
LongAdder 有点东西!
我们在之前的文章中介绍到了 AtomicLong ,如果你还不了解,我建议你阅读一下这篇文章
为什么我要先说 AtomicLong 呢?因为 LongAdder 的设计是根据 AtomicLong 的缺陷来设计的。
为什么引入 LongAdder
我们知道,AtomicLong 是利用底层的 CAS 操作来提供并发性的,比如 addAndGet 方法
public final long addAndGet(long delta) {
return unsafe.getAndAddLong(this, valueOffset, delta) + delta;
}
我们还知道,CAS 是一种轻量级的自旋方法,它的逻辑是采用自旋的方式不断更新目标值,直到更新成功。(也即乐观锁的实现模式)
在并发数量比较低的场景中,线程冲突的概率比较小,自旋的次数不会很多。但是,在并发数量激增的情况下,会出现大量失败并不断自旋的场景,此时 AtomicLong 的自旋次数很容易会成为瓶颈。
为了解决这种缺陷,引入了本篇文章的主角 --- LongAdder,它主要解决高并发环境下 AtomictLong 的自旋瓶颈问题。
认识 LongAdder
我们先看一下 JDK 源码中关于 LongAdder 的讨论

这段话很清晰的表明,在多线程环境下,如果业务场景更侧重于统计数据或者收集信息的话,LongAdder 要比 AtomicLong 有更好的性能,吞吐量更高,但是会占用更多的内存。在并发数量较低或者单线程场景中,AtomicLong 和 LongAdder 具有相同的特征,也就是说,在上述场景中,AtomicLong 和 LongAdder 可以互换。
首先我们先来看一下 LongAdder类的定义:

可以看到,LongAdder 继承于 Striped64类,并实现了 Serializable 接口。
Striped64 又是继承于 Number 类,现在你可能不太清楚 Striped64 是做什么的,但是你别急。

我们知道,Number 类是基本数据类型的包装类以及原子性包装类的父类,继承 Number 类表示它可以当作数值进行处理,然而这样并不能说明什么,它对我们来说还是一头雾水,随后我翻了翻 Striped64 的继承体系,发现这个类有几个实现,而这几个实现能够很好的帮助我们理解什么是 Striped64。

在其中我们看到了 Accumulator,它的中文概念就是累加器,所以我们猜测 Striped64 也能实现累加的功能。果不其然,在我求助了部分帖子之后,我们可以得出来一个结论:Striped64 就是一个支持 64 位的累加器。
但是那两个 Accumulator 的实现可以实现累加,这个好理解,但是这两个 Adder 呢?它们也能实现累加的功能吗?
我们再次细致的查看一下 LongAdder 和 DoubleAdder 的源码(因为这两个类非常相似)。
(下面的叙事风格主要以 LongAdder 为准,DoubleAdder 会兼带着聊一下,但不是主要叙事对象,毕竟这两个类的基类非常相似。)

在翻阅一波源码过后,我们发现了一些方法,比如 increment、decrement、add、reset、sum等,这些方法看起来好像是一个累加器所拥有的功能。
在详细翻阅源码后,我认证了我的想法,因为 increment 、decrement 都是调用的 add 方法,而 add 方法底层则使用了 longAccmulate,我给你画个图你就知道了。
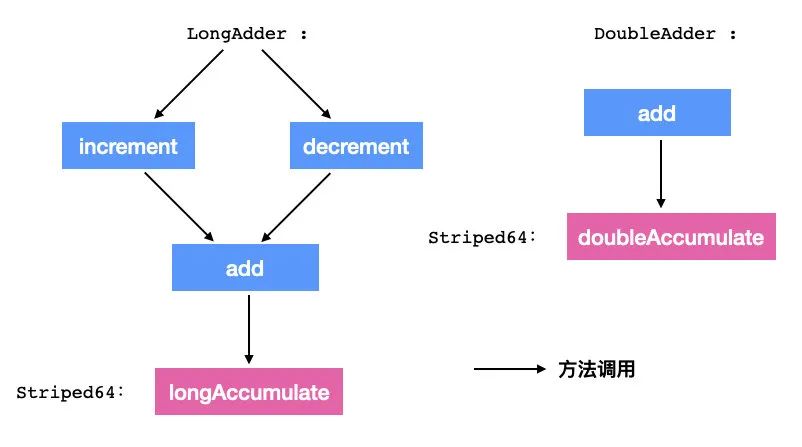
所以,LongAdder 的第一个特性就是可以处理数值,而实现了 Serializable 这个接口表示 LongAdder 可以序列化,以便存储在文件中或在网络上传输。
然后我们继续往下走,现在时间的罗盘指向了 LongAdder 的 add 方法,我们脑子里面已经有印象,这个 LongAdder 方法是来做并发累加的,所以这个 add 方法如果不出意外就是并发的累加方法,那么很奇怪了,这个方法为什么没有使用 synchronized 呢?
我们继续观察 add 方法都做了哪些操作。

