
十篇文章速览多模态语言生成的研究进展

本文约3300字,建议阅读10分钟
本文整理了最近两年在语言生成 (NLG) 任务上的多模态预训练模型上的进展。
[ 引言 ]在最近几年,凭借着强大的泛化能力,预训练模型在NLP,CV等领域都取得了显著的效果。最近也有不少工作在尝试多模态领域使用预训练模型。笔者整理了最近两年在语言生成 (NLG) 任务上的多模态预训练模型上的进展,这些论文在包括多模态机器翻译 (MMT) 、图片/视频标题生成 (Image/Video Caption)、文本摘要 (Abstractive Summarization)、问答生成 (QA/VQA) 等多种 NLG 任务取得了提升。欢迎大家批评指正,相互交流。
一、论文列表
1. UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
https://aclanthology.org/2021.acl-long.202/
该工作的主要亮点是通过单塔的Transformer模型来同时编码文本和图像数据。模型总共有三大类预训练任务,除了比较常规的视觉单模态学习任务(mask区域恢复和region分类)以及文本单模态学习任务(MLM任务和seq2seq生成),该论文还提出了跨模态的对比学习,通过对文本进行词级别、片段级别和句子级别重写以及图文检索,产生各种粒度的图文正负样本进行跨模态的对比学习。从而能够更好地在同一个语义空间去学习这些单模态、多模态信息。模型结构如下:
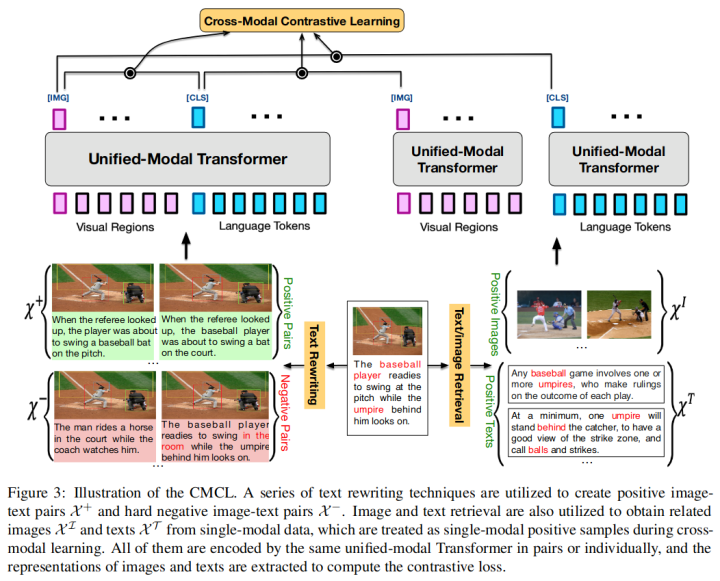
在下游的微调任务中,UNIMO在多项任务上都取得了提升,其中也包括VQA任务。
2. Enabling Multimodal Generation on CLIP via Vision-Language Knowledge Distillation
https://aclanthology.org/2022.findings-acl.187/
该工作之前的多模态预训练模型(如CLIP)在各种多模态对齐任务上取得了不错的效果,但由于其文本编码器较弱,在文本生成任务上的表现不佳。为了解决这个问题,该工作提出将 CLIP 的多模态知识蒸馏到 BART 上,以获得一个同时具有多模态知识和文本生成能力的模型。本文使用了三个目标函数来实现多模态知识蒸馏:
