
360度无死角 | Pulsar与Kafka对比全解析


2020 年,Pulsar 受到持续关注,Pulsar 的应用场景也越来越广泛。
本文分别从性能、架构和功能方面比较 Pulsar 和 Kafka 的区别,并且介绍 Pulsar 的用例、支持与社区等。
>>> 组件
Pulsar 有 3 个重要组件:broker、Apache BookKeeper 和 Apache ZooKeeper。Broker 是无状态服务,客户端需要连接到 broker 进行核心消息传递。而 BookKeeper 和 ZooKeeper 是有状态服务。
BookKeeper 节点(bookie)存储消息和游标,ZooKeeper 则只用于为 broker 和 bookie 存储元数据。另外,BookKeeper 使用 RocksDB 作为内嵌数据库,用于存储内部索引,但不能独立于 BookKeeper 单独管理 RocksDB。
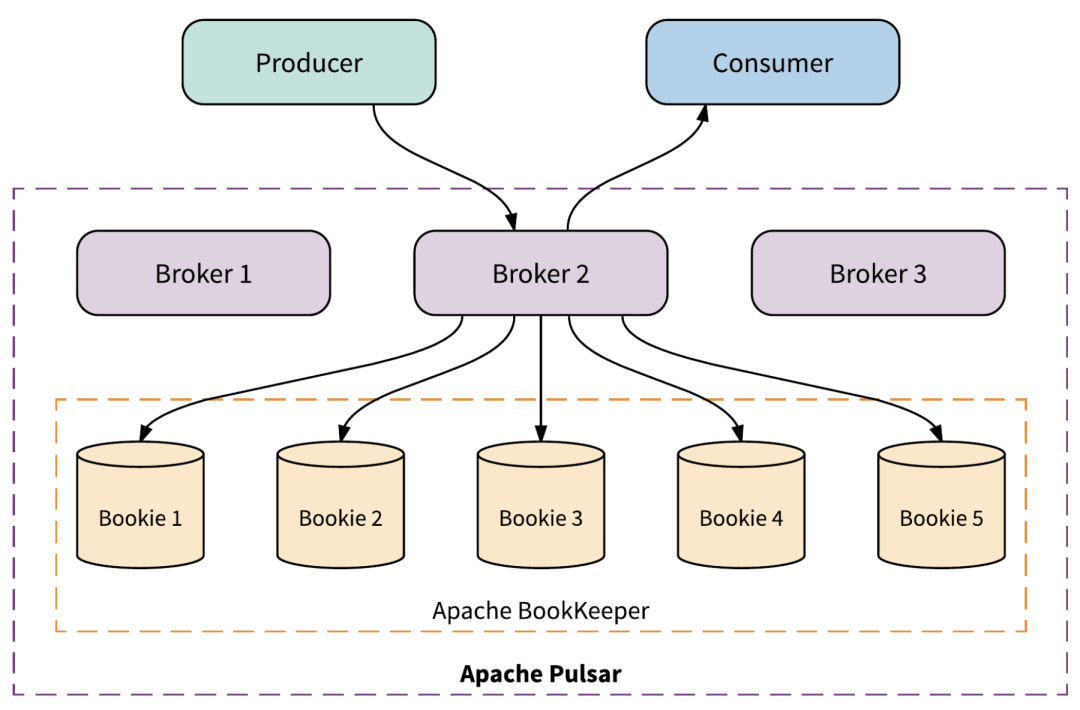
Kafka 采用单片架构模型,将服务与存储紧密结合,而 Pulsar 采用了多层架构,各层可以单独管理。Pulsar 在 broker 计算层进行计算,在 bookie 存储层管理有状态存储。
表面上来看,Pulsar 的架构似乎比 Kafka 的架构更为复杂,但实际情况并非如此。架构设计需要权衡利弊,Pulsar 采用了 BookKeeper,因此伸缩性更灵活,速度更快,性能更一致,运维开销更小。后文,我们会详细讨论这几个方面。
>>> 存储架构
Pulsar 的多层架构影响了存储数据的方式。Pulsar 将 topic 分区划分为分片(segment),然后将这些分片存储在 Apache BookKeeper 的存储节点上,以提高性能、可伸缩性和可用性。
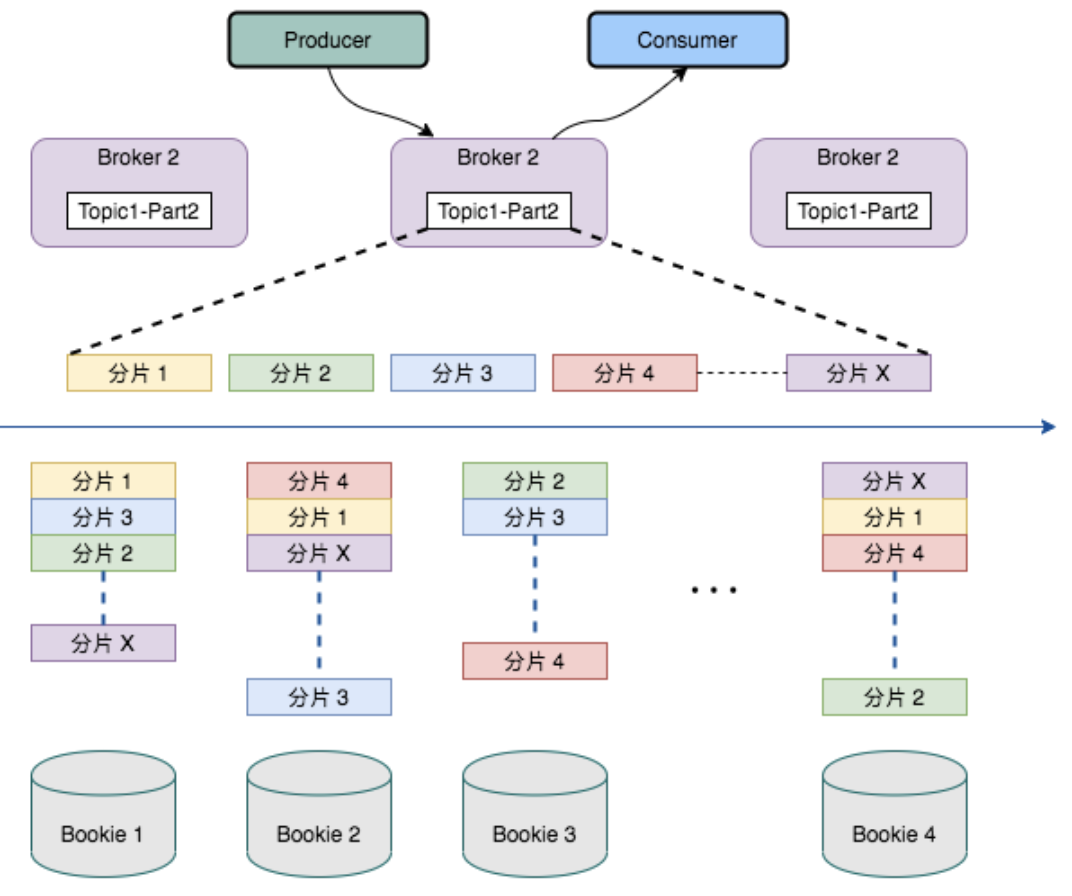
Pulsar 的无限分布式日志以分片为中心,借助扩展日志存储(通过 Apache BookKeeper)实现,内置分层存储支持,因此分片可以均匀地分布在存储节点上。由于与任一给定 topic 相关的数据都不会与特定存储节点进行捆绑,因此很容易替换存储节点或缩扩容。另外,集群中最小或最慢的节点也不会成为存储或带宽的短板。
