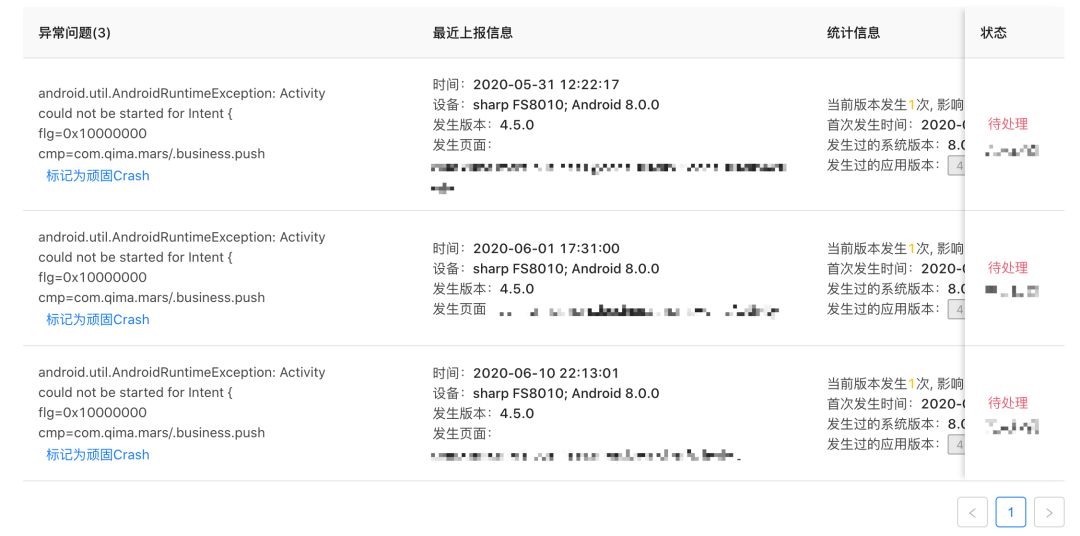
更详细的排查维度
Crash离线日志
总结

评论