
Google AI:AlphaGo启发,教你用ML击败对手的chimera

新智元报道
新智元报道
来源:Google AI
编辑:小匀、LQ
【新智元导读】近年来,多人在线游戏越来越流行,全世界有数百万玩家。随着这种游戏的大规模流行,玩家对游戏设计者的要求也越来越高,玩家都喜欢精心设计的游戏,毕竟,只用一个策略就能击败所有人的游戏也没什么意思。
为了设计出积极的游戏体验,游戏设计师通常会反复调整游戏:
通过测试玩家的数千次测试进行压力测试; 整合反馈并重新设计游戏; 重复步骤1和步骤2,直到玩家和游戏开发者都满意为止。
数字纸牌游戏原型Chimera
数字纸牌游戏原型Chimera

玩家可以:
怪兽:攻击或被攻击 咒语/法术:产生特效
怪兽被召唤到有限的生物群落中,这些生物群落被实际放置在游戏空间上。每个怪兽都有自己喜欢的群落,如果被放置在错误的群落或容量过大的群落上,会重复受到伤害。
玩家控制一个单个chimera,chimera一开始是基本的 「蛋 」状态,可以通过吸收怪兽进行进化和强化。为此,玩家还必须获得一定数量的链接能量,而链接能量是由各种游戏机制产生的。
当玩家成功将对方chimera的健康值降至0时,游戏结束。
Chimera怎么玩
Chimera怎么玩
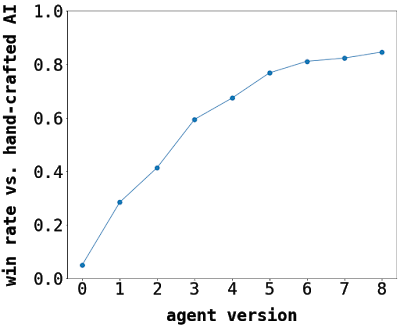
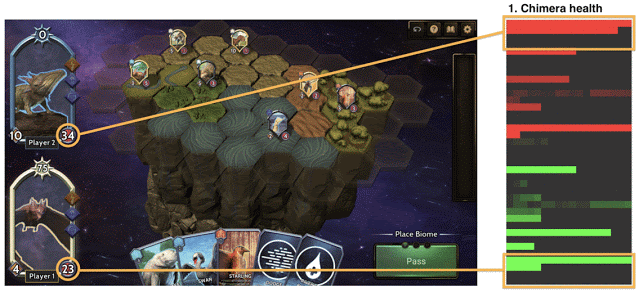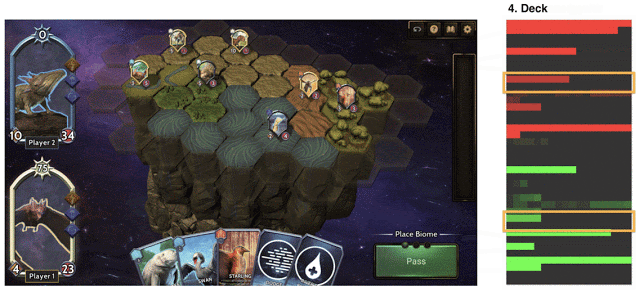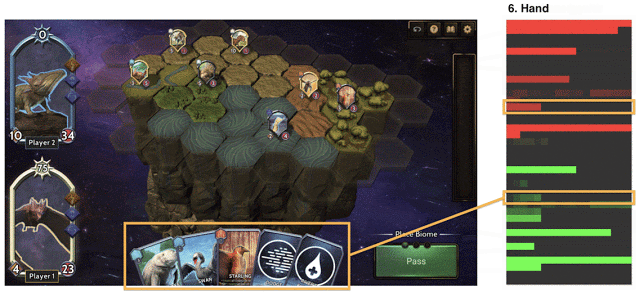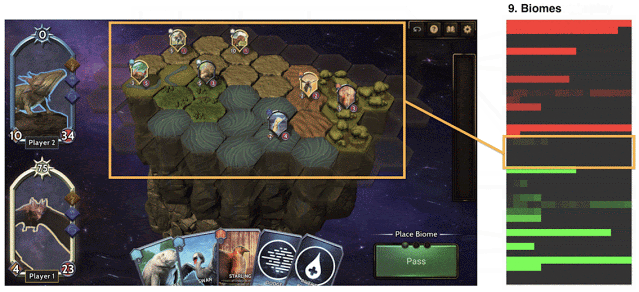
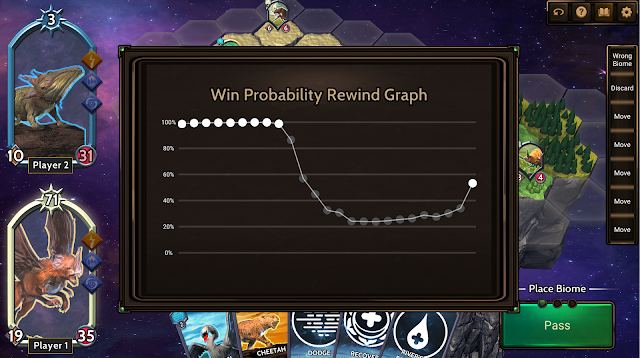
平衡Chimera
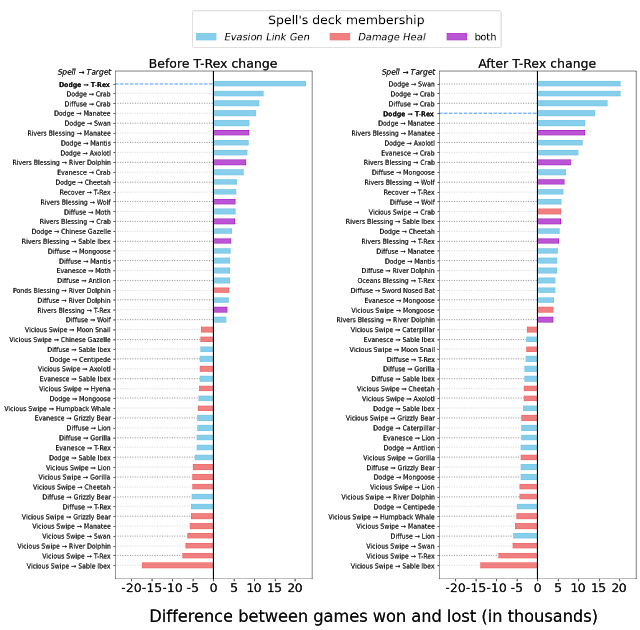

结论
参考资料:
https://ai.googleblog.com

评论