Pulsar 架构能实现分区管理,负载均衡,因此使用 Pulsar 能够快速扩展并达到高可用。这两点至关重要,所以 Pulsar 非常适合用来构建关键任务服务,如金融应用场景的计费平台,电子商务和零售商的交易处理系统,金融机构的实时风险控制系统等。
通过性能强大的 Netty 架构,数据从 producers 到 broker,再到 bookie 的转移都是零拷贝,不会生成副本。这一特性对所有流应用场景都非常友好,因为数据直接通过网络或磁盘进行传输,没有任何性能损失。
Pulsar 的消费模型采用了流拉取的方式。流拉取是长轮询的改进版,不仅实现了单个调用和请求之间的零等待,还可以提供双向消息流。通过流拉取模型,Pulsar 实现了端到端的低延迟,这种低延迟比所有现有的长轮询消息系统(如 Kafka)都低。
>>> 运维简单
在评估特定技术的操作简便性时,不仅要考虑初始设置,还要考虑长期维护和可伸缩性。需要考虑以下几项:
要跟上业务增长的速度,扩展集群是否快速、方便?
集群是否对多租户(对应于多团队、多用户)开箱可用?
运维(如替换硬件)是否会影响业务的可用性与可靠性?
是否可以轻松复制数据以实现数据的地理冗余或不同的访问模式?
长期使用 Kafka 的用户发现维护 Kafka 时,以上这些都很难做到。多数任务需要借助 Kafka 之外的工具,如用于管理集群再平衡的 cruise control,以及用于复制需求的 Kafka mirror-maker。
由于 Kafka 很难在不同的团队间共享,很多机构开发了用于支持和管理多个不同集群的工具。这些工具对大规模应用 Kafka 至关重要,但同时也增加了 Kafka 的复杂性。最适合管理 Kafka 集群的工具都是商业软件,不开源。那这就不意外了,囿于 Kafka 复杂的管理和运维,许多企业转而购买 Confluent 的商业服务。
相比之下,Pulsar 的目标是简化运维和可扩展。根据 Pulsar 的性能,对以上问题,我们回复如下:
Q:要跟上业务增长的速度,扩展集群的操作是否迅速便捷?
