文字是传递信息的高效途径,利用OCR技术提取文本信息是各行业向数字智能化转型的第一步。与此同时,针对OCR提取的海量文本信息,利用NLP技术进一步加工提取、分析理解后才能最大化发挥文本信息的价值。NLP技术可以提升OCR准确率,并从文本中抽取关键信息、构建知识图谱,搭建检索、推荐、问答系统等。
虽然各行业智能化产业升级已经在如火如荼的开展中,但是在实际应用落地中却遇到诸多困难,比如:数据样本不够、模型精度不高、预测时延大等。为此,百度飞桨针对真实、高频的产业场景,提供了从数据准备、模型训练优化,到模型部署全流程的案例教程。
市面上有不少开源的OCR、NLP产品,但是如果想直接利用这些工具,会面临底层框架不统一、串联难度高、效果无法保证等问题。PaddleOCR和PaddleNLP是面向产业界的开发库,均基于飞桨开源框架最新版本,能够将OCR和NLP技术无缝结合。今天我们针对金融行业研报、物流快递单,来看看OCR + NLP信息抽取技术的应用。当前,诸多投资机构都通过研报的形式给出对于股票、基金以及行业的判断,让大众了解热点方向、龙头公司等各类信息。然而,分析和学习研报往往花费大量时间,研报数量的与日俱增也使得研报智能分析诉求不断提高。这里我们采用命名实体识别技术,自动抽取研报中的关键信息,例如,“中国银行成立于1912年。”中包含了组织机构、场景事件、时间等实体信息。针对研报数据的命名实体识别与词频统计整体流程如上图所示。首先将研报pdf数据使用fitz包拆分为图像格式,然后利用PaddleOCR套件在研报数据集上微调PP-OCR[1]的检测模型,使用现有的识别模型获得文本信息。PP-OCR是PaddleOCR中由百度自研的明星模型系列,由文本检测、文本方向分类器与文本识别模块串联而成。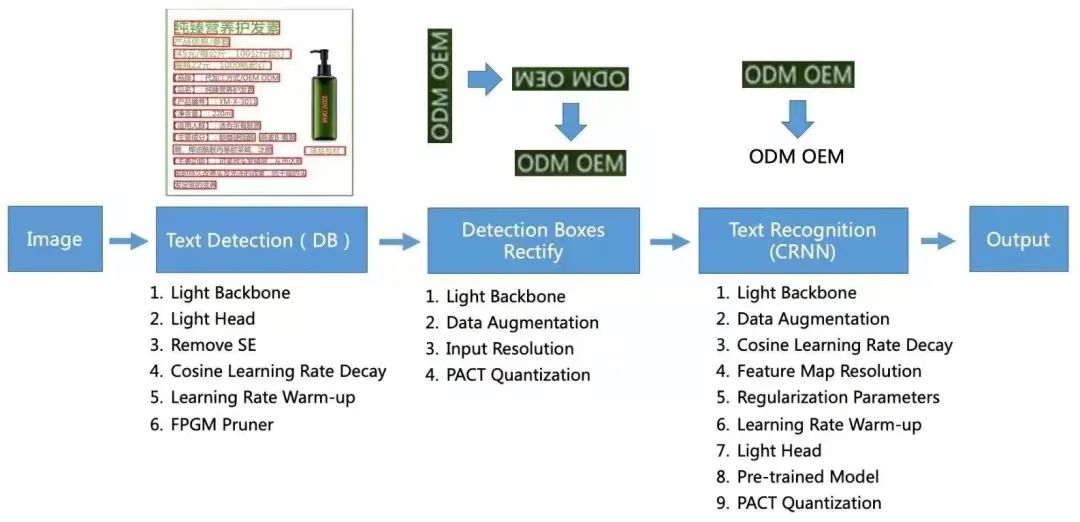
对OCR识别出的文本进行整理后,调用PaddleNLP中的Taskflow API抽取文本信息中的组织机构实体。最后对这些实体进行词频统计,就可初步判定当前研报分析的热点机构。

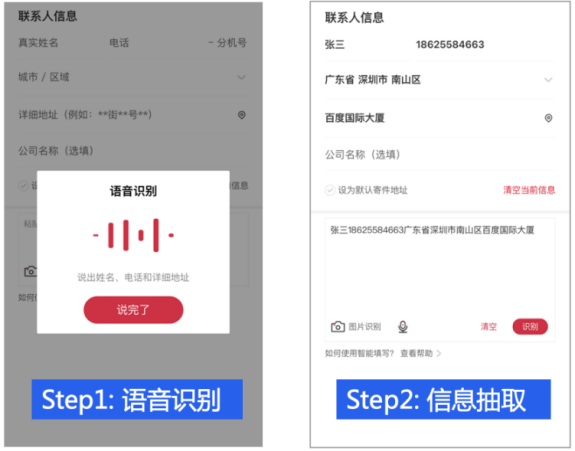