开始时就是分配了一些变量而已啊,这也没什么特殊的,继续看到第二行的时候,我们发现有一个 cells 对象,这个 cells 对象是个数组,好像是个全局的。。。。。。那么在哪里定义的呢?
一想到还有个 Striped64 这个类,果断点进去看到了这个全局变量,另外,Striped64 这个类很重要,我们可不能把它忘了。

在 Striped64 类中,赫然出现了下面这三个重要的全局变量。

由 transient 修饰的这三个全局变量,会保证不会被序列化。
我们先不解释这三个变量是什么,有什么用,因为我们刚刚撸到了 add 方法,所以还是回到 add 方法上来:
继续向下走,我们看到了 caseBase 方法,这个方法又是干什么的?点进去,发现还是 Striped64 中的方法,现在,我们陷入了沉思。
我们上面只是知道了 Striped64 是一个累加器,但是我现在要不要撸一遍 Striped64 的源码??????
认识 Striped64
果然出来混都是要还的,上面没有介绍的 Striped64 的三个变量,现在就要好好介绍一波了。
cells 它是一个数组,如果不是 null ,它的大小就是 2 的次方。 base 是 Striped64 的基本数值,主要在没有争用时使用,同时也作为 cells 初始化时使用,使用 CAS 进行更新。 cellsBusy 它是一个 SpinLock(自旋锁),在初始化 cells 时使用。
除了这三个变量之外,还有一个变量,我竟然把它忽视了,罪过罪过。