ext-Text Distance Minimization (TTDM): 该损失函数是为了对齐BART的编码器和CLIP的文本编码器,拉近两者的表示空间Image-Text Contrastive Learning (ITCL): 该损失函数是为了对齐BART的编码器和CLIP的图片编码器。即在BART编码的文本和CLIP编码的图片表示之间进行跨模态的对比学习;Image-Conditioned Text Infilling (ITCL): 上面两个目标只是将CLIP的多模态信息传递给了BART的编码器。这个损失函数可以理解为同时给出文本和图片编码器表示的conditional text generation,使得BART的编码器也能理解视觉表示。

本文也测试了经过蒸馏的BART在Image Captioning, VQA以及Abstractive Summarization等任务上的表现,取得了不错的效果。
3. A Non-hierarchical Attention Network with Modality Dropout for Textual Response Generation in Multimodal Dialogue Systems
https://arxiv.org/abs/2110.09702
以往的的图文多模态对话系统使用传统的分层循环编码器-解码器(HRED)框架,这些旧模型仍具有两个问题:
(1)文本特征和视觉特征之间的交互不够精细。
(2) 上下文表示不够完整。
这篇工作为多模态对话提出了一个具有多模态的、非层次化的自注意网络模型,该模型具有类似Transformer的编码器-解码器结构。编码器部分主要有两个部分,一部分是融合每句话以及对应的图片的表示,另一部分则是融合所有历史对话表示,这两个部分都使用自注意力机制来融合表示;解码器结构则和Transformer的解码器结构比较类似,使用编码器的表示来生成回复。模型结构如下所示:
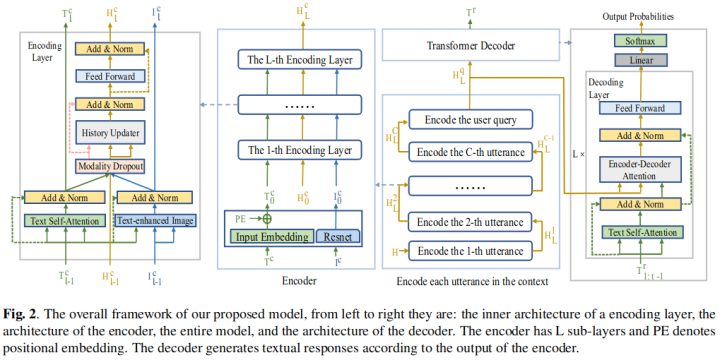
4. Modeling Text-visual Mutual Dependency for Multi-modal Dialog Generation
https://arxiv.org/abs/2110.09702
这项工作提出了一个多模态对话生成的一个框架,使得每个对话回合都与发生对话的视觉上下文相关联。具体的说,该工作首先提出了普通的视觉模型来提取视觉特征并将其合并到序列到序列对话框生成中,其中每个模型在不同的级别提取视觉特征:从仅使用文本特征到使用粗粒度图像级特征,再到细粒度对象级特征。
