
学完了Python基础,你可以尝试这些方向
大家好我是蚂蚁,今天跟大家扯一扯闲篇,学完了Python基础,你其实可以学很多有意思的领域和方向。
从背景说起,Python真是门神奇有魅力的语言,确实简单易用,能证明这一点的就是:很多人只要学完了Python基础,就能参与真实项目开发,90%的代码甚至不用查资料,利用简单的if/for/while/函数就全部搞定了。
然而随着项目的需求变得复杂,很多人不知不觉的在重复的造轮子、从零写一些很多类库已经提供的功能,还记得刚入职场使用了Python一段时间之后,我开始写一些复杂点的代码,比如多数据的关联join、汇总统计、结果存入excel文件等等,尤其是对于多数据源(来自csv/txt/mysql)的关联join操作,自己从零开始用Python实现,比如把小文件加载到内存dict,遍历大文件去做dict查询实现JOIN,代码写起来刷刷的确实很爽。
然而有一天,当我发现这样多数据关联的需求,在spark、pandas等类库中就是一个简单现成的函数的时候,我简直激动地要哭出来,感叹为什么没有早点知道这些现成的技术。
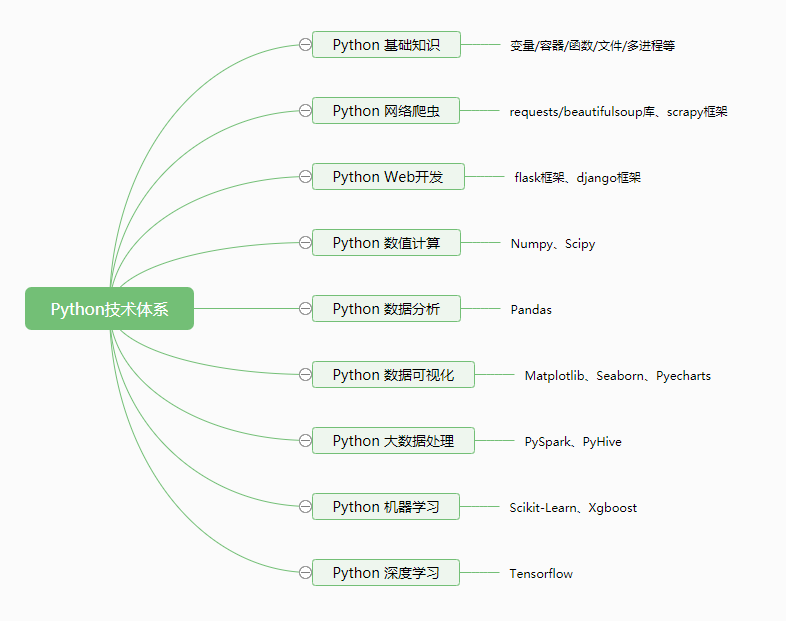
Python的类库真的很多,其中成体系的可以称之为“数据科学技术栈”,这么多的类库我觉得即使不都学一下,也要了解它们分别是做什么的,这样将来遇到类似的需求的时候不用从头自己实现。
以下是上方脑图中各技术的简单介绍:
1、Python 爬虫
代表技术为requests/beautifulsoup、scrapy、selenium
用于从网上爬取小说/文章/视频,实现数据分析或自己的内容聚集类应用。
2、Python Web开发
代表技术为flask、django、jinjia2
用于提供小程序、APP、网页等后台服务
3、Python 数值计算
代表技术为numpy、scipy,解决二维多维数据的向量化计算问题
当你学习机器学习/深度学习开始深入,发现大量的矩阵运算难以理解的时候,你得回头学习下Numpy这个技术
4、Python 数据分析
代表技术为pandas,这是我认为Python最牛逼的库,囊括了多数据源读取/写入、数据清洗/过滤/聚合/汇总/透视/时间序列等等大量的功能特性
5、Python 数据可视化
图表是数据分析领域的重要产出,你可能听过柱状图/饼图/折线图,但你可能没听过小提琴图/箱线图/直方图,这个领域知识体系其实也很庞大
代表技术为matplotlib/seaborn/pyecharts
6、Python 大数据处理
大数据领域,当前最成熟的技术应该是spark,而PySpark是Spark的Python工具包,使用这个库的好处是你可以无缝和numpy/pandas/绘图库对接,将大数据的结果进行最终的可视化分析(java/scala做不到这个)。
7、Python 传统机器学习
当前传统机器学习的巅峰技术是xgboost,而sklearn中提供大量的易用函数使它成为方便的“机器学习/深度学习的工具函数库”
8、Python深度学习
Tensorflow是工业界应用最多的深度学习框架,其2.0版本在代码易用性上能够与Pytorch对齐,但工业部署能力上仍然甩Pytorch一条街。
以上是我对Python几个应用领域类库的总结,古诗有云“君子性非异也、善假于物也”,牛逼的人可能有一点就是他们学的多、知道的多、会用的技能多。
如果本文对你有点帮助,顺手下方点个“在看”吧^_^