它表示的是 CPU 的核数。
好像并没有看出来什么玄机,接着往下走

这里出现了一个 Cell 元素的内部类,里面出现了 long 型的 value 值,cas 方法,UNSAFE,valueOffSet 元素,如果你看过我的这篇文章 Atomic 原子工具类详解 或者你了解 AtomicLong 的设计的话,你就知道,Cell 的设计是和 AtomicLong 完全一样的,都是使用了 volatile 变量、Unsafe 加上字段的偏移量,再用 CAS 进行修改。
而这个 Cell 元素,就是 cells 数组中的每个对象。
这里比较特殊的是 @sun.misc.Contended 注解,它是 Java 8 中新增的注解,用来避免缓存的伪共享,减少 CPU 缓存级别的竞争。
害,就这?
先不要着急,Striped64 最核心的功能是分别为 LongAdder 和 DoubleAdder 提供并发累加的功能,所以 Striped64 中的 longAccumulate 和 doubleAccumulate 才是关键,我们主要介绍 longAccumulate 方法,方法比较长,我们慢慢进入节奏。
最关键的 longAccumulate
先贴出来 longAccumulate 的完整代码,然后我们再进行分析:
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
// 获取线程的哈希值
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) { // cells 已经初始化了
if ((a = as[(n - 1) & h]) == null) { // 对应的 cell 不存在,需要新建
if (cellsBusy == 0) { // 只有在 cells 没上锁时才尝试新建
Cell r = new Cell(x);
if (cellsBusy == 0 && casCellsBusy()) { // 上锁
boolean created = false;
try { // 上锁后判断 cells 对应元素是否被占用
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created) // cell 创建完毕,可以退出
break;
continue; // 加锁后发现 cell 元素已经不再为空,轮询重试
}
}
collide = false;
}
// 下面这些 else 在尝试检测当前竞争度大不大,如果大则尝试扩容,如
// 果扩容已经没用了,则尝试 rehash 来分散并发到不同的 cell 中
else if (!wasUncontended) // 已知 CAS 失败,说明并发度大
wasUncontended = true; // rehash 后重试