然后,发现模型学习到的文本特征和视觉特征的关联程度仍然不高,该工作提出要对文本和视觉特征之间的相互依赖性进行建模,即对话模型不仅需要了解在前面的对话话语和视觉上下文中生成下一个话语的概率,还需要建模在对话话语中预测视觉特征的后向概率,以引导模型生成特定于视觉上下文的对话语句。
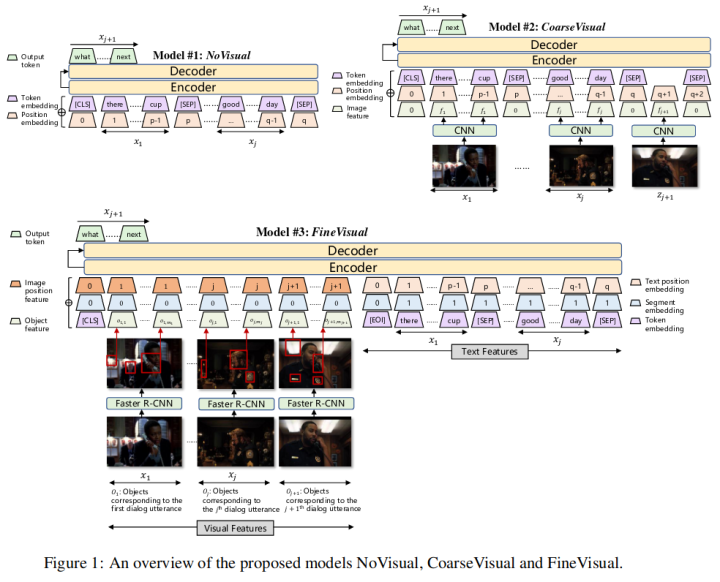
5. GIT: A Generative Image-to-text Transformer for Vision and Language
https://arxiv.org/abs/2205.14100
本文的主要亮点是设计并训练了一个生成式图像到文本转换器GIT,以统一图像/视频字幕和问答等视觉语言任务。虽然生成模型在预训练和微调之间提供了一致的网络架构,但现有的工作通常包含复杂的结构(单/多模态编码器/解码器),并且依赖于外部模块,如对象检测器/标记器和光学字符识别(OCR)。
本文提出的模型仅包含两个部分:一个图像编码器和一个文本解码器。图像编码器部分是一个类似Swin的视觉Transformer,它基于对比学习任务在大量图像-文本进行预训练。而文本解码器部分则采用了类似UniLM的方法,将视觉部分的编码作为前缀,然后用Auto Regressive的方法来生成文本。尽管这个模型并不复杂,但在扩大了预训练数据和模型大小后,该模型在Image Caption, VQA, Video Caption and Question Answering, Scene Text Recognition等多项任务上都取得了良好的性能。
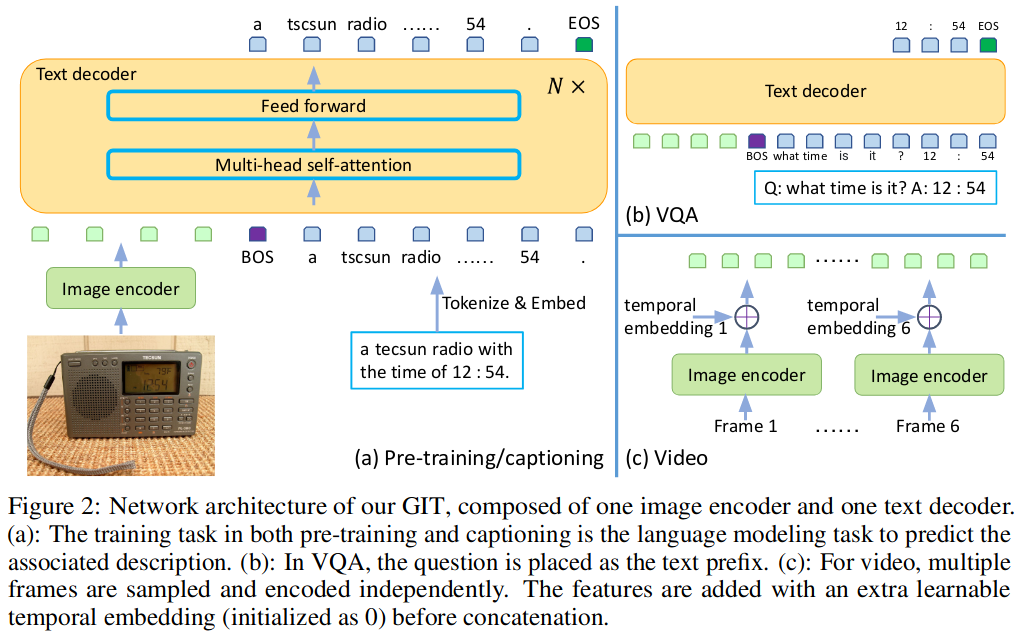
6. CoCa: Contrastive Captioners are Image-Text Foundation Models
https://arxiv.org/abs/2205.0191
这项工作主要亮点是设计了一个能同时包含图文对比学习和标题生成的多模态预训练模型。模型共分为三个部分:Image Encoder, Unimodal Text Decoder和Multimodal Text Decoder。模型首先将图文分别输入到Image Encoder和Unimodal Text Decoder,将两者得到的表示进行对比学习,得到对比学习的损失;然后在将两个表示输入到Multimodal Text Decoder进行Cross Attention,使用Auto Regressive的方法来生成输入文本,得到文本生成的损失。该模型通过这样的预训练方式来同时学习图文对比和文本生成能力。模型图如下所示:
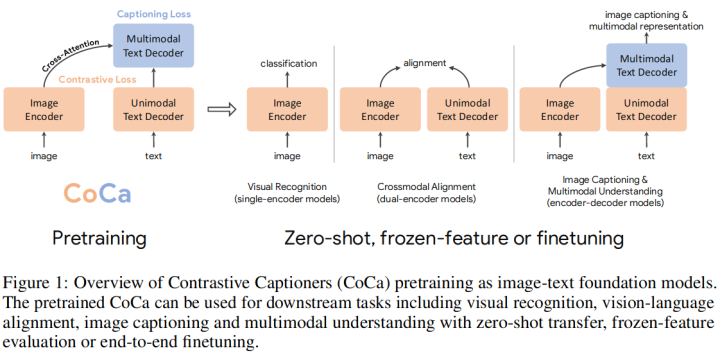
该模型在Image Caption, VQA等NLG任务上也取得了不错的效果。
7. DU-VLG: Unifying Vision-and-Language Generation via Dual Sequence-to-Sequence Pre-training
https://aclanthology.org/2022.findings-acl.201
这项工作提出了一个具有视觉和语言生成双序列到序列预训练的模型 DU-VLG (DUal sequence-to-sequence pre-training for Vision-and-Language Generation)。这个模型是Transformer的Encoder-Decoder结构,它可以文本(或图像)为输入,自回归的生成对应的图像(或文本)。为了训练这个模型,该工作提出了两个预训练任务:Multi-modal Denoising Autoencoder Task 和 Modality Translation Task。
第一个预训练任务类似MLM,将带有随机屏蔽的图像或单词的图文对作为输入,并通过重建损坏的模态来学习图像文本对齐。第二个任务则是跨模态的生成。通过这两个任务来增强模型的语义对齐能力。此外,本文还提出了一种新的commitment loss来驱动模型获得更好的图像表示。下游的微调任务表明该模型在Image Captioning, Visual Commonsense Reasoning等任务上均有提升。
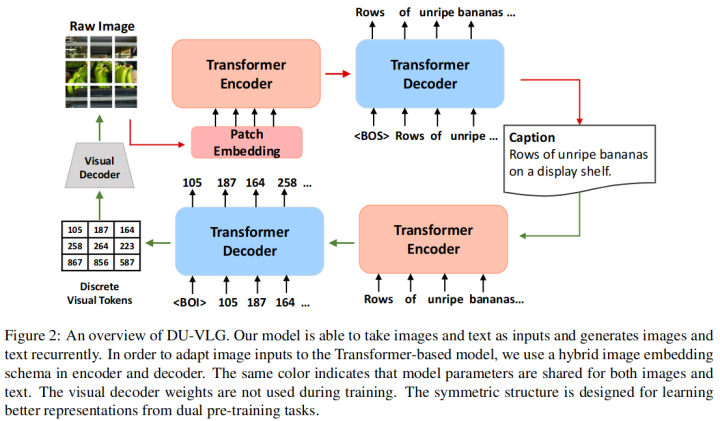
8. Gumbel-Attention for Multi-modal Machine Translation
https://arxiv.org/abs/2103.08862
多模态机器翻译(MMT)通过引入视觉信息来提高翻译质量。然而,现有的MMT模型忽略了图像会带来与文本无关的信息,对模型造成很大的噪声,影响翻译质量的问题。该工作提出了一种新的用于多模态机器翻译的Gumbel-Attention方法,它可以选择图像特征中与文本相关的部分。具体来说,与以往基于注意的方法不同,它首先使用可微方法来选择图像信息,并自动去除图像特征中无用的部分。