目前,Taskflow API 支持自然语言理解(NLU)和生成(NLG)两大场景共八大任务,包括中文分词、词性标注、命名实体识别、句法分析、文本纠错、情感分析、生成式问答和智能写诗,均可一键调用。双十一要到了,想必很多人都预备了一个满满的购物车。去年双十一成交量4982亿元,全国快递企业共处理快件39亿件,这背后则是物流行业工作量的骤增。除了满负荷的长深高速公路,还有繁忙的快递小哥。无论是企业业务汇总,还是寄件信息填写,都少不了关键信息智能提取这一环节,这其中均采用了命名实体识别技术。命名实体识别大体上有三种方案:字符串匹配、统计语言模型、序列标注。前两种方法需要预先构建词典、穷举所有实体,无法发现新词、变体等。本案例中采用了目前的主流方法——序列标注。数据集包括1600条训练集,200条训练集和200条测试集,采用BIO体系进行标注。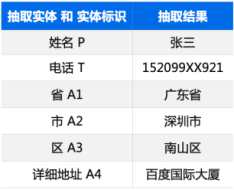
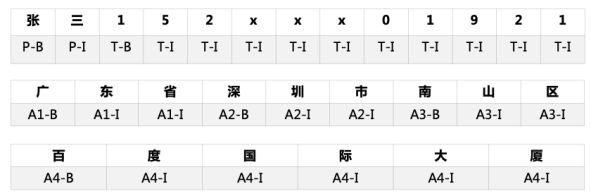
实体定义和数据集标注示例
针对轻量化、高精度的需求,可以选用RNN+CRF 方案。也可以采用预训练模型,通过模型压缩、动转静加速等方式满足精度和性能的要求。我们采用Ernie-Gram[2] + CRF 获得了最佳效果。此外,命名实体识别技术可以应用于各类关键信息的提取,例如电商评论中的商品名称、电子发票中的抬头信息、收入证明中的金额、法律文书中的犯罪地点等信息。结合关系抽取、事件抽取技术,还可以构建知识图谱、搭建问答系统等。为了便于大家更熟练地使用这些案例教程,百度高工将于10月26-28日围绕四大行业、八大真实场景亲授产业实践案例课,欢迎小伙伴们锁定我们的直播间,来和我们交流吧!扫码报名直播课,立即加入技术交流群
精彩内容抢先看
- 官网地址:https://www.paddlepaddle.org.cn
- PaddleOCR 项目地址:https://github.com/PaddlePaddle/PaddleOCR
- PaddleNLP 项目地址:https://github.com/PaddlePaddle/PaddleNLP
[1] PP-OCR: A Practical Ultra Lightweight OCR System(https://arxiv.org/pdf/2009.09941.pdf)[2] ERNIE-Gram: Pre-Training with Explicitly N-Gram Masked Language Modeling for Natural Language Understanding(https://arxiv.org/pdf/2010.12148.pdf)