A:Pulsar 有自动负载均衡的能力,集群中新增了计算和存储节点,可以自动、立即投入使用。这样 broker 之间可以迁移 topic 来平衡负载,新 bookie 节点可以立即接受新数据分片的写入流量,无需手动重新平衡或管理 broker。
Q:集群是否对多租户(对应于多团队、多用户)开箱可用?
A:Pulsar 采用分层架构,租户和命名空间能够与机构或团队形成良好的逻辑映射,Pulsar 通过这种相同的机构支持简易 ACL、配额、自主服务控制,同时也支持资源隔离,因此集群使用者可以轻松管理、共享集群。
Q:运维任务(如替换硬件)是否会影响业务的可用性与可靠性?
A:Pulsar 的 broker 是无状态的,替换操作简单,无需担心数据丢失。Bookie 节点会自动复制全部未复制的数据分片,而且用于解除和替换节点的工具为内置工具,很容易实现自动化。
Q:是否可以轻松复制数据以实现数据的地理冗余或不同的访问模式?
A:Pulsar 具有内置的复制功能,可用于无缝跨地域同步数据或复制数据到其他集群,以实现其他功能(如灾备、分析等)。
和 Kafka 相比,Pulsar 为流数据的现实问题提供了更完善的解决方案。从这个角度看,Pulsar 拥有更完善的核心功能集,使用简单,因而允许使用者和开发者专注于业务的核心需求。
>>> 生态集成
随着 Pulsar 应用场景的迅速增加,Pulsar 社区发展壮大,全球用户高度参与。Pulsar 社区活跃,积极推动 Pulsar 生态系统的集成应用。过去的六个月,Pulsar 生态系统中官方支持的 connector 数量急剧增长。
为了进一步支持 Pulsar 社区的发展,StreamNative 推出了 StreamNative Hub。StreamNative Hub 支持用户搜索、下载集成应用,会进一步加速 Pulsar connector 和插件生态系统的发展。
https://hub.streamnative.io/
Pulsar 社区一直与其他社区密切合作,共同开发一系列集成项目,目前多个项目仍在进行中。已经完成的项目如:
Pulsar 社区与 Flink 社区共同开发的 Pulsar-Flink Connector(FLIP-72 的一部分)。
https://github.com/streamnative/pulsar-flink
通过 Pulsar-Spark Connector,用户可以使用 Apache Spark 处理 Apache Pulsar 中的事件。
https://github.com/streamnative/pulsar-spark
SkyWalking Pulsar 插件集成了 Apache SkyWalking 和 Apache Pulsar,用户可以通过 SkyWalking 追踪 Pulsar 消息。
https://github.com/apache/skywalking/tree/master/apm-sniffer/apm-sdk-plugin/pulsar-plugin
>>> 多元客户端库
目前,Pulsar 官方客户端支持 7 种语言,而 Kafka 只支持 1 种语言。Confluent 发布博客声称 Kafka 目前支持 22 种语言,然而其官方客户端并不支持这么多种语言,而且有些语言已经不再维护。
根据最新统计,Apache Kafka 官方客户端只支持 1 种语言。
https://github.com/apache/kafka/tree/trunk/clients/src/main/java/org/apache/kafka/clients
而 Apache Pulsar 官方客户端支持 7 种语言。
http://pulsar.apache.org/docs/en/client-libraries/
Java
C
C++
Python
Go
.NET
Node
Pulsar 还支持由 Pulsar 社区开发的诸多客户端,如:
Rust
Scala
Ruby
Erlang
>>> 吞吐量、延迟与容量
Pulsar 和 Kafka 都被广泛用于各个企业,也各有优势,都能通过数量基本相同的硬件处理大流量。部分用户误以为 Pulsar 使用了很多组件,因此需要很多服务器来实现与 Kafka 相匹敌的性能。这种想法适用于一些特定硬件配置,但在多数资源配置相同的情况中,Pulsar 的优势更加明显,可以用相同的资源实现更好的性能。
举例来说,Splunk 最近分享了他们选择 Pulsar 放弃 Kafka 的原因,其中提到“由于分层架构,Pulsar 帮助他们将成本降低了 30% - 50%,延迟降低了 80% - 98%,运营成本降低了 33% - 50%”。
https://www.slideshare.net/streamnative/why-splunk-chose-pulsarkarthik-ramasamy(参考幻灯片第 34 页)
Splunk 团队发现 Pulsar 可以更好地利用磁盘 IO,降低 CPU 利用率,同时更好地控制内存。
腾讯等公司选择 Pulsar 在很大程度上是因为 Pulsar 的性能。在腾讯计费平台白皮书中提到,腾讯计费平台拥有百万级用户,管理约 300 亿第三方托管账户,目前正在使用 Pulsar 处理日均数亿美元的交易。
https://streamnative.io/whitepaper/case-study-apache-pulsar-tencent-billing
考虑到 Pulsar 可预测的低延迟、更强的一致性和持久性保证,腾讯选择了 Pulsar。
>>> 有序性保证
Apache Pulsar 支持四种不同订阅模式。单个应用程序的订阅模式由排序和消费可扩展性需求决定。以下为这四种订阅模式及相关的排序保证。
