
面试官:数据库SQL语句优化,你讲下
点击上方 蓝色文字 关注我们
温馨提示:本文大概 3000 字,阅读需要 5 分钟。
不管是应届生面试,还是社招后端开发,数据库优化是一个非常高频的面试题,也是一个送分题,程序汪觉得非常有必要把常见的SQL优化技巧研究一波。
拿到一段需要优化的慢查询sql,很多人都感觉无从下手。
其实SQL优化是有技巧与套路的,阅读完本文你将学会这些优化套路,让你成为别人眼中的数据库高手!
判断问题SQL
判断SQL是否有问题时可以通过两个表象进行判断:
系统级别表象 CPU消耗严重 IO等待严重 页面响应时间过长 应用的日志出现超时等错误
可以使用 sar命令,top命令查看当前系统状态。
也可以通过 Prometheus、Grafana等监控工具观察服务器状态。(感兴趣的可以翻看我之前的文章)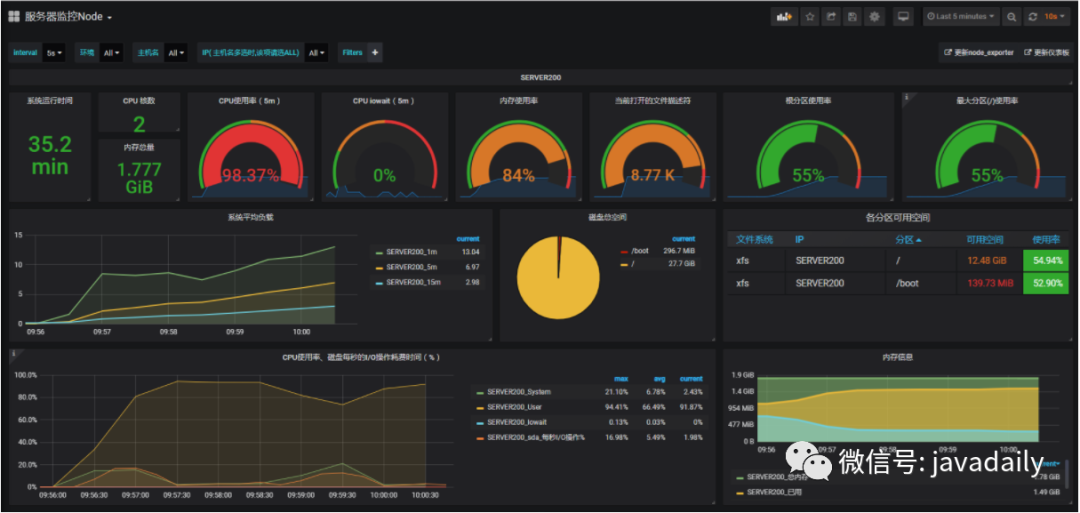
SQL语句表象 冗长 执行时间过长 从全表扫描获取数据 执行计划中的rows、cost很大
冗长的SQL都好理解,一段SQL太长阅读性肯定会差,而且出现问题的频率肯定会更高。更进一步判断SQL问题就得从执行计划入手,如下所示:
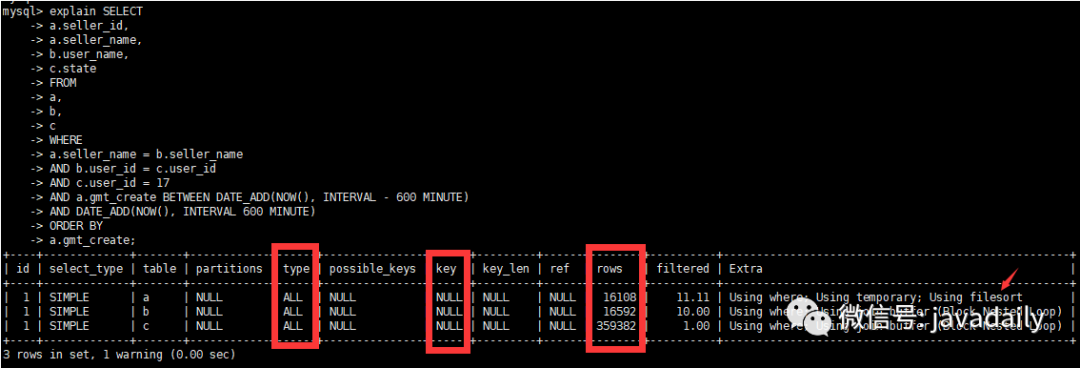
执行计划告诉我们本次查询走了全表扫描 Type=ALL,rows很大(9950400)基本可以判断这是一段"有味道"的SQL。
获取问题SQL
不同数据库有不同的获取方法,以下为目前主流数据库的慢查询SQL获取工具
MySQL 慢查询日志 测试工具loadrunner Percona公司的ptquery等工具 Oracle AWR报告 测试工具loadrunner等 相关内部视图如v、 GRID CONTROL监控工具 达梦数据库 AWR报告 测试工具loadrunner等 达梦性能监控工具(dem) 相关内部视图如v、
SQL编写技巧
SQL编写有以下几个通用的技巧:
• 合理使用索引
索引少了查询慢;
索引多了占用空间大,执行增删改语句的时候需要动态维护索引,影响性能
选择率高(重复值少)且被where频繁引用需要建立B树索引;
一般join列需要建立索引;
复杂文档类型查询采用全文索引效率更好;
索引的建立要在查询和DML性能之间取得平衡;
复合索引创建时要注意基于非前导列查询的情况
• 使用UNION ALL替代UNION
UNION ALL的执行效率比UNION高,UNION执行时需要排重;