else if (a.cas(v = a.value, ((fn == null) ? v + x : // 尝试 CAS 将值更新到 cell 中
fn.applyAsLong(v, x))))
break;
else if (n >= NCPU || cells != as) // cells 数组已经够大,rehash
collide = false; // At max size or stale
else if (!collide) // 到此说明其它竞争已经很大,rehash
collide = true;
else if (cellsBusy == 0 && casCellsBusy()) { // rehash 都没用,尝试扩容
try {
if (cells == as) { // 加锁过程中可能有其它线程在扩容,需要排除该情形
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h); // rehash
}
else if (cellsBusy == 0 && cells == as && casCellsBusy()) { // cells 未初始化
boolean init = false;
try { // Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // 其它线程在初始化 cells 或在扩容,尝试更新 base
}
}
先别忙着惊讶,整理好心情慢慢看。
首先,在 Striped64 中,会先计算哈希,哈希值用于分发线程到 cells 数组。Striped64 中利用了 Thread 类中用来做伪随机数的 threadLocalRandomProbe:
public class Thread implements Runnable {
@sun.misc.Contended("tlr")
int threadLocalRandomProbe;
}
Striped64 中复制(直接拿来用)了 ThreadLocalRandom 中的一些方法,使用 unsafe 来获取和修改字段值。
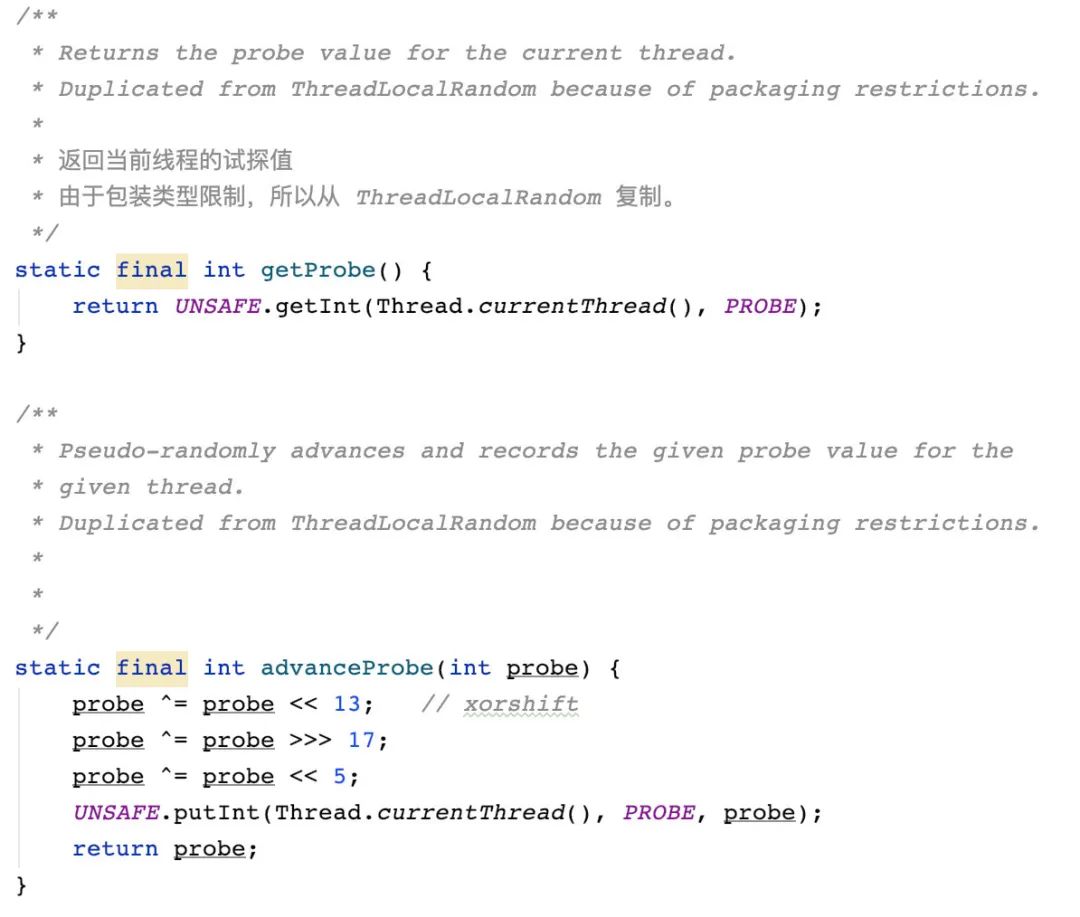
可以理解为 getProbe 用来获取哈希值,advanceProbe 用来更新哈希值。
而其中的 PROBE 常量是在类加载的时候从类加载器提取的 threadLocalRandomProbe 的常量值。
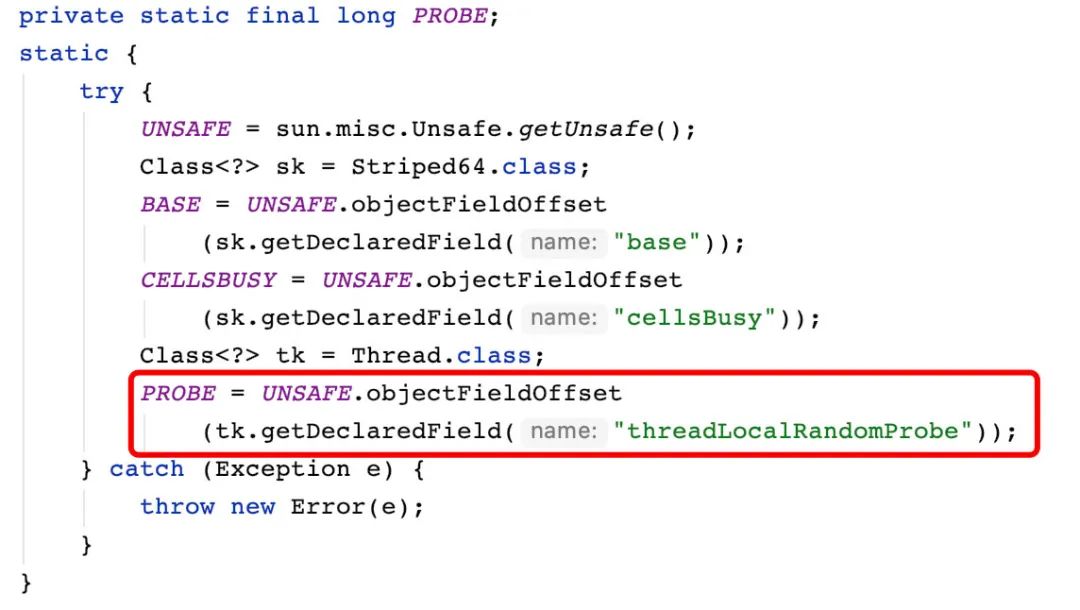
然后是一系列的循环判断向 cell 数组映射的操作,因为 Cells 类占用比较多的空间,所以它的初始化按需进行的,开始时为空,需要时先创建两个元素,不够用时再扩展成两倍大小。在修改 cells 数组(如扩展)时需要加锁,这也就是 cellsBusy 的作用。