独占(Exclusive)和灾备(Failover)订阅模式都在分区级别支持强序列保证,支持跨 consumer 并行消费同一 topic 上的消息。
共享(Shared)订阅模式支持将 consumer 的数量扩展至超过分区的数量,因此这种模式非常适合 worker 队列应用场景。
键共享(Key_Shared)订阅模式结合了其他订阅模式的优点,支持将 consumer 的数量扩展至超过分区的数量,也支持键级别的强序列保证。
更多关于 Pulsar 订阅模式和相关排序保证的信息,可以参阅:
http://pulsar.apache.org/docs/en/concepts-messaging/#subscriptions
>>> 内置流处理
Pulsar 和 Kafka 对于内置流处理的目标不尽相同。针对较为复杂的流处理,Pulsar 集成了 Flink 和 Spark 这两套成熟的流处理框架,并开发了 Pulsar Functions 来处理轻量级计算。Kafka 开发并使用 Kafka Streams 作为流处理引擎。
Kafka Streams 异常复杂,用户要将其作为流处理引擎,需要先弄清楚使用 KStreams 应用程序的场景及方法。对大多数轻量级计算应用场景来说,KStreams 过于复杂。
而 Pulsar Functions 轻松实现了轻量级计算,并允许用户创建复杂的处理逻辑,无需单独部署其他系统。Pulsar Functions 还支持原生语言和易于使用的 API。用户不必学习复杂的 API 就可以编写事件流应用程序。
最近,Pulsar 改进方案(Pulsar Improvement Proposal,PIP)中介绍了 Function Mesh。Function Mesh 是无服务器架构的事件流框架,结合使用多个 Pulsar Functions 以便构建复杂的事件流应用程序。
>>> Exactly-Once 处理
目前,Pulsar 通过 broker 端去重支持 exactly-once producer。这个重大项目正在开发中,敬请期待!
https://github.com/apache/pulsar/wiki/PIP-6:-Guaranteed-Message-Deduplication
PIP-31 提议 Pulsar 支持事务型消息流,目前正在开发中。这一特性提高了 Pulsar 的消息传递语义和处理保证。
https://github.com/apache/pulsar/wiki/PIP-31:-Transaction-Support
在交易型消息流中,每条消息只会写入一次、处理一次,即便 broker 或 Function 实例出现故障,也不会出现数据重复或数据丢失。交易型消息不仅简化了使用 Pulsar 或 Pulsar Functions 向应用程序写入的操作,还扩展了 Pulsar 支持的应用场景。
如果开发顺利,Pulsar 2.7.0 版本会支持事务型消息流,预计 2020 年 11 月发布。
>>> Topic(日志)压缩
Pulsar 支持用户根据需要选择数据格式来消费数据。应用程序可以根据需要选择使用原始数据或压缩数据。通过按需选择的方式,Pulsar 允许未压缩数据通过保留策略,控制数据无限增长,同时通过周期性压缩生成最新的实物化视图。内置的分层存储特性支持 Pulsar 从 BookKeeper 卸载未压缩数据到云存储中,从而降低长期存储的成本。
而 Kafka 不支持用户使用原始数据。并且,在数据压缩后,Kafka 会立即删除原始数据。
雅虎最初开发 Pulsar 将其用作统一的发布/订阅消息平台(又称云消息)。现在,Pulsar 不仅是消息平台,还是消息和事件流的统一平台。Pulsar 引入了一系列工具,作为平台的一部分,为构建事件流应用程序提供必要的基础。Pulsar 支持以下事件流功能:
无限事件流存储支持通过向外扩展日志存储(通过 Apache BookKeeper)大规模存储事件,并且 Pulsar 内置的分层存储支持高质量、低成本的系统,如 S3、HDFS 等。
统一的发布/订阅消息模型方便用户向应用程序中添加消息。这一模型可以根据流量和用户需求进行伸缩。
协议处理框架、Pulsar 与 Kafka 的协议兼容性(KoP),以及 AMQP (AMQP-on-Pulsar)支持应用程序使用任何现有协议在任一位置生产和消费事件。
Pulsar IO 提供了一组与大型生态系统集成的 connector,用户不需要编写代码,即可从外部系统获取数据。
Pulsar 与 Flink 的集成可以全面处理复杂的事件。
Pulsar Functions 是一个轻量级无服务器框架,能够随时处理事件。
Pulsar 与 Presto 的集成(Pulsar SQL),数据专家和开发者能够使用 ANSI 兼容的 SQL 来分析数据和处理业务。
>>> 消息路由
通过 Pulsar IO、Pulsar Functions、Pulsar Protocol Handler,Pulsar 具有完善的路由功能。Pulsar 的路由功能包括基于内容的路由、消息转换和消息扩充。
和 Kafka 相比,Pulsar 的路由能力更稳健。Pulsar 为 connector 和 Functions 提供了更灵活的部署模型。可以在 broker 中简单部署,也可以在专用的节点池中部署(类似于 Kafka Streams),节点池支持大规模扩展。Pulsar 还与 Kubernetes 原生集成。另外,可以将 Pulsar 配置为以 pod 的形式来调度 Functions 和 connector 的工作负载,充分利用 Kubernetes 的弹性。