UNION需要对数据进行排序
• 避免select * 写法
执行SQL时优化器需要将 * 转成具体的列;
每次查询都要回表,不能走覆盖索引。
• JOIN字段建议建立索引
一般JOIN字段都提前加上索引
• 避免复杂SQL语句
提升可阅读性;避免慢查询的概率;
可以转换成多个短查询,用业务端处理
• 避免where 1=1写法
• 避免order by rand()类似写法
RAND()导致数据列被多次扫描
SQL优化
执行计划
完成SQL优化一定要先读执行计划,执行计划会告诉你哪些地方效率低,哪里可以需要优化。我们以MYSQL为例,看看执行计划是什么。(每个数据库的执行计划都不一样,需要自行了解)explain sql
| 字段 | 解释 |
|---|---|
| id | 每个被独立执行的操作标识,标识对象被操作的顺序,id值越大,先被执行,如果相同,执行顺序从上到下 |
| select_type | 查询中每个select 字句的类型 |
| table | 被操作的对象名称,通常是表名,但有其他格式 |
| partitions | 匹配的分区信息(对于非分区表值为NULL) |
| type | 连接操作的类型 |
| possible_keys | 可能用到的索引 |
| key | 优化器实际使用的索引(最重要的列) 从最好到最差的连接类型为 const、eq_reg、ref、range、index和 ALL。当出现 ALL时表示当前SQL出现了“坏味道” |
| key_len | 被优化器选定的索引键长度,单位是字节 |
| ref | 表示本行被操作对象的参照对象,无参照对象为NULL |
| rows | 查询执行所扫描的元组个数(对于innodb,此值为估计值) |
| filtered | 条件表上数据被过滤的元组个数百分比 |
| extra | 执行计划的重要补充信息,当此列出现 Using filesort , Using temporary 字样时就要小心了,很可能SQL语句需要优化 |
接下来我们用一段实际优化案例来说明SQL优化的过程及优化技巧。
优化案例
表结构
CREATE TABLE `a`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_id` bigint(20) DEFAULT NULL,
`seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `b`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_name` varchar(100) DEFAULT NULL,
`user_id` varchar(50) DEFAULT NULL,
`user_name` varchar(100) DEFAULT NULL,
`sales` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `c`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`user_id` varchar(50) DEFAULT NULL,
`order_id` varchar(100) DEFAULT NULL,
`state` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);查询要求
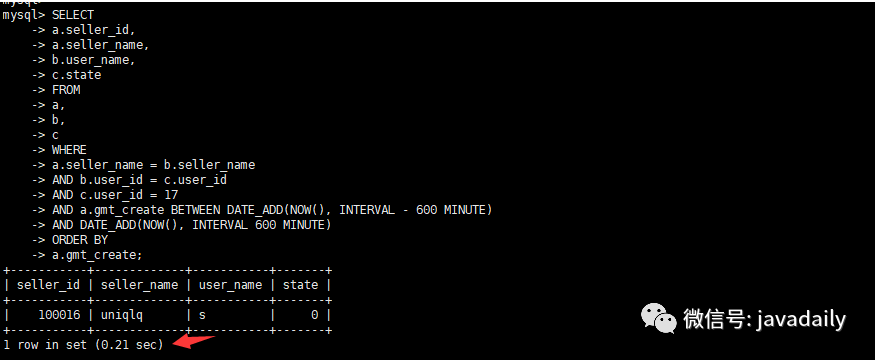
三张表关联,查询当前用户在当前时间前后10个小时的订单情况,并根据订单创建时间升序排列,具体SQL如下select a.seller_id,
a.seller_name,
b.user_name,
c.state
from a,
b,
c
where a.seller_name = b.seller_name
and b.user_id = c.user_id
and c.user_id = 17
and a.gmt_create
BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE)
AND DATE_ADD(NOW(), INTERVAL 600 MINUTE)
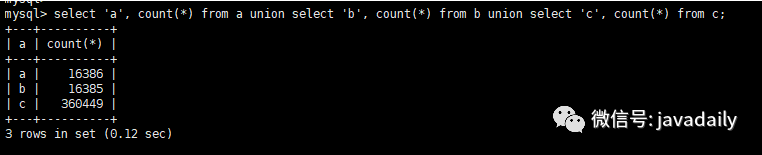
order by a.gmt_create;查看数据量
原执行时间
原执行计划
初步优化思路
SQL中 where条件字段类型要跟表结构一致,表中 user_id为varchar(50)类型,实际SQL用的int类型,存在隐式转换,也未添加索引。将b和c表user_id字段改成int类型。因存在b表和c表关联,将b和c表 user_id创建索引因存在a表和b表关联,将a和b表 seller_name字段创建索引利用复合索引消除临时表和排序 初步优化SQL