释放锁只需要将 cellsBusy 从 0 -> 1 即可。
cellsBusy = 0;
另外,这个方法虽然代码行很多,使用了很多 if else ,但其实代码设计使用了双重检查锁,也就是下面这种模式
if (condition_met) { // 只在必要时进入
lock(); // 加锁
done = false; // 因为外层有轮询,需要记录任务是否需要继续
try {
if (condition_met) { // 前面的 if 到加锁间状态可能变化,需要重新判断
// ...
done = true; // 任务完成
}
} finally {
unlock(); // 确保锁释放
}
if (done) // 任务完成,可以退出轮询
break;
}
而 doubleAccumulate 的整体逻辑与 longAccumulate 几乎一样,区别在于将 double 存储成 long 时需要转换。例如在创建 cell 时,需要
Cell r = new Cell(Double.doubleToRawLongBits(x));
doubleToRawLongBits 是一个 native 方法,将 double 转成 long。在累加时需要再转来回:
else if (a.cas(v = a.value,
((fn == null) ?
Double.doubleToRawLongBits
(Double.longBitsToDouble(v) + x) : // 转回 double 做累加
Double.doubleToRawLongBits
(fn.applyAsDouble
(Double.longBitsToDouble(v), x)))))
上面的流程我们只是高度概括了下,实际的分支要远比我们概括的更多,longAccumulate 会根据不同的状态来执行不同的分支,比如在线程竞争非常激烈的情况下,还会通过对 cells 进行扩容或者重新计算哈希值来重新分散线程,这些做法的目的是将多个线程的计数请求分散到不同的 cell 中的 index 上,这其实和 ConcurrentHashMap 的设计思路一样,只不过 Java7 中的 ConcurrentHashMap 实现 segment 加锁使用了比较重的 synchronized 锁,而 Striped64 使用了轻量级的 unsafe CAS 来进行并发操作。
一口气终于讲完一个段落了,累屁我了,歇会继续肝下面。
下面再说回 LongAdder 这个类。
LongAdder 的再认识
所以,LongAdder 的原理就是,在最初无竞争时,只更新 base 值,当有多线程竞争时通过分段的思想,让不同的线程更新不同的段,最后把这些段相加就得到了完整的 LongAdder 存储的值,下面我画个图帮助你理解一下。
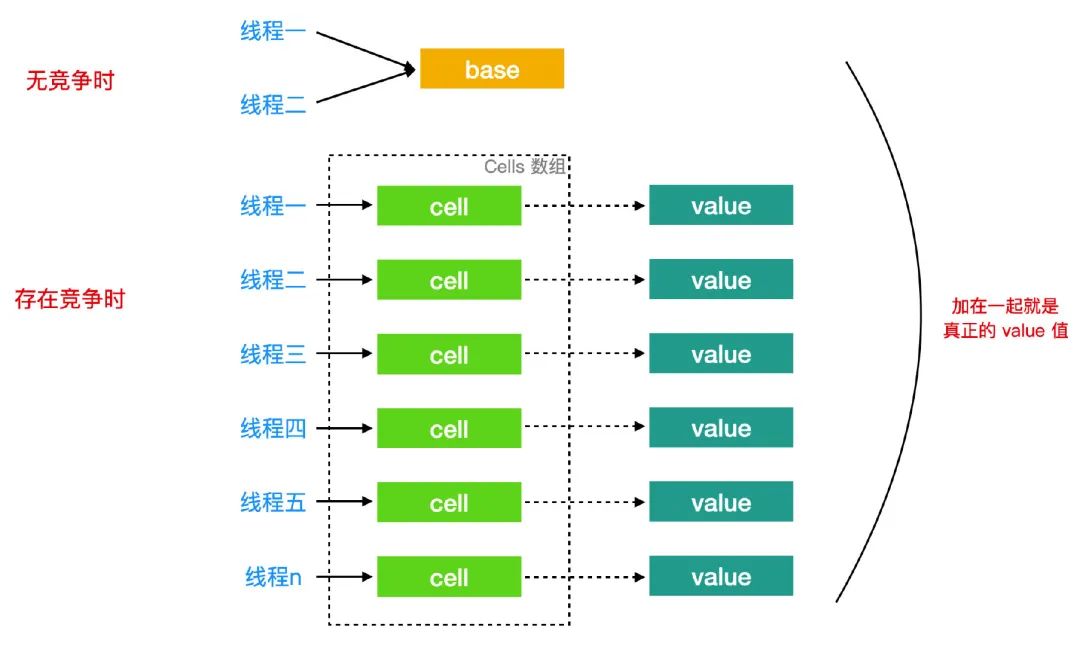
如果你理解了上面 Striped64 的描述和上面这幅图之后,LongAdder 你就理解的差不多了,最后还有一个 LongAdder 中的 sum 方法需要强调下:

sum 方法会返回当前总和,在没有并发的情况下会返回一个准确的结果,也就是把所有的 base 值相加求和之后的结果,那么,现在有一个问题,如果前面已经累加到 sum 上的 Cell 的 value 值有修改,不就没法计算了吗?
这里的结论就是,LongAdder 不是强一致性的,它是最终一致性。
后记
这篇我和你聊了一下为什么引入 LongAdder 以及 AtomicLong 有哪些缺陷,然后带你了解了一下 LongAdder 的源码和它的底层实现,如果这篇文章对你有帮助的话,可以给我个三连,你的支持是我更新最大的动力!
完
往期推荐
🔗