>>> 消息队列
如前文所述,Pulsar 最初的开发目的是作为统一的消息发布/订阅平台。Pulsar 团队深入研究了现有开源消息系统的优缺点,凭借丰富的经验,设计了统一的消息模型。
Pulsar 消息 API 结合队列和流的能力,不仅实现了 worker 队列以轮询的方式将消息发送给相互竞争的 consumer(通过共享订阅),还支持事件流:一是基于分区(通过灾备订阅)中消息的顺序;二是基于键范围(通过键共享订阅)中消息的顺序。用户可以在同一组数据上构建消息应用程序和事件流应用程序,而无需复制数据到不同的数据系统。
另外,Pulsar 社区还在尝试使 Apache Pulsar 原生支持不同的消息协议(如 AoP、KoP、MoP),以扩展 Pulsar 处理消息的能力。
Pulsar 社区发展迅猛,随着 Pulsar 技术的发展和应用场景的增加,Pulsar 生态也在日益壮大。
Pulsar 具有许多优势,在统一的消息和事件流平台脱颖而出,成为大众选择。和 Kafka 相比,Pulsar 弹性更灵活,在运维和扩展上更为简单。
新技术的推出和采用都需要一些时间,Pulsar 不仅提供了全套解决方案,安装后可立即投入生产环境,维护成本低。Pulsar 涵盖了构建事件流应用程序所需的基础,集成了丰富的内置功能(包括各种工具)。Pulsar 工具不需要单独安装,即可立即使用。
在上面文章中,我们从技术角度对比 Pulsar 和 Kafka,讨论二者在性能、架构、功能等方面的差异。在这部分,我们通过分析研究 Pulsar 的使用案例,从商业角度对比 Pulsar 与 Kafka。
简介
Pulsar 扩展灵活、操作简单,能够在单个平台内实现消息队列和数据管道两种功能。因此,越来越多的企业开始采用 Pulsar 来处理消息队列和数据管道业务。Pulsar 提供统一的消息平台、构建流优先的应用程序等(这些独特的功能都是企业急需的),为众多业界领先的科技公司提供支持。
由于 Pulsar 是一项较新的技术,很多用户不太熟悉 Pulsar 的功能。本文将会解答一些关于 Pulsar 的常见疑问,分享 Pulsar 在多个领域迅速增长的用例,介绍 Pulsar 快速扩展的社区。另外,本文还会讨论采用新技术带来的风险,以及为什么现有技术无法适应瞬息万变的环境。
首先,我们来了解一下关于 Pulsar 的常见问题。
1: Pulsar 技术的成熟度是多少?是否在实际应用程序中测试过 Pulsar?
为了更好地了解 Pulsar 的成熟度和使用情况,我们先来介绍一下 Pulsar 的起源和发展背景。
Kafka 由领英团队开发,2011 年开源,并于 2012 年成为 Apache 的顶级项目。作为市场上第一个主要的事件流平台,Kafka 具备很高的知名度并广泛用于各个行业。Confluent 等诸多公司为 Kafka 提供企业级支持。与 Pulsar 相比,Kafka 更成熟、更流行,拥有更大的社区和更完善的生态系统。
在过去的 18 个月里,Pulsar 的用户和社区迅猛增长。在全球范围内,越来越多的媒体公司、科技公司、金融机构都在使用 Pulsar。以下是一些企业级用例。这些用例足以证明 Pulsar 处理关键任务应用程序的能力。
腾讯基于 Pulsar 搭建计费平台
Midas 是孵化于支撑腾讯内部业务千亿级营收的互联网计费平台,运营规模庞大,每天处理交易金额高达上百亿,日数据量达到 10+ TB。对于年收入超过 500 亿美元的腾讯来说,计费系统是其基础架构的关键组件。腾讯在计费平台 Midas 中使用 Pulsar 充分证明了 Pulsar 处理关键任务应用程序的能力,也证明了 Pulsar 的技术经得住严格测试,可以在严苛要求的环境下表现优异。
Verizon Media 在生产环境中使用 Pulsar 长达 5 年
Verizon Media 在生产环境中使用 Pulsar 长达 5 年,这是一个备受关注的例子。Verizon Media 收购雅虎后,成为 Pulsar 的最初开发者。在今年 6 月举办的 Pulsar Summit上,Verizon Meida 的 Joe Francis 和 Ludwig Pummer 提到整个 Verizon Media 平台都在使用 Pulsar,并称赞 Pulsar 是经过“实践检验”的系统。在 Verizon Media,Pulsar 支撑了 280+ 万个 topic,每秒处理 300+ 万次读写请求。Pulsar 不仅满足 Verizon Media 对低延迟、高可用、易扩展的要求,而且能够同时支持全球六个数据中心运营的业务。
Splunk 将 Pulsar 用于其数据流处理器
Splunk 也分享了他们的应用场景。多年来,Splunk 的生产环境一直使用 Kafka。在今年 6 月的 Pulsar Summit 上,Splunk 总监 Karthik Ramasamy 分享了“为什么 Splunk 选择了 Pulsar[3]”,介绍 Splunk 选择 Pulsar 支持其下一代分析产品 Splunk DSP 的原因。Splunk DSP 每天需要处理数十亿事件,Pulsar 不仅能满足 Splunk DSP 的 18 项关键需求,还具有易于扩展、运营成本低、性能好、开源社区强大等特点。
以上案例说明 Pulsar 功能非常强大。许多行业领军企业都选择用 Pulsar 支持关键业务的基础结构。尽管 Kafka 更成熟,使用范围更广,但 Pulsar 迅速增长的用户数量证实了 Pulsar 在性能方面的优势以及处理关键任务的能力。
2: Pulsar 与其竞争技术之间的主要差别是什么?每种技术的特有优势是什么?