alter table b modify `user_id` int(10) DEFAULT NULL;
alter table c modify `user_id` int(10) DEFAULT NULL;
alter table c add index `idx_user_id`(`user_id`);
alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`);
alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);查看优化后执行时间
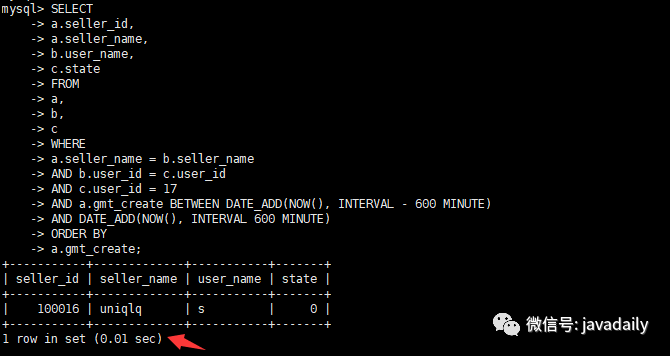
查看优化后执行计划
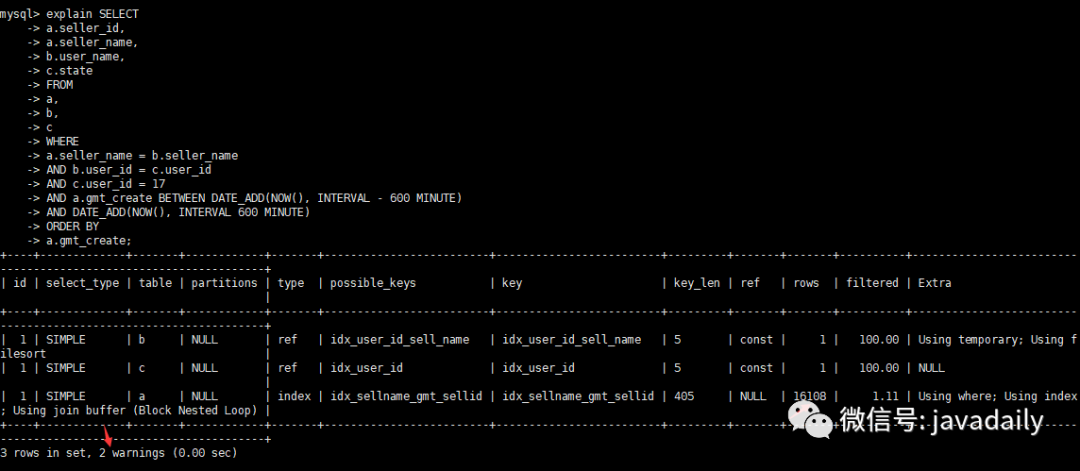
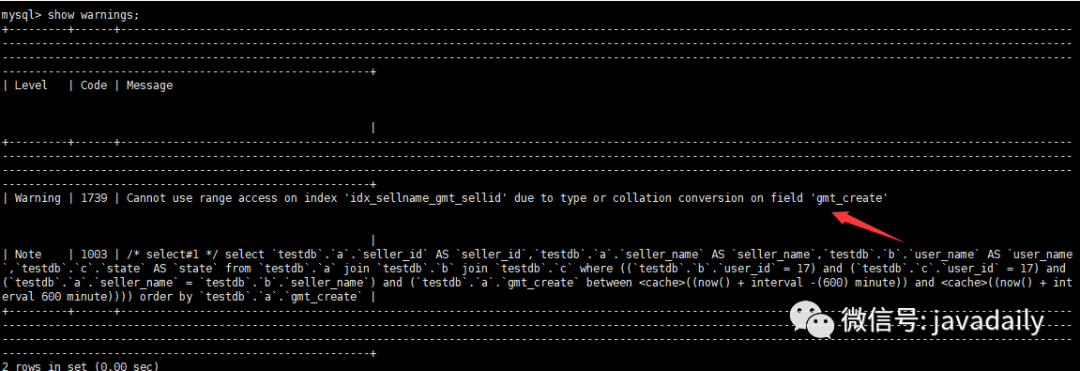
查看warnings信息
继续优化
alter table a modify "gmt_create" datetime DEFAULT NULL;查看执行时间
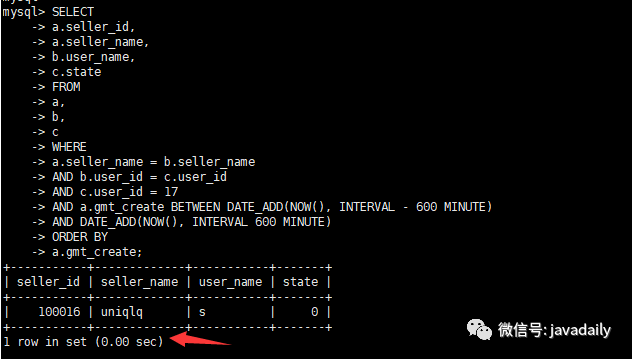
查看执行计划
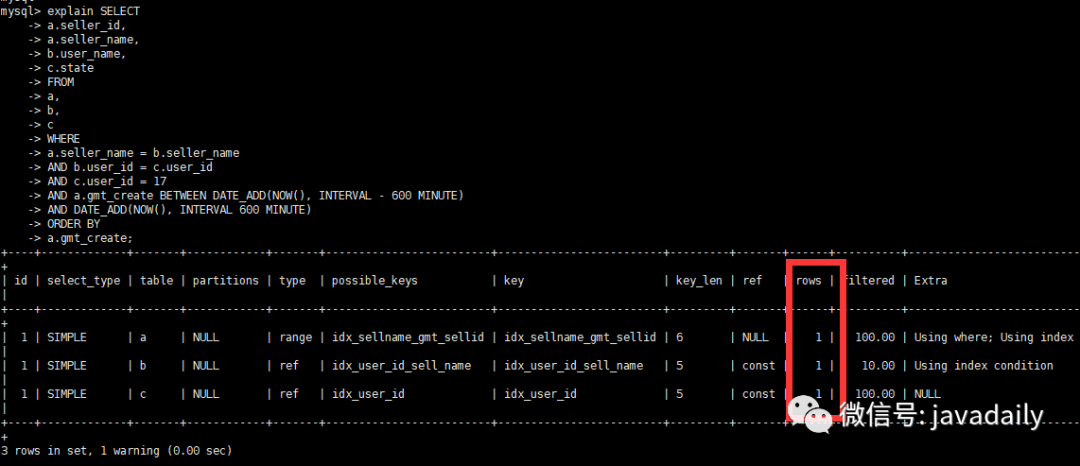 通过观察执行计划,到了这一步已经不再需要优化!
通过观察执行计划,到了这一步已经不再需要优化!优化总结
总结一下完成一段SQL优化的思路与过程:
1、查看执行计划 explain
2、如果有告警信息,查看告警信息 show warnings;
3、查看SQL涉及的表结构和索引信息
4、根据执行计划,思考可能的优化点
5、按照可能的优化点执行表结构变更、增加索引、SQL改写等操作
6、查看优化后的执行时间和执行计划
7、如果优化效果不明显,重复第四步操作
总结
这篇文章首先让你了解慢查询的表象,让你可以通过一些工具识别出慢查询语句;
然后告诉你SQL优化的一些常用套路技巧,掌握这些套路技巧至少可以解决80%的SQL优化问题;
最后通过一个示例从分析开始一步一步完成慢查询语句的优化,其中查看执行计划是优化过程中最终要的操作,大家一定要掌握。
程序汪资料链接
卧槽!字节跳动《算法中文手册》火了,完整版 PDF 开放下载!
卧槽!阿里大佬总结的《图解Java》火了,完整版PDF开放下载!
欢迎添加程序汪个人微信 itwang009 进粉丝群或围观朋友圈!