通过Gumbel-Attention得分矩阵和图像特征,生成图像感知的文本表示。然后使用多模态编码器对文本表示和图像感知文本表示进行独立编码。最后,通过多模态门控融合得到编码器的最终输出。实验和案例分析表明,该方法保留了与文本相关的图像特征,其余部分有助于MMT模型生成更好的翻译。
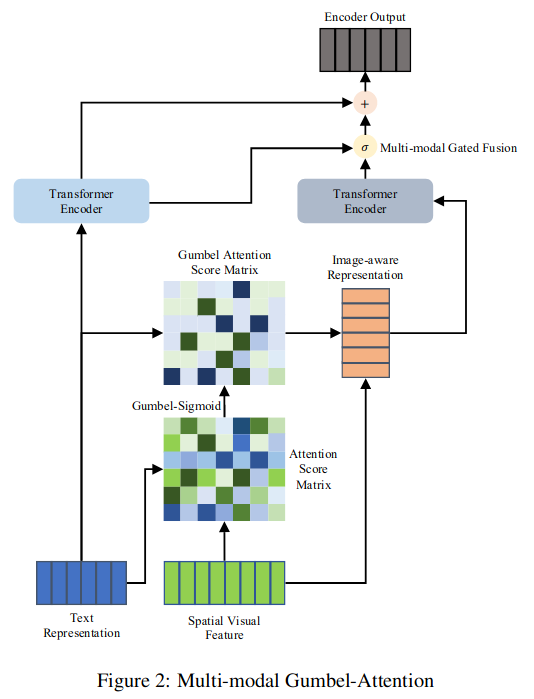
9. M6: A Chinese Multimodal Pretrainer
https://arxiv.org/abs/2103.00823
这篇工作有两个主要贡献,一是提供了一个大规模的中文多模态预训练数据集,而是提出了一个跨模态预训练模型M6。该模型使用Transformer Encoder,将图片和文本编码到同一个空间中。为了该模型能够同时做理解和生成任务,它也使用了UniLM里的mask方法。该模型共有三种预训练任务:
Text-to-text Transfer: 这部分任务包含文本去噪和语言建模,主要是为了增强模型的文本理解和生成能力。Image-to-text transfer: 这部分任务则是生成图片标题描述,通过输入的视觉信息来生成对应的文本。Multimodality-to-text transfer: 这部分任务建立图像到文本的基础上,增加了隐藏的语言输入。模型需要学习同时基于视觉信息和语言信息生成目标文本。
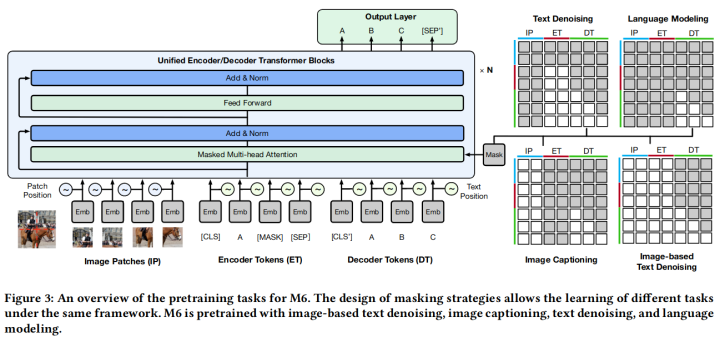
模型结构图如上所示。实验表明 M6 在VQA, Image Caption, Poem Generation等多项任务上都有提升。
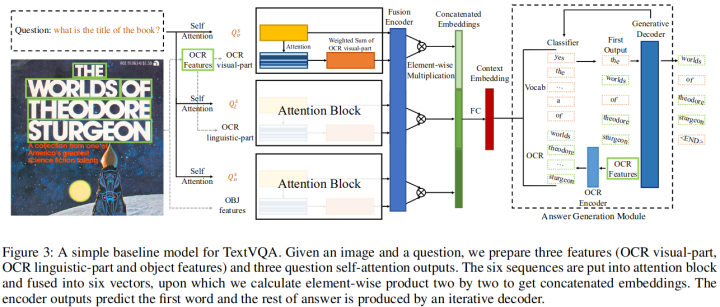
10. Simple is not Easy: A Simple Strong Baseline for TextVQA and TextCaps
https://ojs.aaai.org/index.php/AAAI/article/view/16476
OCR工具可以识别的日常场景中出现的文本包含重要信息,这对于TextVQA和TextCaps这两个任务非常重要。以往的工作都使用了许多复杂的多模态编码框架来融合与文字有关的特征。该工作仅使用了简单的Attention机制来融合这些特征,它将文本特征分成两个功能不同的部分,即语言部分和视觉部分,这两个部分传入相应的Attention模块。然后再将编码后的特征传给一个Decoder,以生成答案或字幕。
编辑:黄继彦