虽然一些大型技术公司和媒体公司(如 Uber 和 Netfilix)通过构建统一的批和流处理平台以及流优先应用程序,实现了实时数据的需求,但大多数公司仍然缺少开发和维护这些应用程序所需的开发人员及财务支持。Pulsar 提供了先进的消息处理能力来帮助这些公司克服开发类似平台的难题。
接下来,我们将重点介绍 Pulsar 区别于其竞争对手的三种独特功能。这三种功能,有些已经实现,有些正在开发中。
统一的消息模型
目前,最常见的两种消息类型为应用程序消息(传统的队列系统)和数据管道。应用程序消息支持异步通信(通常在 RabbitMQ、AMQP、JMS 等平台上开发),而数据管道则用于不同系统(如 Apache Kafka 或 AWS Kinesis)之间传输大量数据。由于这两类消息运行在不同的系统上,并且提供的功能也不尽相同,因此多数企业一般都需要同时运行两套系统。开发、管理不同的系统不仅成本高、操作复杂,还会增大集成系统和整合数据的难度。
Pulsar 的核心技术支持用户同时将其部署为传统队列系统和数据管道,因此 Pulsar 成为独一无二的统一消息功能的理想平台。对企业而言,统一的消息简化了抓取和分发数据的操作,从而可以通过使用实时数据推动业务创新。
最近,Pulsar 还支持 KoP(Kafka-on-Pulsar),AoP(AMQP-on-Pulsar)和 MoP(MQTT-on-Pulsar)插件。通过这些插件,企业可以更方便地利用统一消息的功能。(我们将在下文中详细讨论 KoP,AoP 和 MoP。)
批存储和事件流存储
越来越多的企业需要及时做出决策,并迅速对变化作出反应,因此企业非常重视重要的实时数据。另外,集成、理解大量历史数据对展示业务的整体概况也至关重要。
传统的大数据系统(如 Hadoop)支持分析大量历史数据,从而帮助企业做出决策。但是,这些系统需要几分钟、几小时,甚至是几天的时间来处理数据,因此很难集成实时数据,并且分析结果也存在一定的不足。
流处理器(如 Kafka Streams)擅长处理流数据,获得接近实时数据的分析结果,但不太适合处理大量历史数据集。许多企业需要同时运行批处理器和流数据处理器,以便及时感知业务变化。但维护多个系统费用昂贵,而且各个系统之间也难以兼容。
目前,有些系统可以同时进行批处理和流处理,如 Apache Flink。Kafka 和 Pulsar 都可以使用 Flink 进行流处理,但 Flink 的批处理能力与 Kafka 并非完全兼容。Kafka 只能以流交付数据,所以 Kafka 处理批处理工作负载的速度较慢。
相比之下,Pulsar 的分层存储模型提供批存储功能,可以支持 Flink 进行批流处理。目前,Pulsar 社区正在开发 Pulsar Flink connector[4],集成 Flink 和 Pulsar 的功能。使用 Pulsar Flink connector,企业可以更轻松地查询历史数据和实时数据,增强竞争优势。
“流优先”应用程序
企业软件开发越来越复杂,这推动了 Web 应用程序开发发生重大转变,由传统的与大型 SQL 数据库配对的单一应用程序转向由多个较小组件或“微服务”组成的应用程序。
许多企业都选择了微服务,因为微服务更具灵活性,更适用于不断变化的业务需求,同时还可以促进多个开发团队之间的合作。但是,微服务也引入了新的挑战,如需要支持多个组件之间的通信,并保持同步等。
通过名为“事件源”的新型微服务技术,应用程序生产并广播事件流到共享消息系统中。共享消息系统可以在集中的日志中获取事件历史记录。这一技术不仅改善了数据流,还保持了应用程序之间的同步性。
但是事件源既需要传统的消息功能,又需要长期存储事件历史的能力,因此实现起来非常困难。虽然 Kafka 可以存储事件流数天或数周,事件源通常需要更长的留存时间。因此,用户不得不构建多层 Kafka 集群来管理不断增长的事件数据,还要构建额外的系统来共同管理和追踪数据。
相比之下,Pulsar 统一的消息模型自然成为了最优选择,Pulsar 不仅可以轻松地分发事件到其他组件,还可以有效地、无限期地存储事件流。对于需要动态、流优先处理能力的公司来说,Pulsar 的这一独特设计尤为重要。
虽然其他系统也可以实现统一的消息、批流存储、“流优先”方法等,但实现这些功能并不容易,需要投入大量的时间、精力和资金。而 Pulsar 的设计不仅包含上述特性,还操作简单,帮助用户轻松适应不断变化的技术环境。
3: 是否有社区和企业支撑 Pulsar 开发和技术支持?
对比 Pulsar 与 Kafka 社区现状,我们看到,Kafka 社区更大,Slack 用户更多,StackOverflow 上的问题也更多。目前,Pulsar 社区相对较小,但社区成员非常活跃,社区发展迅猛。以下是 Pulsar 的近期活动。
Pulsar 的首次全球峰会
今年 6 月,Pulsar 首次举办全球峰会[5],即 2020 年 Pulsar Summit Virtual Conference[6]。此次会议中,Pulsar 社区的顶级贡献者、社区领导、开发人员分享了 30 多场演讲,深入介绍了 Pulsar 在不同行业的应用场景和最佳实践等。Verizon Media[7]、Splunk[8]、Iterable[9]、OVHcloud[10] 等公司就 Pulsar 发表了深刻、独到的见解。
六百多人报名参加了这次峰会。参会者来自各行各业,覆盖顶级互联网公司、科技和金融机构,如谷歌、微软、AMEX、Salesforce、迪士尼、Paypal 等。此次峰会让人们看到 Pulsar 全球社区的高度参与,Pulsar 的关注度日益增长。
峰会结束后,Pulsar 的全球社区立刻联系我们要求举办 Pulsar 亚洲峰会和欧洲峰会。为了满足社区日益增长的需求,我们计划在今年 11 月底举办 Pulsar 亚洲峰会,欧洲峰会仍在筹划中(备注:Pulsar 亚洲峰会已在 11 月 28-29 日举办)。
社区支持 - 培训和活动
除了举办大型、广泛参与的峰会外,Pulsar 社区还专注于交互式培训和线上活动。今年年初, StreamNative 主导社区推出了每周一次的线上直播 TGIP(全称为 “Thank Goodness It’s Pulsar”)。这种交互式教程不只包含技术更新,还强调实践操作。TGIP 视频发布在 StreamNative 官网、YouTube、B 站等多个平台,以扩充 Pulsar 的现有资源。
2020 年,Pulsar 社区还推出了每月一次的线上研讨会[11],分享最佳实践、最新用例、技术更新等。最火的一期线上研讨会由 OVHCloud、Overstock、Nutanix 等战略商和开源团队主办。7 月 28 日,StreamNative 作为主办方,与来自 Verizon Media 和 Splunk 的小伙伴们进行了线上讨论,主题为在生产环境中使用 Pulsar。最近一期研讨会的主题为使用 Jet 处理低延迟流[12]。
随着专业培训(由 StreamNative 等团队提供支持)的深入,Pulsar 的生态一直在不断发展。Pulsar 和 Kafka 的技术专家 Jesse Anderson 最近主持了一个关于开发 Pulsar 应用程序[13]的专业培训课程。该课程不仅扩大了 Pulsar 培训讲师的队伍,还促进了用户消息和流平台的开发。
此外,白皮书[14]也有助于扩大 Pulsar 的知识库。
社区合作伙伴也为关键项目的进展作出了贡献。下面,我们来了解一下最近推出的几款产品。
OVHCloud 帮助企业从 Kafka 迁移到 Pulsar
2020 年 3 月,OVHCloud 和 StreamNative 联合推出 KoP(Kafka-on-Pulsar)。使用 KoP,Kafka 用户无需修改代码就可以将现有的 Kafka 应用程序和服务迁移到 Pulsar。虽然 KoP 发布时间不长,但已有多个企业将其应用于生产环境中。同时,KoP 的可用性也有助于扩大 Pulsar 的使用范围。
中国移动帮助企业从 RabbitMQ 迁移到 Pulsar
2020 年 6 月,中国移动和 StreamNative 宣布推出另一重大插件——AoP(AMQP-on-Pulsar)。与 KoP 类似,AoP 支持使用 RabbitMQ(或其他 AMQP 消息 broker)的企业在不修改代码的情况下,将现有的应用程序和服务迁移到 Pulsar。AoP 成为扩大 Pulsar 使用范围的又一关键产品。
StreamNative 开源 MoP
2020 年 9 月,StreamNative 开源了 MoP(MQTT-on-Pulsar)。与 KoP、AoP 相似,MoP 是一种可插拔的协议处理插件。将 MoP 协议处理插件添加到现有 Pulsar 集群后,用户不用修改代码就可以将现有的 MQTT 应用程序和服务迁移到 Pulsar。通过 MoP,Apache Pulsar 可以支持原生 MQTT 协议,MQTT 应用程序就可以利用 Pulsar 的特性,例如 Apache Pulsar 计算和存储分离的架构以及 Apache BookKeeper 保存事件流和 Pulsar 分层存储等特性。
由此可见,Pulsar 社区一直致力于 Pulsar 的知识传播和生态发展,同时也展示了 Pulsar 的团队支持和成长空间,未来可期。
结语
在当今不断变化的商业环境中,接入数据可以解锁新商机、定义新类别,并使企业在竞争中遥遥领先。所以,许多企业都在通过利用数据和数据的分析结果来发展自身优势。与此同时,他们也在寻找新技术来实现这些目标。
本文回答了企业在评估新技术时通常会关注的一些商业问题,包括新技术的成熟度、启用按需业务的能力、开源社区的规模和成员参与度(仅适用于开源技术)等。
腾讯、Verizon Media、Splunk 的案例强有力地证明了 Pulsar 具备在生产环境中交付关键任务应用程序的能力。除此之外,Pulsar 支持统一消息和流优先的应用程序,因而支持企业在不需要大量资源的情况下推出具有竞争力的革新性新产品,这也是 Pulsar 的显著优势。目前,Pulsar 与 Flink 的集成正在开发中。这一产品将会展示 Pulsar 在同一平台进行批流处理的能力。
虽然 Pulsar 社区和其他一些关键领域(如文档)的规模仍然不大,但在过去的一年半时间里,均有显著增长。Pulsar 社区活跃度高、成长速度快,与 Pulsar 生态一起致力于 Pulsar 知识库和培训材料的持续扩展,同时也加速了 Pulsar 主要功能的开发。
企业在评估一项技术时,不仅需要考虑它当前的优劣势,还需要考虑该技术未来的发展方向和发展空间,如何应对新的业务需求等。Pulsar 具有强大的消息功能和其他独特优势,因此,对于希望开发实时数据流功能的企业而言,Pulsar 是个最佳选择。
特别致谢
感谢帮助撰写本文的 Pulsar 社区成员:Jerry Peng、Jesse Anderson、Joe Francis、Matteo Merli、Sanjeev Kulkarni、Addison Higham 等。
链接 & 资源
更多关于 Pulsar 文档和培训的信息,请访问 StreamNative 的 Resources 页面[15]。
欢迎查阅近期发布的与涂鸦、OVHCloud、腾讯、Yahoo!Japan 相关的白皮书[16]。
了解更多
欢迎订阅 Pulsar Newsletter[17],了解活动动态和技术更新。如想与其他 Pulsar 用户进行沟通,欢迎扫码加入 Pulsar 技术交流群(见底图)。
引用链接
[1] Yahoo! 于 2012 年开始开发 Pulsar: https://yahooeng.tumblr.com/post/150078336821/open-sourcing-pulsar-pub-sub-messaging-at-scale#notes?ref_url=https://yahooeng.tumblr.com/post/150078336821/open-sourcing-pulsar-pub-sub-messaging-at-scale/embed#_=_[2] Pulsar Summit: https://www.youtube.com/watch?v=FXQvsHz_S1A[3] 为什么 Splunk 选择了 Pulsar: https://www.youtube.com/watch?v=_q8s3_0-BRQ[4] Pulsar Flink connector: https://github.com/streamnative/pulsar-flink[5] Pulsar 首次举办全球峰会: https://finance.yahoo.com/news/rise-apache-pulsar-first-ever-162100598.html[6] 2020 年 Pulsar Summit Virtual Conference: https://pulsar-summit.org/en/event/virtual-conference-2020[7] Verizon Media: https://www.linkedin.com/company/verizon-media/[8] Splunk: https://www.linkedin.com/company/splunk/[9] Iterable: https://www.linkedin.com/company/iterable/[10] OVHcloud: https://www.linkedin.com/company/ovhgroup/[11] 每月一次的线上研讨会: https://www.youtube.com/playlist?list=PLqRma1oIkcWhfmUuJrMM5YIG8hjju62Ev[12] 使用 Jet 处理低延迟流: https://www.youtube.com/watch?v=wIJGusBxB70&list=PLqRma1oIkcWhfmUuJrMM5YIG8hjju62Ev[13] 开发 Pulsar 应用程序: https://gumroad.com/l/suukG[14] 白皮书: https://streamnative.io/resource#white-paper[15] StreamNative 的 Resources 页面: https://streamnative.io/resource[16] 白皮书: https://streamnative.io/resource#white-paper[17] Pulsar Newsletter: https://share.hsforms.com/1IS56E-RvSVuMXU-ghlkoFA3x5r4
